



目录
Mask-RCNN(一):从零学习使用 Mask-RCNN 训练自己的数据
以下代码运行采用win10系统的电脑,编程语言python。
参考博客:
- https://blog.csdn.net/qq_29462849/article/details/81037343.
- https://blog.csdn.net/qq_36810544/article/details/83582397#commentBox.
- https://blog.csdn.net/yychentracy/article/details/86632616.
- https://blog.csdn.net/u012746060/article/details/82143285#commentBox.
- MaskRCNN训练自己的数据集 小白篇.
1.下载Mask-RCNN
官方代码:https://github.com/matterport/Mask_RCNN.
下载后进行解压。
2.安装Anaconda
安装方法很多,可以参考博客https://blog.csdn.net/wyatt007/article/details/80369755.写得很详细。
本人安装了Anaconda3,在 D:\Anaconda3 路径下。
按win+R键,输入cmd,进入命令窗口。通过输入以下命令可进行虚拟环境操作。
# Anaconda下创建python版本为3.6的名为tf1的虚拟环境:
conda create -n tf1 python=3.6
# 进入创建的名为tf1的虚拟环境:
activate tf1
# 退出当前虚拟环境:
conda deactivate
# 删除名为tf1的虚拟环境及其中所有文件:
conda remove -n tf1 --all
更多命令参考:https://blog.csdn.net/weixin_36670529/article/details/88423299.
3.安装tensorflow环境
在cmd命令窗口下输入:
conda create -n tf1 python=3.6
activate tf1
创建并进入虚拟环境。因为我用 python3.7 在后续一直出错,因此采用了 3.6 版本。
安装 tensorflow1.14 :
conda install tensorflow-gpu==1.14
最初按照博客https://blog.csdn.net/shangzhihaohao/article/details/89766368安装了 tensorflow2,但在之后训练数据时报错,应该是训练必须在1.X版本下运行。之后安装了1.13版本,但一直报错“ ImportError: DLL load failed: 找不到指定的模块 ”,因此又安装了1.14。conda install 命令会自动配置环境,省去了自己安装cuda等文件的麻烦。
安装过程中可能会提示几个ERROR,某个模块需要>=某个版本,直接 pip install XX 即可。改正后不放心,可以卸载后重新安装一次:
pip uninstall tensorflow-gpu
pip uninstall tensorflow
conda install tensorflow-gpu==1.14
安装完成后可能会出现一个bug(不知道是不是因为我自己电脑的配置问题),输入python会发现出现以下warning:

这应该是因为安装完成后系统自己退出了虚拟环境,但是显示还在虚拟环境中,只需要退出虚拟环境再重进即可。
通过 pip list 可以查看自己安装的 tensorflow 版本。
完成后输入以下代码,没报错即为安装成功。
python
import tensorflow
4.安装标注工具labelme
参考博客:https://blog.csdn.net/u012746060/article/details/81871733.
Labelme 同样安装在 Anaconda 虚拟环境下,与上节类似,在cmd命令窗口下依次输入:
conda create -n labelme python=3.6
activate labelme
pip install pyqt5
pip install pyside2
pip install labelme
labelme
即可安装并打开 labelme 界面,使用方法如下图: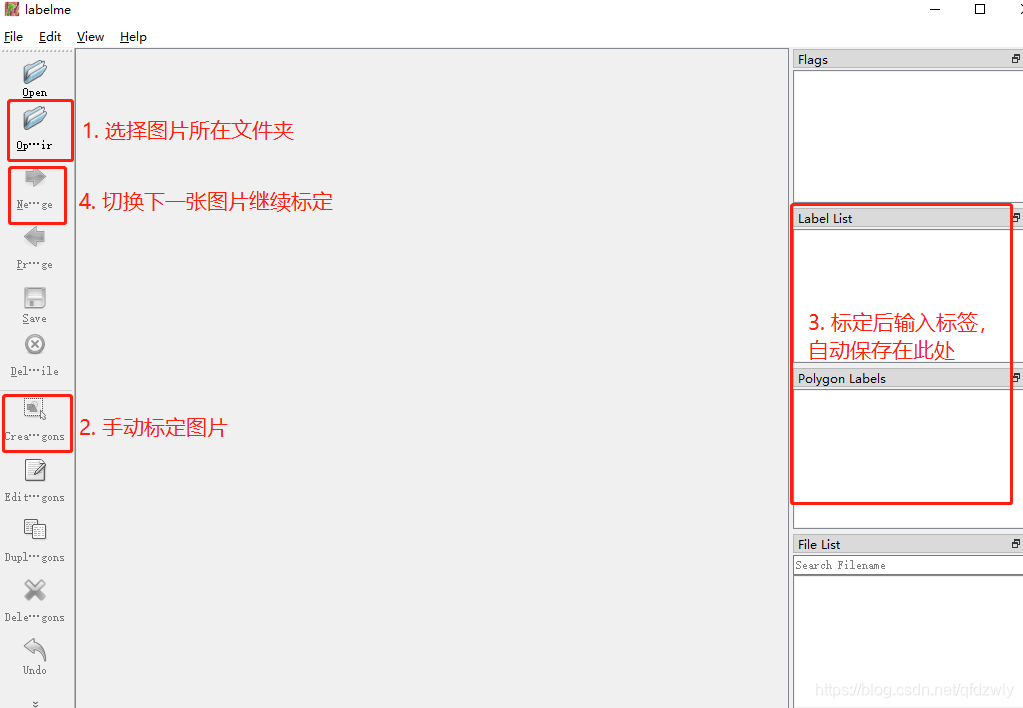
5.制作自己的训练数据
首先对自己的图片进行像素转换,全部转换为 64 的倍数,比如 1024*768 ,如果不转换为 64 倍数后续有可能会出错。
将初始图片放在 pic11文件夹下,新建 pic 文件夹,以生成像素转换后的图片。编写文件 change_pixel.py ,代码如下:
import os
import glob
from PIL import Image
img_path = glob.glob(".\\pic11")
path_save = ".\\pic"
files = os.listdir(img_path[0])
# print(img_path)
for file in files:
name = os.path.join(path_save, file)
filename = ".\\pic11\\" + file
print(filename)
# with Image.open(file,'rw') as im:
im = Image.open(filename)
im.thumbnail((1024,768))
print(im.format, im.size, im.mode)
im.save(name,'jpeg')
在 cmd 窗口下输入:
activate labelme
labelme
进入标注工具,依次对 pic 文件夹中的图片进行标注,将生成的 .json 文件存入新建的 json 文件夹下。
在 cmd 下定位到 labelme_json_to_dataset.exe 程序所在文件夹,我的在 D:\Anaconda3\envs\labelme \Scripts 位置,并在 cmd 下输入代码,进行 json 文件批量转换。
# D:\Anaconda3\envs\labelme\Scripts 为 labelme_json_to_dataset.exe 程序所在文件夹位置
cd D:\Anaconda3\envs\labelme\Scripts
# C:\Users\LARA\Desktop\Mask_RCNN-master\train_data_test1\json 为标注生成的 json 文件所在文件夹
for /r C:\Users\LARA\Desktop\Mask_RCNN-master\train_data_test1\json %i in (*.json) do labelme_json_to_dataset %i
此时应该每个生成的子文件夹下有5个文件,如果只有4个文件,缺少 info.yaml ,则参考博客 https://blog.csdn.net/winter616/article/details/104426111/ 对 json_to_dataset.py 文件进行更改即可。
将批量生成的 _json 子文件夹放入新建的 labelme_json 文件夹下,新版labelme生成的labelme.png文件即为8位类型,直接将其复制到新建的 cv2_mask 文件夹下即可进行最终的训练,复制出来的 png 文件需与 pic 文件夹中的图片同名。编写文件 move_file.py ,代码如下:
import os
import shutil
filefolds = os.listdir('./labelme_json')
i = 0
for filefold in filefolds:
i += 1
# new_name = 'cv2_mask/'+'label'+ str(i) + '.png'
new_name = 'cv2_mask/'+filefold+'.png'
# print(new_name)
filename = 'labelme_json/'+filefold+'/label.png'
# print(filename)
shutil.copyfile(filename, new_name)
path = "./cv2_mask" #输入你要更改文件的目录
originalname = '_json'
replacename = ''
def main1(path1):
files = os.listdir(path1) # 得到文件夹下的所有文件名称
for file in files: #遍历文件夹
if os.path.isdir(path1 + '\\' + file):
main1(path1 + '\\' + file)
else:
files2 = os.listdir(path1 + '\\')
for file1 in files2:
if originalname in file1:
#用‘’替换掉 X变量
n = str(path1 + '\\' + file1.replace(originalname,replacename))
n1 = str(path1 + '\\' + str(file1))
try:
os.rename(n1, n)
except IOError:
continue
main1(path)
最终将所有训练文件放在同一文件夹 train_data_test1 下,如图:

6.训练自己的数据
在第一步官方代码解压后的 Mask_RCNN-master 文件夹下建立两个空文件夹 models 和 logs,在 samples 文件夹下建立 box 文件夹(因为我训练的是 box,这个名字无所谓),放入训练数据的python程序,代码参考自MaskRCNN训练自己的数据集 小白篇,略微修改后如下:
import os
import sys
import random
import math
import re
import time
import numpy as np
import cv2
import matplotlib
import matplotlib.pyplot as plt
import yaml
import PIL
from keras import utils
# Root directory of the project
ROOT_DIR = os.path.abspath("C:/Users/LARA/Desktop/Mask_RCNN-master")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn.config import Config
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
from mrcnn.model import log
# get_ipython().run_line_magic('matplotlib', 'inline')
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "models\\mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
# print(Nan)
utils.download_trained_weights(COCO_MODEL_PATH)
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 3 shapes
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 768
IMAGE_MAX_DIM = 1024
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8, 16, 32, 64, 128) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small
VALIDATION_STEPS = 5
config = ShapesConfig()
config.display()
def get_ax(rows=1, cols=1, size=8):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Change the default size attribute to control the size
of rendered images
"""
_, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))
return ax
class ShapesDataset(utils.Dataset):
"""Generates the shapes synthetic dataset. The dataset consists of simple
shapes (triangles, squares, circles) placed randomly on a blank surface.
The images are generated on the fly. No file access required.
"""
#得到该图中有多少个实例(物体)
def get_obj_index(self, image):
n = np.max(image)
return n
#解析labelme中得到的yaml文件,从而得到mask每一层对应的实例标签
def from_yaml_get_class(self,image_id):
info=self.image_info[image_id]
with open(info['yaml_path']) as f:
temp=yaml.load(f.read())
# print(temp)
labels=temp['label_names']
del labels[0]
return labels
#重新写draw_mask
def draw_mask(self, num_obj, mask, image):
info = self.image_info[image_id]
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] =1
return mask
#重新写load_shapes,里面包含自己的自己的类别
#并在self.image_info信息中添加了path、mask_path 、yaml_path
def load_shapes(self, count, height, width, img_floder, mask_floder, imglist,dataset_root_path):
"""Generate the requested number of synthetic images.
count: number of images to generate.
height, width: the size of the generated images.
"""
# Add classes
self.add_class("shapes", 1, "box")
for i in range(count):
filestr = imglist[i].split(".")[0]
mask_path = mask_floder + "/" + filestr + ".png"
yaml_path=dataset_root_path+"/labelme_json/"+filestr+"_json/info.yaml"
#yaml_path=os.path.join(dataset_root_path, "pic")
self.add_image("shapes", image_id=i, path=img_floder + "/" + imglist[i],
width=width, height=height, mask_path=mask_path,yaml_path=yaml_path)
#重写load_mask
def load_mask(self, image_id):
"""Generate instance masks for shapes of the given image ID.
"""
global iter_num
info = self.image_info[image_id]
count = 1 # number of object
img = PIL.Image.open(info['mask_path'])#.convert('RGB')
num_obj = self.get_obj_index(img)
mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img)
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
for i in range(count - 2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
labels=[]
labels=self.from_yaml_get_class(image_id)
labels_form=[]
for i in range(len(labels)):
if labels[i].find("box")!=-1:
#print "box"
labels_form.append("box")
class_ids = np.array([self.class_names.index(s) for s in labels_form])
return mask, class_ids.astype(np.int32)
#基础设置
#dataset_root_path=ROOT_DIR+"\\train_dateset\\"
dataset_root_path=os.path.join(ROOT_DIR, "C:\\Users\\LARA\\Desktop\\Mask_RCNN-master\\train_data_test1")
#img_floder = dataset_root_path+"pic"
img_floder=os.path.join(dataset_root_path, "pic")
#mask_floder = dataset_root_path+"cv2_mask"
mask_floder=os.path.join(dataset_root_path, "cv2_mask")
#yaml_floder = dataset_root_path
imglist = os.listdir(img_floder)
count = len(imglist)
width = 1024
height = 768
# In[ ]:
#train与val数据集准备
dataset_train = ShapesDataset()
dataset_train.load_shapes(count, 768, 1024, img_floder, mask_floder, imglist,dataset_root_path)
dataset_train.prepare()
dataset_val = ShapesDataset()
dataset_val.load_shapes(count, 768, 1024, img_floder, mask_floder, imglist,dataset_root_path)
dataset_val.prepare()
# Load and display random samples
image_ids = np.random.choice(dataset_train.image_ids, 4)
for image_id in image_ids:
image = dataset_train.load_image(image_id)
mask, class_ids = dataset_train.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names)
# Create model in training mode
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# In[ ]:
# Which weights to start with?
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# Load weights trained on MS COCO, but skip layers that
# are different due to the different number of classes
# See README for instructions to download the COCO weights
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
# Load the last model you trained and continue training
model.load_weights(model.find_last(), by_name=True)
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=1,
layers='heads')
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
# model.train(dataset_train, dataset_val,
# learning_rate=config.LEARNING_RATE / 10,
# epochs=20,
# layers="all")
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
inference_config = InferenceConfig()
# Recreate the model in inference mode
model = modellib.MaskRCNN(mode="inference",
config=inference_config,
model_dir=MODEL_DIR)
# Get path to saved weights
# Either set a specific path or find last trained weights
# model_path = os.path.join(ROOT_DIR, ".h5 file name here")
model_path = model.find_last()
# Load trained weights
print("Loading weights from ", model_path)
model.load_weights(model_path, by_name=True)
# Test on a random image
image_id = random.choice(dataset_val.image_ids)
original_image, image_meta, gt_class_id, gt_bbox, gt_mask = modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
log("original_image", original_image)
log("image_meta", image_meta)
log("gt_class_id", gt_class_id)
log("gt_bbox", gt_bbox)
log("gt_mask", gt_mask)
visualize.display_instances(original_image, gt_bbox, gt_mask, gt_class_id,
dataset_train.class_names, figsize=(8, 8))
results = model.detect([original_image], verbose=1)
r = results[0]
visualize.display_instances(original_image, r['rois'], r['masks'], r['class_ids'],
dataset_val.class_names, r['scores'], ax=get_ax())
# Compute VOC-Style mAP @ IoU=0.5
# Running on 10 images. Increase for better accuracy.
image_ids = np.random.choice(dataset_val.image_ids, 10)
APs = []
for image_id in image_ids:
# Load image and ground truth data
image, image_meta, gt_class_id, gt_bbox, gt_mask = modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
molded_images = np.expand_dims(modellib.mold_image(image, inference_config), 0)
# Run object detection
results = model.detect([image], verbose=0)
r = results[0]
# Compute AP
AP, precisions, recalls, overlaps = utils.compute_ap(gt_bbox, gt_class_id, gt_mask,
r["rois"], r["class_ids"], r["scores"], r['masks'])
APs.append(AP)
print("mAP: ", np.mean(APs))
将以上代码存为 train_models.py 文件,放入 samples/box/ 文件夹下,进入cmd 界面,输入以下命令即可开始训练:
activate tf1
# 进入 train_models.py 所在文件夹
cd C:\Users\LARA\Desktop\Mask_RCNN-master\samples\box
python train_models.py
初次训练时系统会自动在 models 空文件夹下下载 mask_rcnn_coco.h5 文件,文件大小大概 245M,如果网速较差,可以事先在博客 https://blog.csdn.net/qq_36810544/article/details/83582397#commentBox 第三节中下载后,直接存入 models 文件夹。
最终的训练结果:

我只用了30张图片进行训练,因此结果并不是很理想。
根据自己需求,可进行以下更改(目前只会这么多):
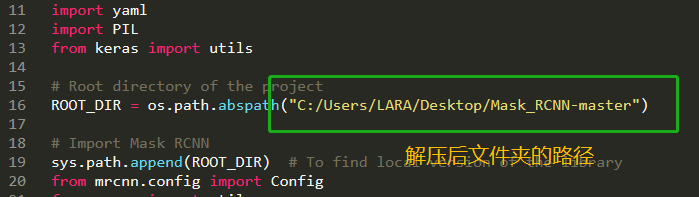

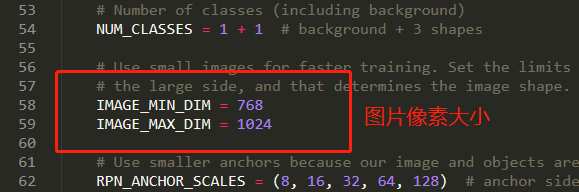



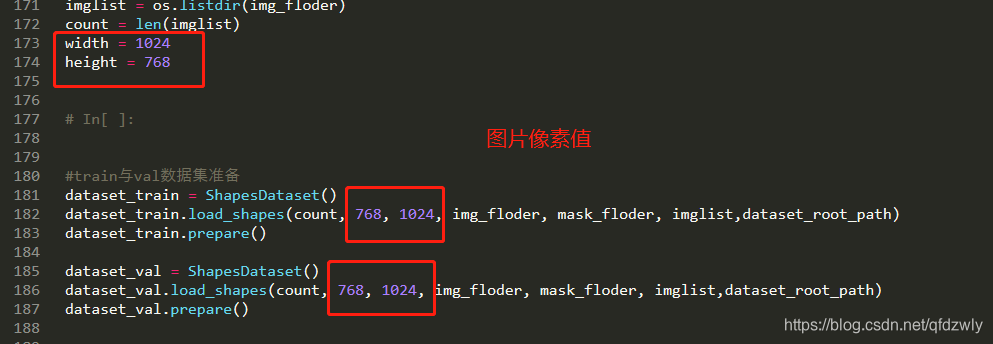

按以上步骤应该可以完成自己的训练了,训练完成后代码会自动寻找之前训练的图片进行验证。训练的 Mask-RCNN 模型是 logs 文件夹下最后一个子文件夹的最后一个 .h5 文件。
本文是为了实现训练自己的数据,因此代码中只进行了1次迭代,如想增加迭代次数,在 train_models.py 文件的 224 - 240 行更改 epochs 参数即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









