






上一篇是python的学习笔记,因为自己太放松,就没怎么更新下去,现在是做一篇机器学习笔记,学习的视频是吴恩达老师讲的2022的机器学习,这篇文章记录一下课程中第一课第一周的学习内容,以及相关的练习题的训练。
任务T:要实现的任务
经验E:多次运行的经验
性能度量P:良好完成任务T的概率或者次数
机器学习包括两个主要的机器学习问题:监督学习和无监督学习。 监督学习:我们教会计算机做某件事,相关的有:回归、分类问题。 无监督学习:让计算机自己学会做某件事,相关的有:聚类问题。
举出例子的话,监督学习,就比如我给计算机一个相对明确的分类和目标,即:要划分成2类病人,或者是按照已经有的面积-房价的数据,进行相关的预测。监督学习总的来说,就是已经有了一些“正确答案”,我们想要的是通过这些“正确答案”,来进一步判断那些还没有答案的对象。回归问题:通过回归来推出一个连续的输出。分类问题:推出一组离散的结果。
而无监督学习则是在没有一个给定的结果要求的情况下,对数据进行分析。比如在一堆数据中,由计算机自己去分成多少类,类数由计算机自己去分类实现。这钟算法叫聚类算法,是无监督学习中的一种算法。
接触的第一个模型是线性回归模型,这个在excel里面经常使用到,但是真正自己动手实现,以及背后的逻辑思考,基本可以说是没有的,还好老师这里讲得很细。
模型公式为: 。
平方误差成本函数为:。这里的m为训练数,也就是从训练集中获取的有正确答案的数据。关于平方误差成本函数,我们的要求是,最后求出的是数值越小越好,越小,证明我们的预测值
与实际值
越接近,证明我们的回归模型越成功。
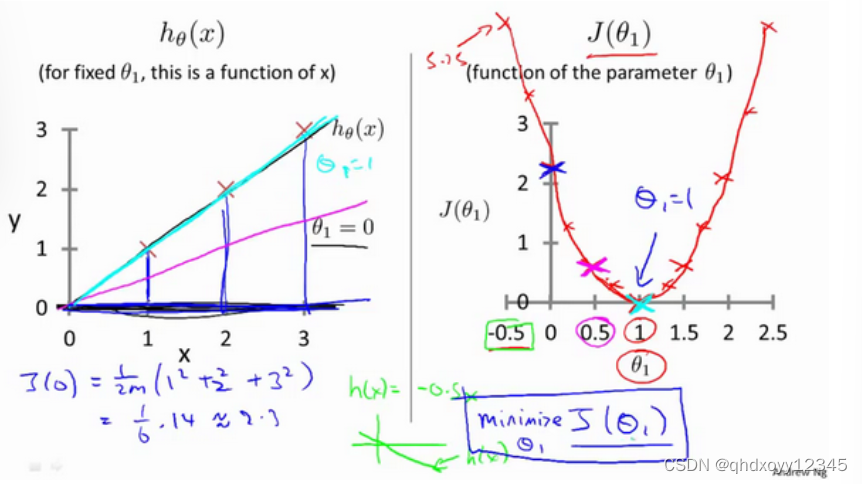
接下来先一步步分析,我们该如何得出最合适的w和b的值,首先将模型简化为:,参数只有w,所以
是关于x的方程,而
是关于w的方程。
再恢复成原来的公式,则会出现一个三维的成本函数图示。
如果我们从下往上看,那其实可以将这个三维图像用二维的等高线图来表示

所以,我们结合上面几个图,如果我们想要找到拟合度最高的回归直线,那么我们最后得到的J值应该要是最小的,也是最低点。引入求函数最小值的算法:梯度下降算法。 梯度下降算法的公式为:
为学习率,通常介于0和1之间的很小正数,可以看作是梯度下降算法中的步伐大小,如果太大,那么下坡的时候就不够准确,如果太小,那么下坡的次数就需要很多次。
下面是对更新梯度的正确写法:
w = tempw; b = tempb
由偏导数方程可得:
所以最后得到的梯度下降算法为:
由上面的公式,就可以实现梯度下降算法了,从公式中,我们每一次更新梯度的时候,都是对所有的数据进行了拟合计算,这种就是批量梯度下降。在批量梯度下降中,每一步梯度下降,我们都会考虑到所有的训练样本。
后面是题目的链接:工作台 - Heywhale.com,我觉得第4题选A,其他的都有答案。















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









