






*分类–逻辑回归模型:
当y只有两种结果时,称为二元分类问题,使用逻辑回归模型。
计算逻辑回归模型的公式:f(x)=g(z)相结合
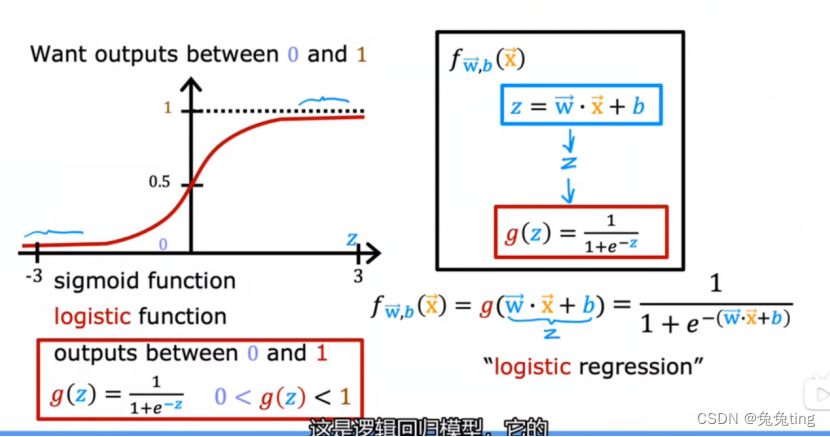
特点,二者概率和为1 :
该公式的含义表示:当y=1,输入为x,参数为w,b时的概率–>

决策边界:它对于y=1 or y=0都是中立的,边界两边各是一种情况
当z=wx+b=0时,得到的关于横纵轴x1x2的等式–即为决策边界。
当x1x2x3…都是一次幂时,决策边界永远是线性的;当高次幂时,就是非线性的了。
成本函数===>
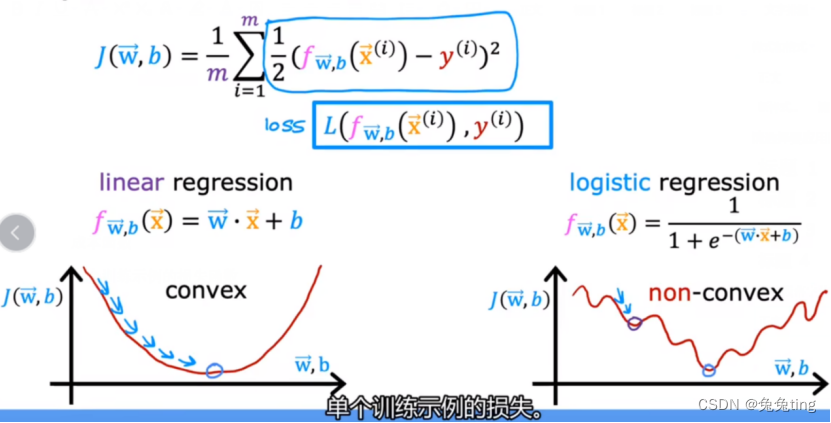
使用原来的J函数:线性回归模型 逻辑回归模型
此时逻辑回归模型的J函数图像不是凸函数,拥有多个局部最小值,因此改用 损失函数 进行计算,进而求成本函数
~单个训练示例的损失函数(凸函数):

由于是逻辑函数,所以f在0-1之间,因此只看0-1之间的函数: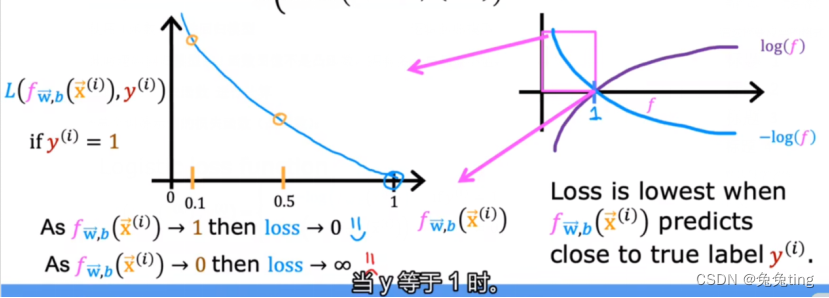

当y=1时,f(x)越接近0,则损失越大;当y=0时,f(x)越接近1,则损失越大
所以,逻辑回归模型的成本函数(平均值):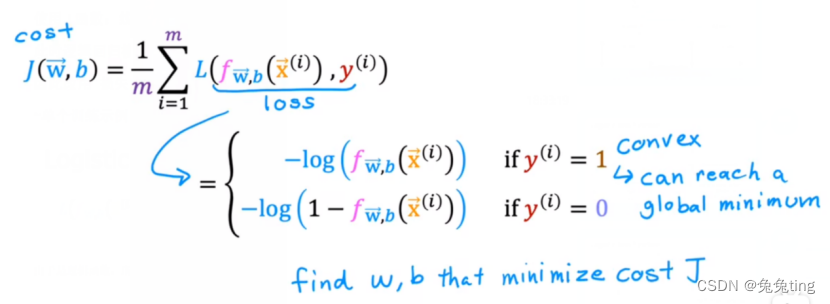
简化损失函数和成本函数:
找J函数的mini值,从而确定w,b的值—>方法:梯度下降

线性回归模型和逻辑回归模型的梯度下降公式一样,但含义是不用的:
两个的f(x)公式是不同的,带进去得到的结果也是不同的
*针对两种模型的一些问题:
1.过拟合问题和欠拟合问题
~线性回归模型—>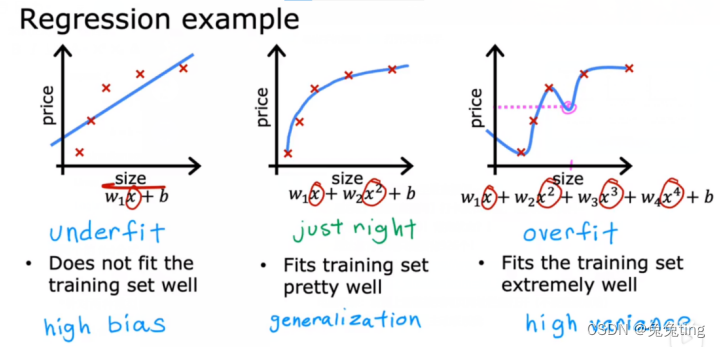
~逻辑回归模型—>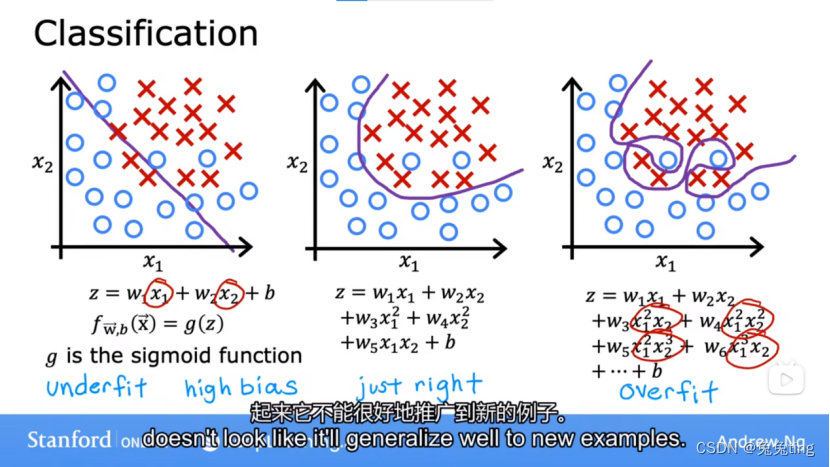
欠拟合(高偏差):该算法不能很好的拟合训练数据
过拟合(高方差):对于每个训练集都完美重合,上下过度摇摆。高阶多项式特征过多了
~解决过度拟合的问题:
1.增加训练集的数据(有时数据是有限的,该方法不可用)
2.特征选择:(多度拟合就是过多的,所有的特征和不充分的数据之间的矛盾,导致了过拟合)选择训练集中特征的一部分,找最主要的,对预测影响最大的,即选取特征子集。(有时无法进行取舍和判断,不知道哪些才是最主要的;且舍去的特征在达到某种情况时可能也会影响预测,使达到预测更准确所需要的数据缺失了一部分,即有用的特征丢失了)
3.正则化:对于高阶的参数一般比较大,影响比较大的时候,修改高阶的参数,使他们近似等于0,使他们的影响变小,不至于过度拟合
~正则化后的成本函数:(加上了正则化项)
第一项:最小化预测的平方差—更好拟合训练数据
第二项:减小wj—防止过拟合
拉姆达:平衡第一项和第二项,最小化均方误差,并保持较小参数
当拉姆达过小,过拟合;当拉姆达过大,欠拟合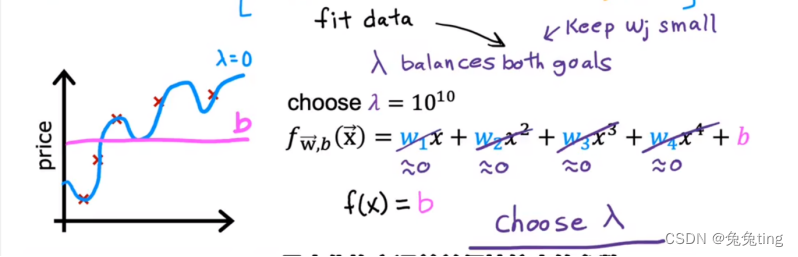
~线性回归的正则方法: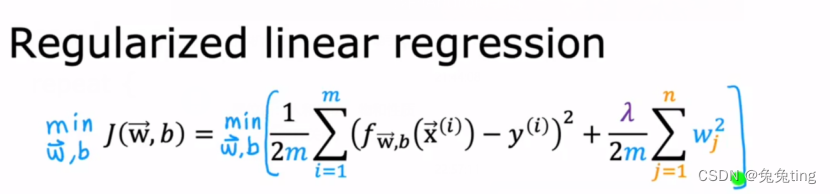
由之前的结论可知: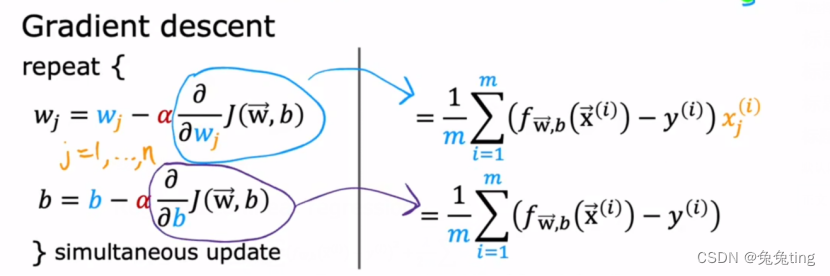
所以,加上正则项之后,重新求导数,可得:
尔法很小,拉姆达很小,所以用1减去之后,实际每次迭代wj的参数都只减少一点点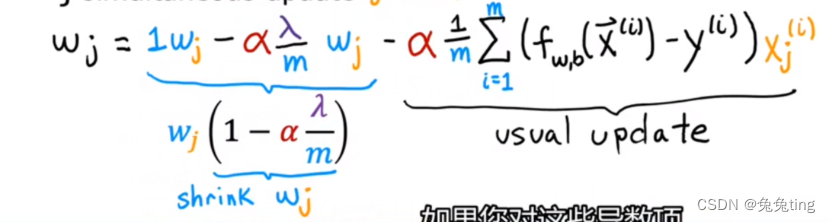
~~逻辑回归的正则方法:
只有参数w,j发生变化,b没有














 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









