






环境:
| 显卡 | A10 23G |
|---|---|
| cuda | 11.6 |
| torch | 1.8 |
| mmcv_full | 1.5.0 |
| mmdeteciton | 2.2.0 |
Ps:如果MMCV版本不对可以根据自己的cuda和torch版本去下面网站下载 https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
1.标注数据,我这里使用的是labelme标注
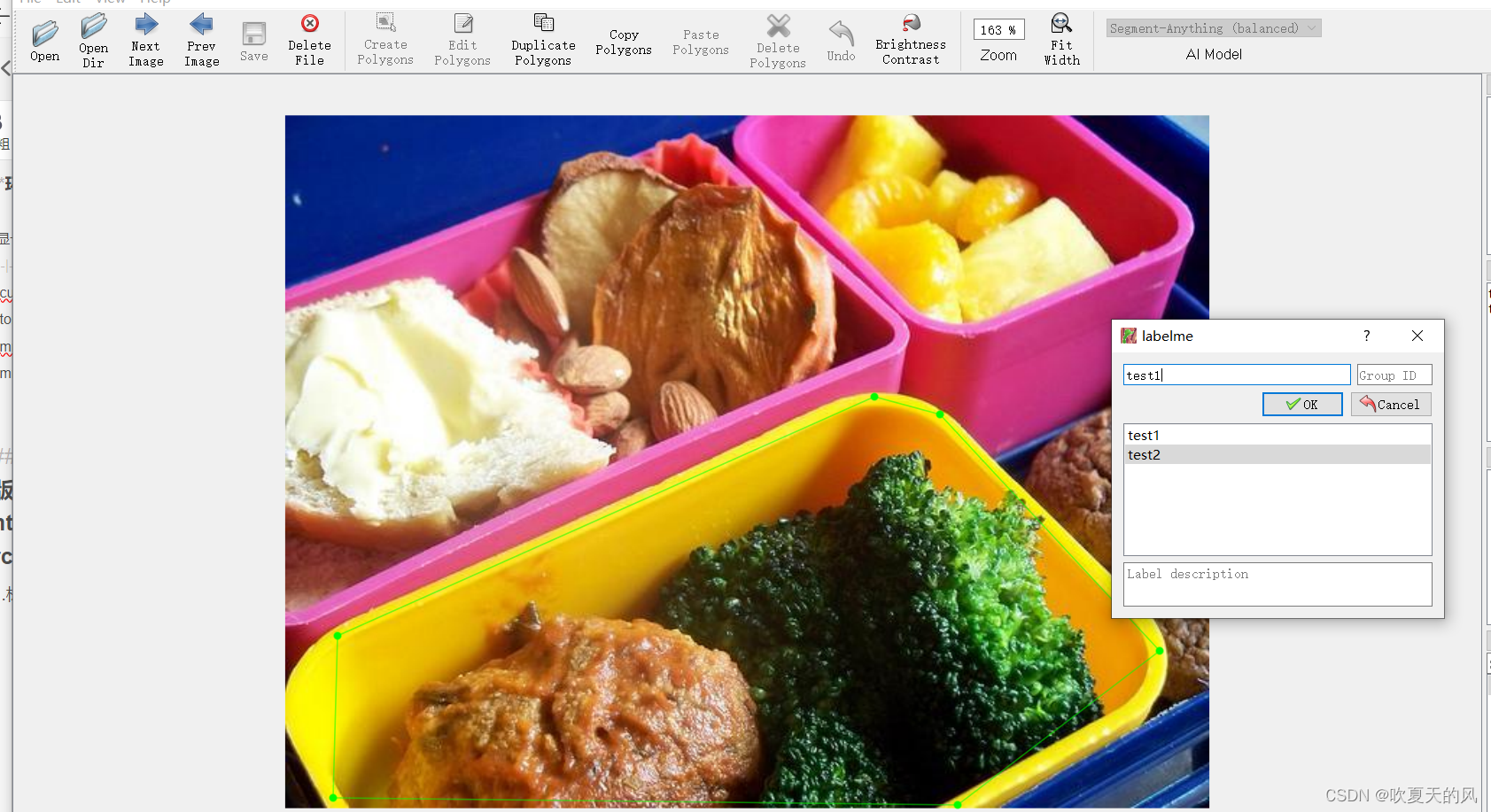
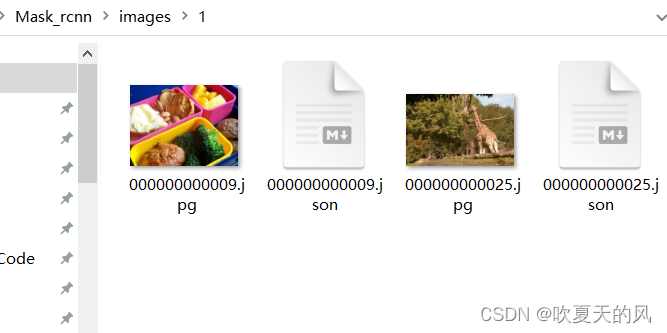
2.标注完的数据如下图所示,图片和json文件在一个目录下:
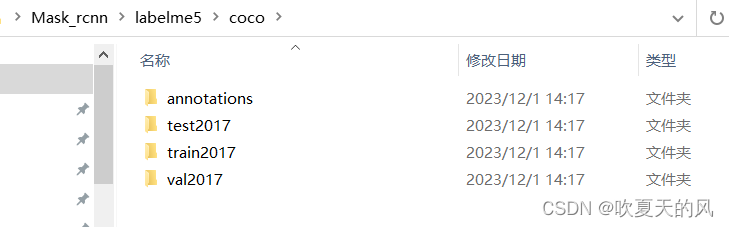
3.将标注完的数据转为Mask_rcnn训练所需的数据集格式
PS格式转换参考https://blog.csdn.net/m0_64298393/article/details/134733964
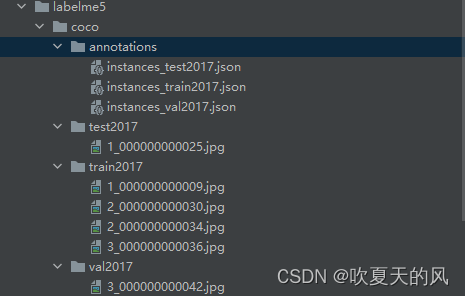
转换完毕后为以下格式,annotations中全是json文件,其他三个文件夹目录下直接放置图片:
4.将数据集放到训练代码文件夹中
5.修改配置文件,我这里要训练Mask_Rcnn,所以以Mask_Rcnn为例:
所有算法的配置文件都放在./configs文件目录下,文件夹名字就是各种算法名字
6.找到Mask_rcnn,可以看到文件夹下有很多配置文件,各字段释意如下:
- Mask_rcnn表示算法名称
- r50 等表示骨架网络名
- caffe 和 PyTorch 是指 Bottleneck 模块的区别,省略情况下表示是 PyTorch
- fpn 表示 Neck 模块采用了 FPN 结构
- mstrain 表示多尺度训练,一般对应的是 pipeline 中
Resize类 - 1x 表示 1 倍数的 epoch 训练即 12 个 epoch,2x 则表示 24 个 epcoh
- coco 表示在 COCO 数据集格式上训练
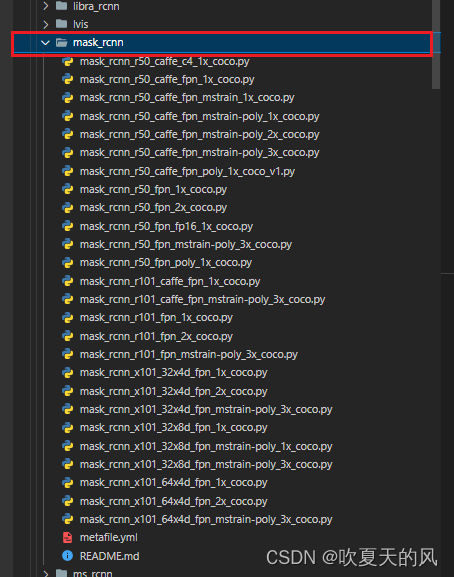
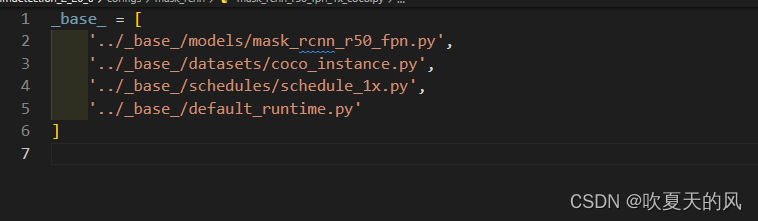
7.这里以mask_rcnn_r50_fpn_1x_coco.py为例,可以看到配置文件中有4个目录,需要依次修改
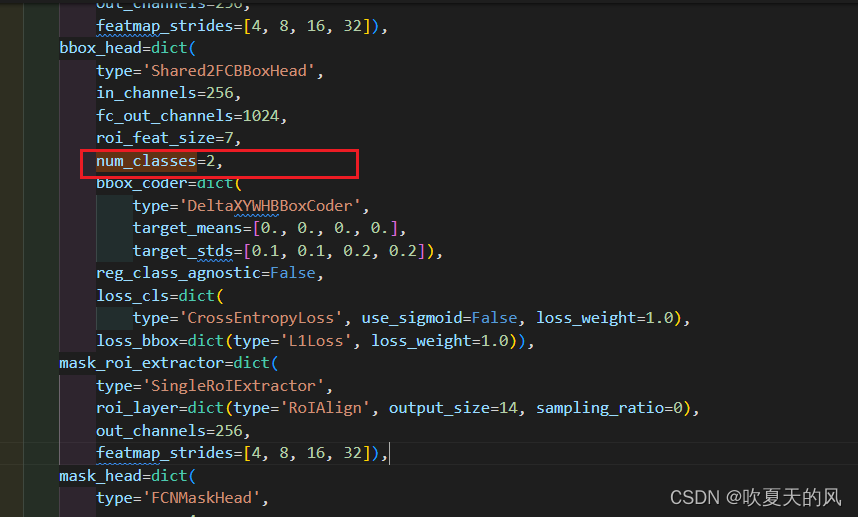
1.打开mask_rcnn_r50_fpn.py,将init_cfg 地址改为预训练模型地址(预训练模型下载地址可由项目README.md中Model zoo找到,也可在官方Github找到。),并将num_classes修改为所标注缺陷的种类数
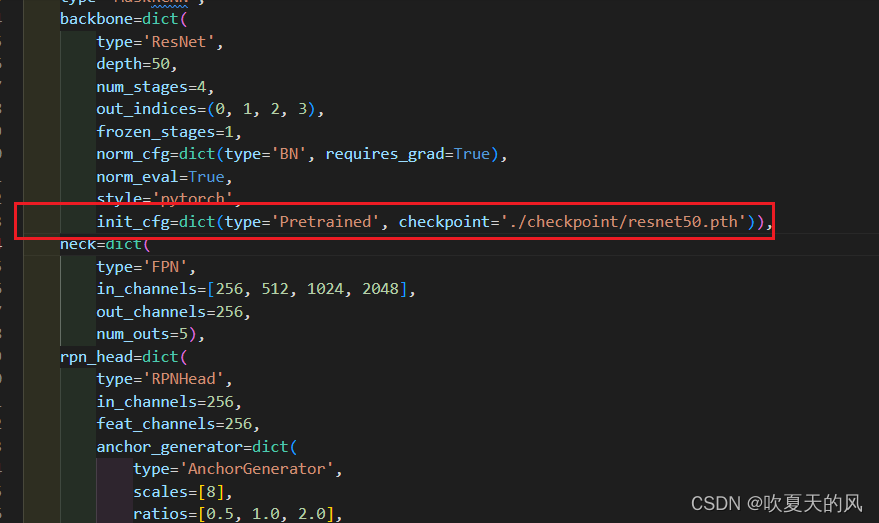
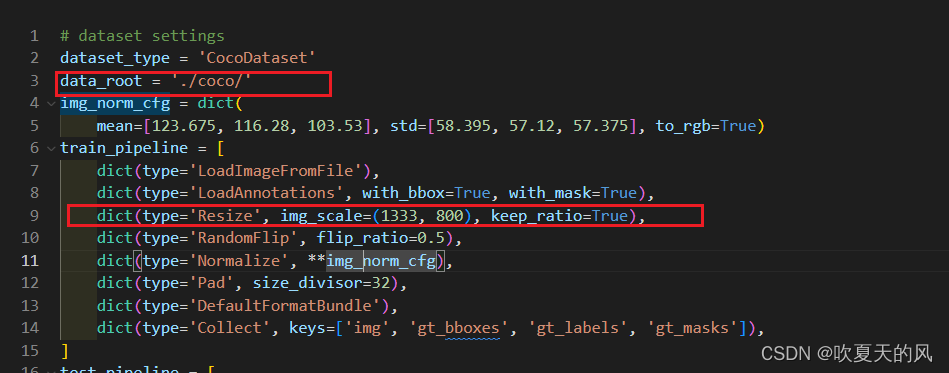
2.打开第二个文件coco_instance.py,将data_root路径改为你自己coco数据集的位置(注意一定要以/结尾),修改输出图片尺寸(根据自己的数据集决定)
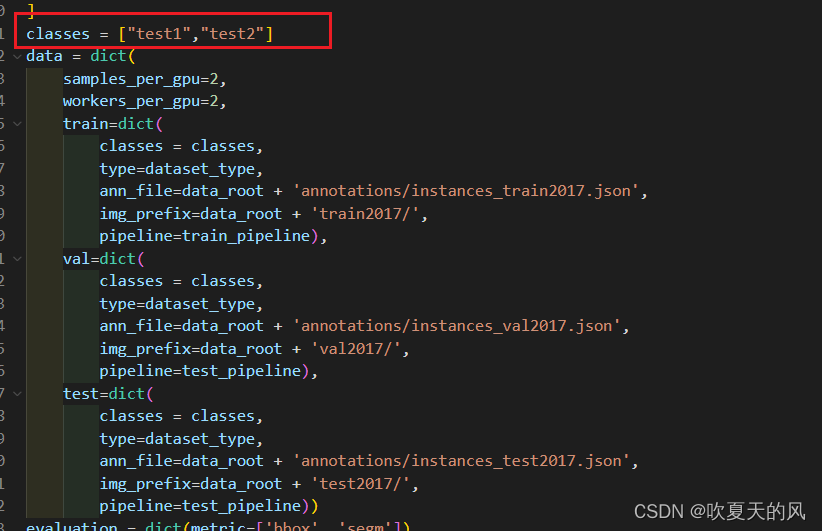
将自己数据的标签写入配置文件,在data前一行添加自己的标签列表,同时在train,val,test中添加classes = classes,如果不添加,模型就会默认读取coco原始数据集的80个标签,与自己的数据集对应不上就会报错。
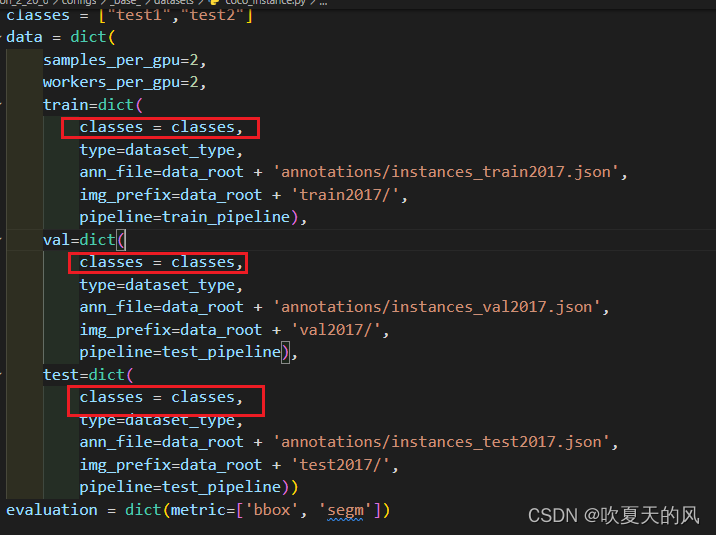
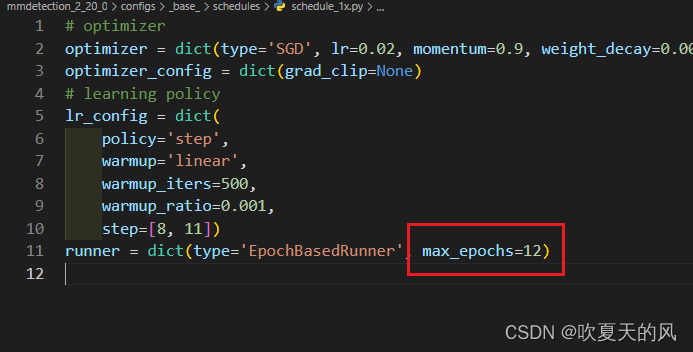
3.打开第三个文件修改学习率和训练轮数以及学习率衰减轮数(学习率也可以不改,具体根据batchsize和显卡数量决定)
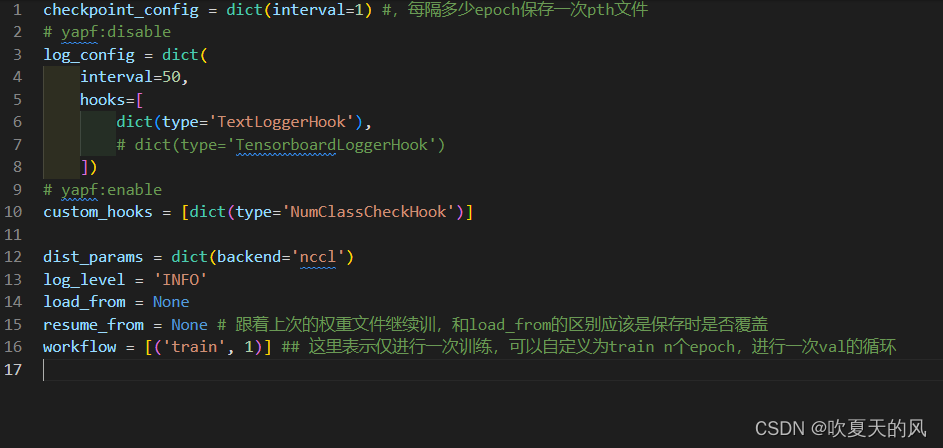
4.打开最后一个文件,各项参数如下图,根据自己需要修改
8.开始训练:
在终端CD 到mmdetection_2_20_0目录下输入,即可开始训练
python tools/train.py configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py















 3825
3825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









