







一.虚拟内存机制
转载处:http://blog.csdn.net/zp373860147/article/details/7815793;
这是我找到的关于虚拟内存和分页机制的我个人比较容易理解的一篇文章。
虚拟存储器的思想是程序、数据和堆栈的大小都有可能超过物理内存大小,由操作系统把当前使用的放在内存,而不需要的放在磁盘。而绝大部分操作系统使用的虚拟存储器技术就是分页技术。
在虚拟存储器中,程序所产生的地址为虚拟地址,虚拟地址构成了虚拟地址空间。(当然了在没有虚拟存储器的系统上,程序产生的地址就是物理地址。其实程序并不知道,只是操作系统和处理器知道。下面都是按照使用虚拟存储器的系统来说)这些虚拟地址通过MMU(内存管理单元)映射为物理地址。采用分页机制的系统,虚拟地址空间以页面为单位进行划分,虚拟地址空间会被划分成多个等大小的页面。物理地址空间也按页面为单位进行划分每一块成为页帧,或者页框。每一虚拟页面可以随意对应到物理页框,也可以对应到磁盘的页面文件的上。
我们按照IA32的分页机制来说,标准页面大小为4K。
例如一条mov指令:mov eax,[0]; 此时虚拟地址0将被发给MMU,MMU发现0属于页面0的范围内,如果页面0对应的页框号为1,那么物理地址在物理地址4096-8191范围,此时就会将4096发送到地址总线上。因为虚拟地址0的页内偏移也是0(页内偏移:在页面里的位置,比如1,的页面偏移是1,4097的页面偏移也是1,这是因为一个页面大小为4K,用虚拟地址 mod 4k就得到了页内偏移)。
就类似mov eax,[4095];mov eax,[4096],4095属于页面0,页面0对应页框1,那么物理地址为8191,而4096属于页面1的范围,如果页面1对应页框0,此时的物理地址就是0。
由上面可以看出,虚拟地址空间是连续的,而物理空间是可以不连续的。也就是说一个程序只要保证他的虚拟地址空间是连续的,它就可以正常运行。
上面说的是虚拟地址到物理地址的映射的简单情况。可是如何记录这些页面到页框的映射关系呢?(当然也有些处理器系统是页框到页面的转化)。在IA处理器上使用的是页表,就是在物理内存里有一块连续的空间,来记录这些页面到页框的映射关系。每一个页表项里都有一部分去指向页框的起始地址,还有部分记录了这个页面的属性。可以通过页面号来做索引。页面号就是虚拟地址 / 4K,得到的整数部分。
当然如果只是单一的页表,也是有问题的,如果虚拟地址空间过大,那么页表所占的空间也会很大,这时候可以采用多级页表。IA32在采用4K页面的时候就使用了2级页表,IA64使用了4级。
其实两级也很简单,最上一级就是一个总的目录指示每一个二级页表的起始物理地址,可以在页号的高几位来索引页目录项。例如IA32就是通过虚拟地址的高10位来索引页目录项,然后中间10位来索引页表项。这样,我们就可以只将用到的虚拟地址空间的页表写入内存,而没有用到的虚拟地址空间的页表就不写入。
例如,我们正好是只用了虚拟地址0-0x3FFFFF,那么我们可以在页目录第0项指向一个页表,这个页表就只表示了虚拟地址地址0-0x3FFFFF到物理地址空间的映射关系(因为高10位为页目录索引,页目录第0项,就表示了虚拟地址高10位必为0,也就是说只有低24位有效,所以最大只能到0x3FFFFF)。
虚拟内存的实现方法-------摘自《加密与解密》
1.当一个应用程序被启动时,操作系统就创建一个新进程,并给每个进程分配2gb的内存地址(不是内存只是地址)。
2.虚拟内存管理器将应用程序的代码映射到那个程序的虚拟地址中得某个位置,并把当前所需的代码读取到物理地址中。
3.如果使用动态链接库DLL,DLL也被映射到进程的虚拟地址空间,在需要的时候才被读入物理地址。
4.其他项目(如数据,堆栈)的空间是从物理地址中分配的,并被映射到虚拟地址空间中。
5.应用程序通过使用它的虚拟地址空间中的地址开始执行,然后虚拟内存管理器把每次的内存访问映射到物理位置。
二.内存映射文件原理
转载处:http://blog.csdn.net/mg0832058/article/details/5890688
一直都对内存映射文件这个概念很模糊,不知道它和虚拟内存有什么区别,而且映射这个词也很让人迷茫,今天终于搞清楚了。。。下面,我先解释一下我对映射这个词的理解,再区分一下几个容易混淆的概念,之后,什么是内存映射就很明朗了。
原理
首先,“映射”这个词,就和数学课上说的“一一映射”是一个意思,就是建立一种一一对应关系,在这里主要是只 硬盘上文件 的位置与进程 逻辑地址空间 中一块大小相同的区域之间的一一对应,如图1中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。
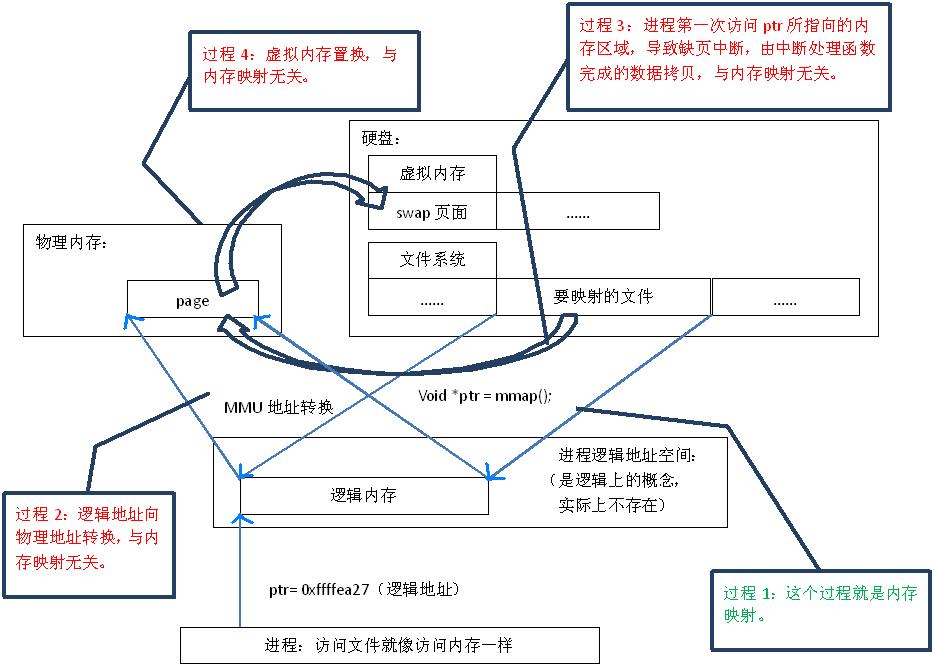
图1.内存映射原理
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?那就要看内存映射之后的几个相关的过程了。
mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。这个过程也与内存映射无关。
效率
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么呢?原因是read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
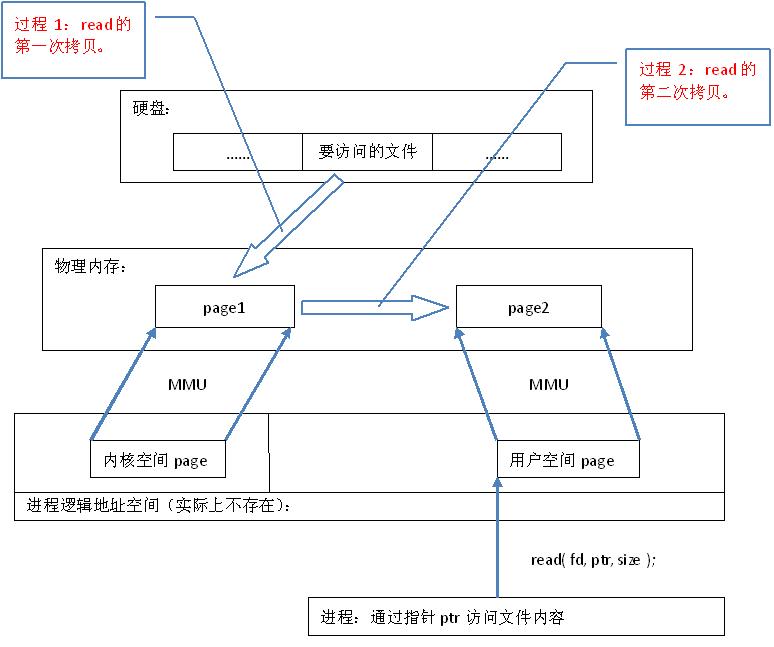
图2.read系统调用原理
下面这个程序,通过read和mmap两种方法分别对硬盘上一个名为“mmap_test”的文件进行操作,文件中存有10000个整数,程序两次使用不同的方法将它们读出,加1,再写回硬盘。通过对比可以看出,read消耗的时间将近是mmap的两到三倍。
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<sys/time.h>
#include<fcntl.h>
#include<sys/mman.h>
#define MAX 10000
int main()
{
int i=0;
int count=0, fd=0;
struct timeval tv1, tv2;
int *array = (int *)malloc( sizeof(int)*MAX );
/*read*/
gettimeofday( &tv1, NULL );
fd = open( "mmap_test", O_RDWR );
if( sizeof(int)*MAX != read( fd, (void *)array, sizeof(int)*MAX ) )
{
printf( "Reading data failed.../n" );
return -1;
}
for( i=0; i<MAX; ++i )
++array[ i ];
if( sizeof(int)*MAX != write( fd, (void *)array, sizeof(int)*MAX ) )
{
printf( "Writing data failed.../n" );
return -1;
}
free( array );
close( fd );
gettimeofday( &tv2, NULL );
printf( "Time of read/write: %dms/n", tv2.tv_usec-tv1.tv_usec );
/*mmap*/
gettimeofday( &tv1, NULL );
fd = open( "mmap_test", O_RDWR );
array = mmap( NULL, sizeof(int)*MAX, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0 );
for( i=0; i<MAX; ++i )
++array[ i ];
munmap( array, sizeof(int)*MAX );
msync( array, sizeof(int)*MAX, MS_SYNC );
free( array );
close( fd );
gettimeofday( &tv2, NULL );
printf( "Time of mmap: %dms/n", tv2.tv_usec-tv1.tv_usec );
return 0;
}
输出结果:
Time of read/write: 154ms
Time of mmap: 68ms















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









