







- 同构邻居q2q & i2i相比异构邻居q2i & i2q效果更明显。可能的原因是q2i & i2q数据比较稀疏,经过统计发现其存在50%左右的结点邻居个数不足5个,而q2q & i2i只有15%左右的这样的结点,更多的数据则意味着更多的信息,详情见图 4.1。
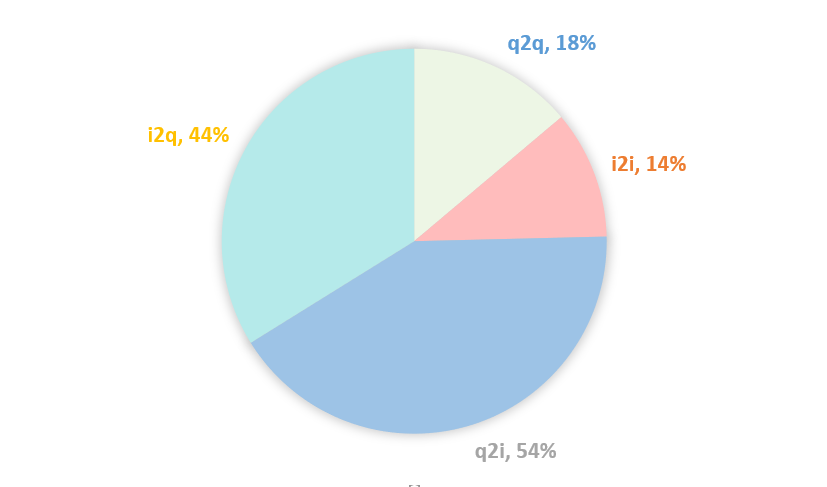
图 4.1 邻居个数不足5个的结点的占比
- **同构邻居和异构邻居均有一些收益,但是同时加入它们却没有进一步的提升。**可能的原因有:一是两种类型的邻居包含的信息有重叠,二是Graph Context Feature的方式不利于信息的抽取。
- 对于No Aggregator
可以看到,除了同构邻居q2q & i2i,加入其它邻居收益均为负。可能的原因仍然与上述的数据稀疏有关,q2i和i2q有大量邻居不足5个,为了保持维度上的对齐,在代码里这部分被置为了0,导致经过特征拼接后,Query和Item的Embedding中包含了大量0值(始终为0),而这非常不利于深度模型的训练。
▐ Graph Context Sequence
Base_50 |
83.43 |
|
Base_20 |
83.37 |
|
Neighbor/Aggregator-> |
GCN |
No Aggregator |
A: +q2q & i2i & q2i & i2q |
83.62 |
83.47 |
B: +q2i & i2q |
83.55 |
83.52 |
C: +q2q & i2i |
83.57 |
83.61 |
D: +i2q |
83.49 |
83.52 |
表 4.3 Total AUC
采用Graph Context Sequence这种将邻居信息作为单独的序列与待排序的Query做Target Attention的方式,总体AUC见表 4.3。我们可以有如下几个发现:
-
对于GCN
-
相比Graph Context Feature的方式,有两个方面的提升:
总体AUC均有所上涨。相比Base_20的最高提升由之前的千分之1.5到现在的千分之2.5。
同时加入同构邻居和异构邻居能够带来进一步的提升。可能的原因是将邻居信息作为单独的序列,相比特征拼接的方式,在用Target Query做兴趣抽取时,能够最大限度地保留Graph Context的信息。至于特征交叉可以交给末层的MLP来做。
-
同构邻居q2q & i2i相比异构邻居q2i & i2q效果明显一点。原因同上。
-
对于No Aggregator:当加入4个邻居序列后,模型的AUC有很明显的下降。可能的原因是序列太长(100)加上参数变多(4组参数),模型可能难以收敛了。表 4.4是A组结果中GCN和No Aggregator下i2i邻居序列前4个位置的Attention曲线对比(其他位置情况类似),可以看到,No Aggregator确实没有收敛。
GCN |
|
No Aggregator |
|
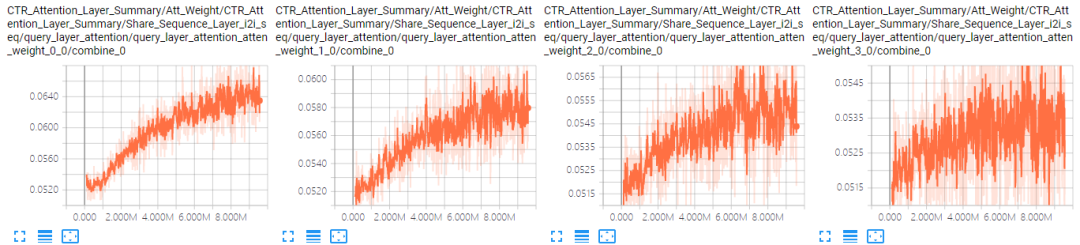
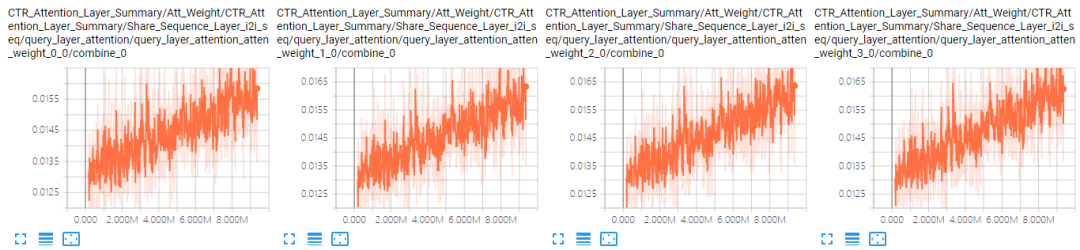
表 4.4 i2i邻居序列Attention曲线对比
▐ Hierarchical Attention
Base_50 |
83.43 |
||
Base_20 |
83.37 |
||
Neighbor/Model-> |
+neig atten |
+neig & seq attenneig |
+neig & seq attenall |
A: +q2q & i2i & q2i & i2q (100%) |
83.46 |
83.47 |
83.49 |
B: +q2i & i2q (75%) |
83.47 |
83.47 |
83.46 |
C: +q2q & i2i (75%) |
83.50 |
83.50 |
83.52 |
D: +i2q (60%) |
83.41 |
- |
- |
表 4.5 Total AUC
4.1和4.2结果说明了两点,一是引入邻居信息并用GNN建模是有效的,二是Graph Context Sequence的方式优于Graph Context Feature。在此基础上,一方面从图 3.1的Score分布可以看到同种邻居的重要性存在差异,另一方面从之前的实验结果可以看到不同邻居的重要性也存在差异。因此在该部分快速实验了下Attention机制:Neighbor Attention和Sequence Attention,总体AUC见表 4.5。Neighbor Attention是在聚合邻居时自适应学习边的权重,考虑到这里用Target Attention计算量很大,所以使用的是中心结点做Attention。Sequence Attention是将Sequence Emb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









