







目录
一、概述
1.1 项目介绍
在计算机视觉领域,目标检测和关键点检测是两项至关重要的技术。目标检测旨在识别图像或视频中的特定物体,并确定其位置,以边界框的形式将目标框出。比如在交通监控中,能够快速检测出车辆、行人、交通标志等目标,为智能交通系统提供基础数据。而关键点检测则专注于定位目标物体上的关键特征点,像人体的关节点、面部的五官位置等。通过这些关键点,可以进一步分析目标物体的姿态、动作等信息。
在实际工业应用场景中,目标检测和关键点检测发挥着不可替代的重要作用。目标检测用于产品质量检测,快速识别产品是否存在缺陷、零部件是否安装正确等。而关键点检测能够辅助机器人进行精确的抓取和装配操作,通过识别零部件上的关键特征点,机器人可以准确地完成各种复杂的组装任务,提升生产的自动化水平和产品质量,降低人力成本和出错率。总之,这两项技术的结合,为工业生产和人们的生活带来了极大的便利与安全保障,具有广阔的应用前景和研究价值 。
本文将以医学影像检测为例,详细阐述目标检测和关键点检测算法的研发过程,并且最终采用NCNN工具将算法移植到Windows的桌面应用软件中,通过C++完成落地部署。需要说明的是,本案例是一个通用型案例,整个实践流程可以方便的移植到其他工业应用中,供各位读者借鉴和学习。
1.2 技术方案
本项目选用 ultralytics 的 Yolo8 算法来实现目标检测和关键点检测任务。Ultralytics 是一款广受欢迎的开源算法库,包含YOLOv5、YOLOv8 和 YOLO11 等先进的算法,且一直在维护和更新,其 Pip 下载量超 7,200 万次,GitHub 关注量超 10 万,研究引用超 5,000 次。该算法库广泛应用于各行业,助力 AI 在目标检测等任务中实现高效、智能的运作。
Yolo8 算法作为 Ultralytics 的重要成果,依托先进的神经网络架构,检测精度与速度表现优异。在医学影像检测场景下,能快速识别诸如病变区域、器官轮廓等各类目标,同时精准定位骨骼关节点、病变特征点等相关关键点。需要说明的是,在整个ultralytics算法系列中,Yolo8最为成熟,工业部署方案最齐全。除了目标检测和关键点检测算法以外,Yolo8也具备图像分类、语义分割、实例分割等功能,满足大部分工业应用场景需要。
对于算法的部署,本项目采用 NCNN 工具。NCNN 是腾讯开源的一个轻量级的神经网络推理框架,在 Windows 平台上运行高效,且原生支持 C++ 语言。这使得我们能够轻松地将 Yolo8 算法移植到 Windows 桌面应用软件中。通过 NCNN,可以对模型进行优化,减少内存占用和计算资源消耗,确保在桌面应用中能够流畅的进行医学影像检测。目前NCNN工具一直在更新和维护,
上述技术方案既借助 Ultralytics 在计算机视觉领域的深厚技术积累,发挥 Yolo8 算法强大的检测能力,又利用 NCNN 实现高效部署,为医学影像检测打造可靠且实用的解决方案,也为移植到其他工业应用筑牢根基。
1.3 环境介绍
分为两部分:算法研发和算法部署。算法研发环境为Ubuntu20.04,算法部署环境为Windows11。
研发工具: 考虑到算法涉及到目标检测、关键点检测场景,因此采用集成度较高的ultralytics套件进行算法研发。研发语言为Python。
部署工具:算法部署工具采用腾讯推出的轻量级框架NCNN来实现。考虑到最终部署场景需要兼容Windows7、Windows10、麒麟等操作系统,因此采用的桌面应用开发工具为Qt,版本为5.15.2。部署语言为C++。
1.4 数据和代码下载
通过百度网盘分享的文件:基于Yolo8的手部X光检测项目
链接: https://pan.baidu.com/s/17ZxtEZIx1d6_2EUWBne6wQ?pwd=t2tu 提取码: t2tu
整个资源分成两部分:研发和部署。
1.4.1 研发
本部分资源适用Ubuntu系统。下载下来的压缩文件解压后进入目录中,包含两个子文件夹:data、Ultralytics。其中data存放所有的图像数据和标记数据,Ultralytics存放所有的代码、配置文件和模型文件。
1.4.2 部署
本部分资源适用于Windows系统。
下载下来的资源中包括Qt源代码和对应的可执行程序。读者可以先运行可执行程序查看效果,再分析源码。
二、算法研发
2.1 环境准备
本文的研发环境为Ubuntu20.04。由于需要进行深度学习算法研发,为了保证算法训练速度,需要先确认研发机器上安装有英伟达显卡。确认好以后再按照另一篇博客教程完成基本的显卡驱动、CUDA、CUDNN、NCCL和Pytorch的安装。
本文研发环境具体参数如下:
| 操作系统 | Ubuntu20.04 | |
| Python | 3.10.12 | |
| 显卡 | NVIDIA GeForce RTX 3090 | 24G显存 |
| 显卡驱动 | 550.120 | 最高可支持CUDA12.4 |
| CUDA | 11.8 | |
| CUDNN | 8.9.6 | |
| NCCL | 2.16.5 | |
| Pytorch | 2.6.0 |
完成上述安装后,使用下面的命令安装ultralytics:
pip install ultralytics2.2 数据集准备
2.2.1 数据集说明
本次项目使用的数据集是手部 X 光片。手部 X 光片可清晰呈现手部骨骼形态,辅助医生诊断骨折、骨病,查看关节状况,为手部伤病治疗与康复提供关键影像依据 。示例如下:

本文配套数据中共包括300张手部X光片高清图像,所有图像均为png格式。
通过AI算法可以快速获取上述X光片图像手部的位置、大小以及关键点的坐标等量化数据。这些数据有助于医生更准确地评估病情的严重程度,为制定个性化的治疗方案提供详细依据。比如在评估手部关节脱位程度或骨折移位情况时,量化数据能帮助医生更好地规划手术方案或选择保守治疗的具体措施。
2.2.2 数据标注
本文使用最常见的Labelme标注工具,简单起见,可以直接使用官网发行版进行安装。
本文安装的版本为5.5.0。
安装好以后打开labelme。每次打开labelme之后都需要先做两件事:
(1)单击顶部“文件”->"同时保存图像数据",将对应的复选框去掉;
(2)单击顶部“文件”->"自动保存",将对应的按钮选中。
单击工具栏上的打开目录按钮,找到data/hand_labelme文件夹并打开。打开后会自动加载该目录下的所有X光图片,并且自动叠加了标注信息在上面。如下图所示:
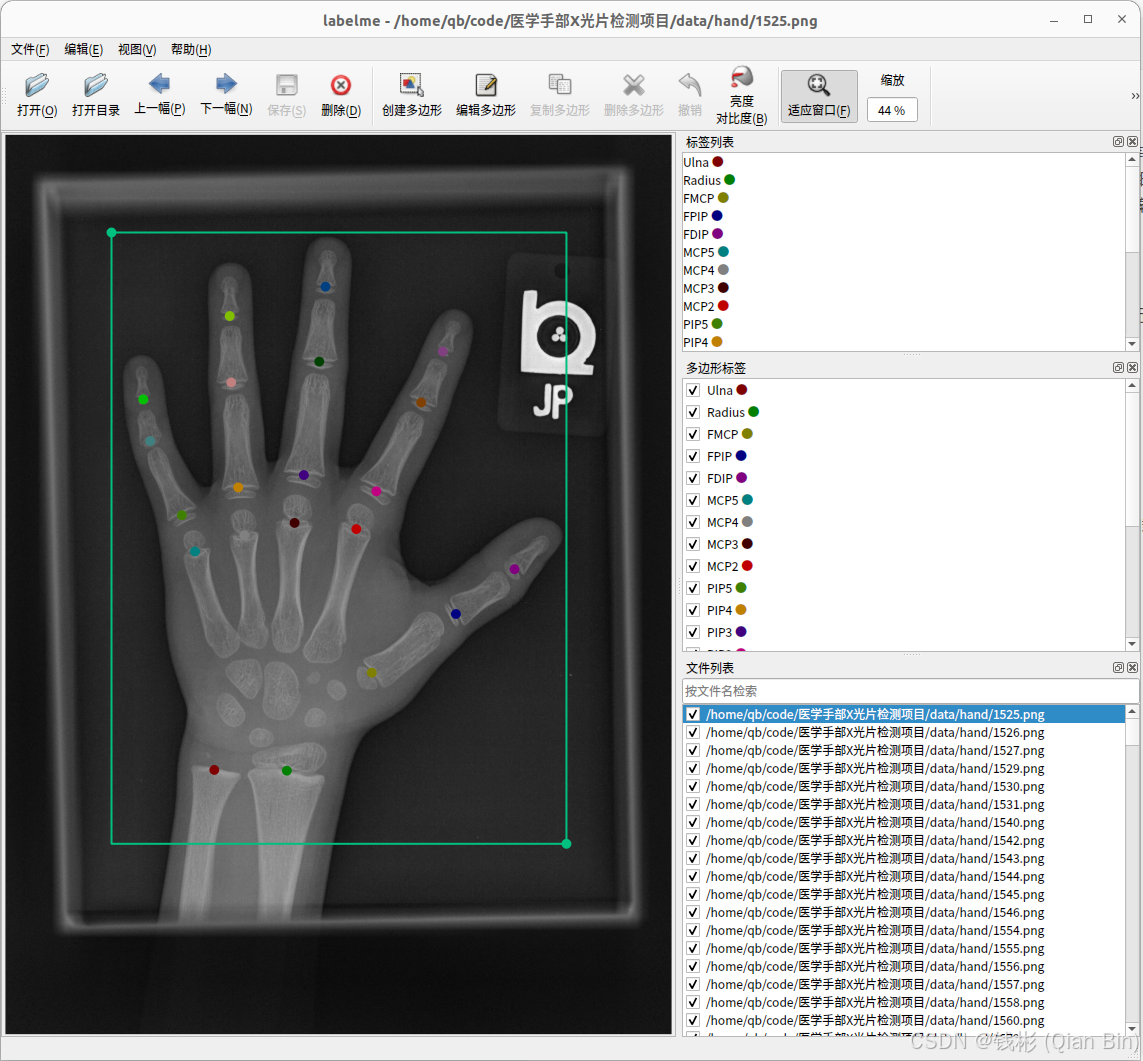
整个标注信息包括两部分:手部矩形框、手部关键点。其中手部矩形框在本项目中只有1个类别,而关键点在本项目中有21个。
该数据集中每张png图片都对应一个标注好的同名的json标注文件,存放在同一目录中。
如果想要自行标注也可以,标注方法如下:
(1)先标注关键点:选择“编辑”->"创建控制点",然后依次开始标注关键点。在给关键点命名时不能出现中文或特殊符号;
(2)再标注矩形框:选择“编辑”->"创建矩形",然后开始标注目标矩形框。同样,在给矩形框命名时不能出现中文或特殊符号。
在整个标注过程中尤其要注意,每个关键点都需要严格包含在对应目标的矩形框内,不能有某个关键点同时出现在多个矩形框内的情况。
2.2.3 数据切分
根据标注好的数据,需要将整个数据集切分为训练集和验证集,方便后续训练。
完整脚本位于Ultralytics/split_dataset.py,代码如下:
from tqdm import tqdm
import shutil
import os
from sklearn.model_selection import train_test_split
def SplitDataset(src_dir, dst_dir, val_size = 0.2,random_state=42): # image_dir:图片路径 label_dir:标签路径
'''切分数据集'''
images = []
labels = []
for image_name in os.listdir(src_dir):
# 判断image_name是否是图像文件
if not image_name.endswith(('.jpg', '.jpeg', '.png', '.bmp', '.gif', '.JPEG','.JPG','.PNG','.BMP','.GIF')):
continue
image_path = os.path.join(src_dir, image_name)
ext = os.path.splitext(image_name)[-1]
label_name = image_name.replace(ext, ".json")
label_path = os.path.join(src_dir, label_name)
if not os.path.exists(label_path):
print("没有找到:", label_path)
continue
else:
images.append(image_path)
labels.append(label_path)
train_data, test_data, train_labels, test_labels = train_test_split(images, labels, test_size=val_size, random_state=random_state)
destination_images = os.path.join(dst_dir,'images')
destination_labels = os.path.join(dst_dir,'labels')
os.makedirs(os.path.join(destination_images, "train"), exist_ok=True)
os.makedirs(os.path.join(destination_images, "val"), exist_ok=True)
os.makedirs(os.path.join(destination_labels, "train_original"), exist_ok=True)
os.makedirs(os.path.join(destination_labels, "val_original"), exist_ok=True)
# 遍历每个有效图片路径
for i in tqdm(range(len(train_data))):
image_path = train_data[i]
label_path = train_labels[i]
image_destination_path = os.path.join(destination_images, "train", os.path.basename(image_path))
shutil.copy(image_path, image_destination_path)
label_destination_path = os.path.join(destination_labels, "train_original", os.path.basename(label_path))
shutil.copy(label_path, label_destination_path)
for i in tqdm(range(len(test_data))):
image_path = test_data[i]
label_path = test_labels[i]
image_destination_path = os.path.join(destination_images, "val", os.path.basename(image_path))
shutil.copy(image_path, image_destination_path)
label_destination_path = os.path.join(destination_labels, "val_original", os.path.basename(label_path))
shutil.copy(label_path, label_destination_path)
if __name__ == '__main__':
'''程序主函数入口'''
val_size = 0.1 # 验证集占比
SplitDataset("../data/hand_labelme",'../data/hand_yolo',val_size = val_size,random_state=42)
print('完成')上述Python脚本的主要作用是将使用LabelMe标注的数据集按照指定的比例分割成训练集和验证集,并将图像和对应的JSON标签文件分别复制到目标目录的相应子文件夹中。
代码的主要功能分析:
(1)输入输出
源目录(src_dir):包含图像和LabelMe生成的JSON标签文件;
目标目录(dst_dir):将创建images和labels子目录,分别存放图像和标签文件;
(2)处理流程
遍历源目录,收集所有图像文件路径和对应的JSON标签文件路径 ;
使用sklearn的train_test_split函数按比例分割数据集 ;
在目标目录创建训练集/验证集的子目录结构;
将图像和标签文件分别复制到对应的训练集/验证集目录中;
(3)目录结构
目标目录会生成如下结构:
-
images/
-
train/ (训练集图像)
-
val/ (验证集图像)
-
-
labels/
-
train_original/ (训练集标签)
-
val_original/ (验证集标签)
-
(4)特点
支持多种常见图像格式(jpg, png等) ;
会检查是否存在与图像对应的标签文件;
使用tqdm显示进度条;
可设置验证集比例和随机种子;
最终在data文件夹中会生成对应的切分好的数据集文件夹hand_yolo,其中270张图像用于训练,30张图像用于验证。
2.2.4 格式转换
上一小节完成了数据切分,并基本按照ultralytics的目录结构进行了重组。但是所有的标注信息文件依然是json文件,而ultralytics要求的标注文件是txt格式,需要进行标注文件的格式转换。
完整转换脚本位于Ultralytics/labelme2yolo.py中,代码如下:
import os
import json
from pathlib import Path
from ultralytics.utils import TQDM
import cv2
def convert_labelme_to_yolo_keypoint(root_path: str,class_mapping:dict):
data_root_path = Path(root_path)
class_mapping = class_mapping
def convert_label(image_name, img_width, img_height, orig_label_dir, save_dir):
"""Converts a single image's DOTA annotation to YOLO OBB format and saves it to a specified directory."""
orig_label_path = orig_label_dir / f"{image_name}.json"
save_label_path = save_dir / f"{image_name}.txt"
with open(orig_label_path, 'r', encoding='utf-8') as f:
labelme = json.load(f)
with open(save_label_path, 'w', encoding='utf-8') as f:
for each_ann in labelme['shapes']: # 遍历每个标注
if each_ann['shape_type'] == 'rectangle': # 每个框,在 txt 里写一行
yolo_str = ''
## 框的信息
# 框的类别 ID
bbox_class_id = class_mapping['bbox_class'][each_ann['label']]
yolo_str += '{} '.format(bbox_class_id)
# 左上角和右下角的 XY 像素坐标
bbox_top_left_x = int(min(each_ann['points'][0][0], each_ann['points'][1][0]))
bbox_bottom_right_x = int(max(each_ann['points'][0][0], each_ann['points'][1][0]))
bbox_top_left_y = int(min(each_ann['points'][0][1], each_ann['points'][1][1]))
bbox_bottom_right_y = int(max(each_ann['points'][0][1], each_ann['points'][1][1]))
# 框中心点的 XY 像素坐标
bbox_center_x = int((bbox_top_left_x + bbox_bottom_right_x) / 2)
bbox_center_y = int((bbox_top_left_y + bbox_bottom_right_y) / 2)
# 框宽度
bbox_width = bbox_bottom_right_x - bbox_top_left_x
# 框高度
bbox_height = bbox_bottom_right_y - bbox_top_left_y
# 框中心点归一化坐标
bbox_center_x_norm = bbox_center_x / img_width
bbox_center_y_norm = bbox_center_y / img_height
# 框归一化宽度
bbox_width_norm = bbox_width / img_width
# 框归一化高度
bbox_height_norm = bbox_height / img_height
yolo_str += '{:.5f} {:.5f} {:.5f} {:.5f} '.format(bbox_center_x_norm, bbox_center_y_norm, bbox_width_norm, bbox_height_norm)
## 找到该框中所有关键点,存在字典 bbox_keypoints_dict 中
bbox_keypoints_dict = {}
for each_ann in labelme['shapes']: # 遍历所有标注
if each_ann['shape_type'] == 'point': # 筛选出关键点标注
# 关键点XY坐标、类别
x = int(each_ann['points'][0][0])
y = int(each_ann['points'][0][1])
label = each_ann['label']
if (x>bbox_top_left_x) & (x<bbox_bottom_right_x) & (y<bbox_bottom_right_y) & (y>bbox_top_left_y): # 筛选出在该个体框中的关键点
bbox_keypoints_dict[label] = [x, y]
## 把关键点按顺序排好
for each_class in class_mapping['keypoint_class']: # 遍历每一类关键点
if each_class in bbox_keypoints_dict:
keypoint_x_norm = bbox_keypoints_dict[each_class][0] / img_width
keypoint_y_norm = bbox_keypoints_dict[each_class][1] / img_height
yolo_str += '{:.5f} {:.5f} {} '.format(keypoint_x_norm, keypoint_y_norm, 2) # 2-可见不遮挡 1-遮挡 0-没有点
else: # 不存在的点,一律为0
yolo_str += '0 0 0 '
# 写入 txt 文件中
f.write(yolo_str + '\n')
for phase in ["train", "val"]:
image_dir = data_root_path / "images" / phase
orig_label_dir = data_root_path / "labels" / f"{phase}_original"
save_dir = data_root_path / "labels" / phase
save_dir.mkdir(parents=True, exist_ok=True)
image_paths = list(image_dir.iterdir())
for image_path in TQDM(image_paths, desc=f"Processing {phase} images"):
image_name_without_ext = image_path.stem
img = cv2.imread(str(image_path))
h, w = img.shape[:2]
convert_label(image_name_without_ext, w, h, orig_label_dir, save_dir)
#生成训练用的yaml文件
yaml_path = os.path.join(root_path,"dataset.yaml")
with open(yaml_path, 'w+') as yaml_file:
yaml_file.write('train: %s\n' % \
os.path.abspath(os.path.join(data_root_path, "images", "train")))
yaml_file.write('val: %s\n\n' % \
os.path.abspath(os.path.join(data_root_path, "images", "val")))
yaml_file.write('nc: %i\n\n' % len(class_mapping['bbox_class'].keys()))
yaml_file.write('kpt_shape: [%i,%i]\n\n' % (len(class_mapping['keypoint_class']),3))
names_str = ''
for label in class_mapping['bbox_class'].keys():
names_str += "'%s', " % label
names_str = names_str.rstrip(', ')
yaml_file.write('names: [%s]' % names_str)
if __name__ == "__main__":
'''主函数入口'''
# 定义标签(最终预测也是按照下面定义的顺序)
class_mapping = {
'bbox_class':{'hand':0}, # 设置目标框的标签,序号从0开始
'keypoint_class':['Ulna', 'Radius', 'FMCP','FPIP','FDIP','MCP5','MCP4','MCP3','MCP2','PIP5','PIP4',
'PIP3','PIP2','MIP5','MIP4','MIP3','MIP2','DIP5','DIP4','DIP3','DIP2'] # 设置关键点的标签
}
# 转换数据集
convert_labelme_to_yolo_keypoint('../data/hand_yolo/',class_mapping=class_mapping)上述Python脚本的主要作用是将LabelMe标注的关键点检测数据集转换为YOLO格式,适用于YOLO模型的训练。以下是代码的核心功能分析:
(1)核心功能:
-
处理包含矩形框(目标检测)和点(关键点)的LabelMe JSON标注
-
转换为YOLO格式的txt文件,包含:
-
目标框信息(类别、中心坐标、宽高,均为归一化值)
-
关键点信息(每个点的归一化坐标和可见性标志)
-
-
自动生成YOLO训练所需的dataset.yaml配置文件
(2)关键处理逻辑:
-
对每个图像文件:
-
读取JSON标注文件
-
处理矩形框标注(转为YOLO格式的bbox)
-
关联框内的关键点(检查点是否在框内)
-
按预定义顺序排列关键点,不存在则填充0
-
-
支持训练集和验证集的批量转换
(3)数据结构要求:
-
输入目录结构:
-
images/train/ (训练图像)
-
images/val/ (验证图像)
-
labels/train_original/ (原始LabelMe JSON标签)
-
labels/val_original/ (原始LabelMe JSON标签)
-
-
输出目录结构:
-
labels/train/ (生成的YOLO格式txt)
-
labels/val/ (生成的YOLO格式txt)
-
(4)特点:
-
支持自定义类别映射(class_mapping)
-
关键点可见性统一设为2(可见)
-
自动计算图像尺寸用于坐标归一化
-
使用OpenCV读取图像尺寸
-
包含进度条显示(TQDM)
到这里就彻底完成了整个数据的准备,在data目录下生成好了用于yolo8训练 评估的hand_yolo文件夹。
2.3 训练和评估
上一节完成了数据的准备工作,本节开始进行算法训练。
完整训练脚本位于Ultralytics/train.py中,代码如下:
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# 训练模型
results = model.train(data=r'../data/hand_yolo/dataset.yaml' ,
epochs=100,imgsz=640, batch=32,verbose=False,pose=25, seed=2024, device=[0,1])
# 验证模型
model.val()上述代码使用 Ultralytics 的 YOLOv8 模型进行目标检测和关键点检测任务,主要包含模型加载、训练和验证三个部分。
代码分析
-
模型加载:
-
使用
yolov8n-pose.pt预训练模型,这是 YOLOv8 的轻量级版本,专为关键点检测设计 -
预训练模型作为起点有利于迁移学习,能加速收敛和提高最终性能
-
-
训练配置:
-
数据配置:通过 YAML 文件指定数据集路径和结构
-
训练周期:100 epochs
-
输入尺寸:640x640 像素
-
批量大小:32(使用多GPU可支持更大batch)
-
关键点个数:21个(根据实际情况修改)
-
设备:使用 GPU 0 和 1 进行多卡训练
-
随机种子:固定为2024确保可复现性
-
-
验证阶段:
-
训练后自动验证模型性能
-
会输出关键指标如精度、召回率等
-
由于需要使用与预训练模型,对于Yolov8的相关预训练模型下载网址:Yolo8Pose。
训练完成后,输出如下:

可以看到无论是目标框还是关键点,检测精度都在97%以上,检测精度非常高。
最终在runs/pose/train/weights文件夹中会存放训练好的模型文件。由于本文采用了Yolov8中最轻量的模型,因此训练好的模型文件仅有7M左右,非常适合CPU端快速推理。
2.4 推理
本小节使用前面训练好的模型来进行图像推理。完整训练脚本位于Ultralytics/infer.py中,代码如下
import cv2
from ultralytics import YOLO
#加载训练好的模型
model = YOLO(r"./runs/pose/train/weights/best.pt")
# 加载图像并进行预测
im2 = cv2.imread(r"./test.jpg")
results = model.predict(source=im2, save=True, save_txt=True,iou=0.5) # save predictions as labels
print(results[0].keypoints.xy )上述代码使用训练好的 YOLOv8 姿态估计模型对单张图像进行预测并输出关键点坐标,主要包含以下功能:
-
模型加载:从训练保存的路径加载自定义训练的最佳模型(
best.pt),这是之前训练过程的最终产物,包含学习到的权重参数。 -
图像处理:使用OpenCV读取测试图像(
test.jpg),作为模型的输入源。 -
预测配置:
-
save=True保存可视化结果图像(默认会标注检测框和关键点) -
save_txt=True将关键点坐标保存为文本文件 -
iou=0.5设置NMS的交并比阈值为0.5,控制重叠检测的过滤强度
-
-
关键点输出:打印图像检测结果的归一化关键点坐标(
results[0].keypoints.xy),输出格式为张量,包含所有检测到的关键点的(x,y)坐标位置。
运行上述脚本后,在runs/pose中会生成redict文件夹,里面存放了对应的预测结果,如下图所示:
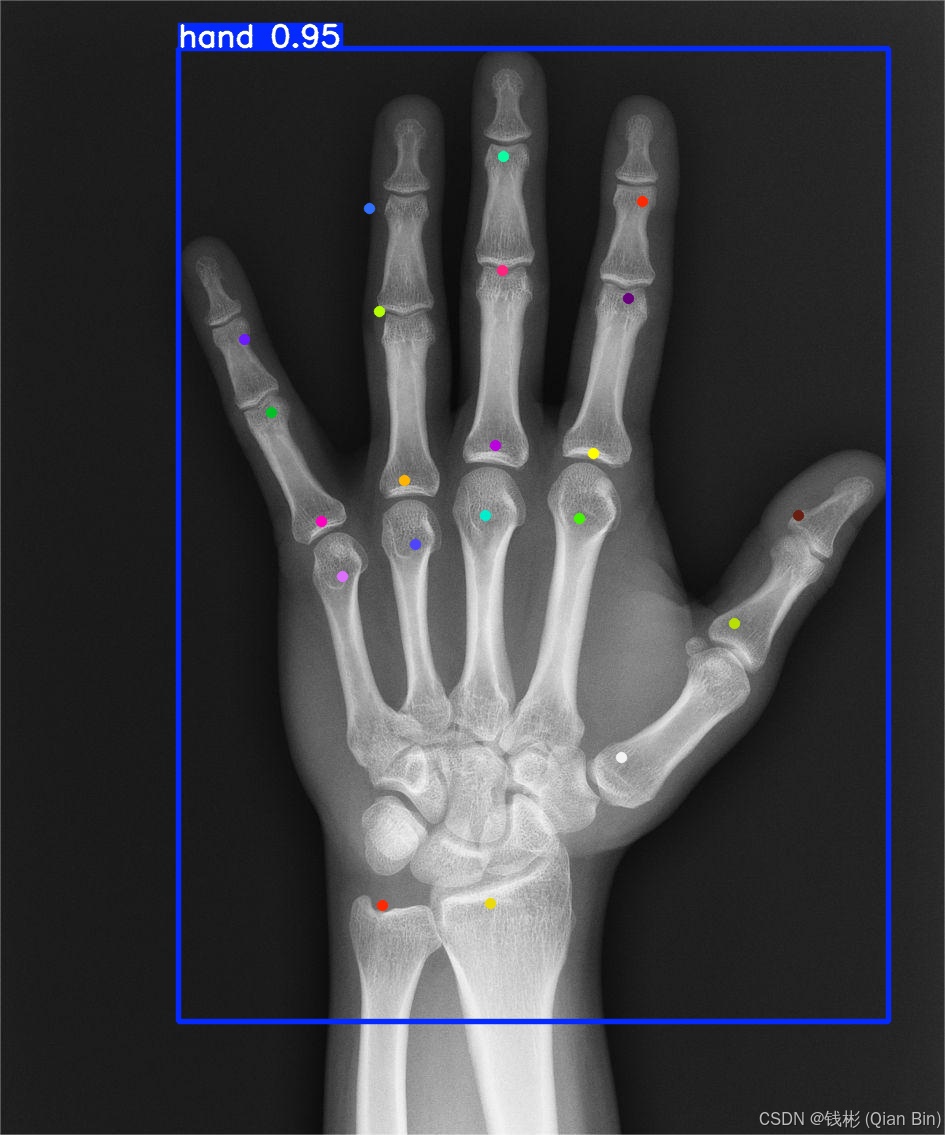
可以看到整体精度还是非常准的,后续通过使用更大的模型或者增加epoch的次数可以进一步提升精度。
2.5 转NCNN
为了能够方便后续使用NCNN部署,需要将训练好的模型转换为NCNN格式,主要分7步。
(1)首先安装相关的转换组件
pip install -U pnnx ncnn -i https://pypi.tuna.tsinghua.edu.cn/simple(2)将pt模型转换为best.torchscript
yolo export model=./runs/pose/train/weights/best.pt format=torchscript转换完的模型保存在./runs/pose/train/weights中。
(3)转换best.torchscript为静态图模型
pnnx ./runs/pose/train/weights/best.torchscript(4)修改best_pnnx.py部分代码用于动态形状推理
代码修改前:
v_137 = v_136.view(1, 51, 6400)
v_143 = v_142.view(1, 51, 1600)
v_149 = v_148.view(1, 51, 400)
v_150 = torch.cat((v_137, v_143, v_149), dim=-1)
...
v_184 = v_161.view(1, 65, 6400)
v_185 = v_172.view(1, 65, 1600)
v_186 = v_183.view(1, 65, 400)
v_187 = torch.cat((v_184, v_185, v_186), dim=2)
...修改后:
v_137 = v_136.view(1, 63, -1).transpose(1, 2)
v_143 = v_142.view(1, 63, -1).transpose(1, 2)
v_149 = v_148.view(1, 63, -1).transpose(1, 2)
v_150 = torch.cat((v_137, v_143, v_149), dim=1)
...
v_184 = v_161.view(1, 65, -1).transpose(1, 2)
v_185 = v_172.view(1, 65, -1).transpose(1, 2)
v_186 = v_183.view(1, 65, -1).transpose(1, 2)
v_187 = torch.cat((v_184, v_185, v_186), dim=1)
return v_187, v_150将修改后的best_pnnx.py文件拷贝到根目录下面。
(5)利用修改后的best_pnnx.py重新导出torchscript文件。
python3 -c 'import best_pnnx; best_pnnx.export_torchscript()'最终在./runs/pose/train/weights中生成新的best_pnnx.py.pt文件。
(6)转换为新的ncnn文件
pnnx ./runs/pose/train/weights/best_pnnx.py.pt inputshape=[1,3,640,640] inputshape2=[1,3,320,320]最终会生成两个ncnn文件:best_pnnx.py.ncnn.param、best_pnnx.py.ncnn.bin。
为了方便后面使用,将这两个文件重命名为best_pnnx.ncnn.param、best_pnnx.ncnn.bin。后续部署环节只需要这两个文件即可。将这两个文件拷贝到部署环境中(Windows电脑上)即可。
三、算法部署
前面完成了整个的算法研发,并生成了最终的两个部署文件best_pnnx.ncnn.param、best_pnnx.ncnn.bin。本节开始,将在windows电脑上完成最终的部署应用,开发一款桌面应用软件,使用Qt C++开发,能实现手部X光图像的自动检测。
为了最大程度的兼容windows7 32位操作系统,接下来的部署案例全部基于windows 32位来开发,这样开发出来的程序基本可以满足目前市面上95%以上在用Windows电脑的运行要求。(64位程序的开发按照本教程一样操作,相对来说64位会更简单)
3.1 安装Qt和OpenCV
目前Qt6开发的程序不支持windows7,因此本文选择Qt5,本文使用的具体版本为Qt5.15.2。
Qt的安装方法本文不再赘述,具体可以参考另一篇博客。注意安装过程中需要选择MSVC2019 32-bit。
由于项目中涉及到图像处理操作,本文使用OpenCV库来完成。目前,OpenCV官方仅提供64位版本的安装包,对于32位系统的支持则需要通过源码自行编译。为了方便读者,本文给出已经编译好的32位的OpenCV下载链接。该OpenCV版本为4.5.4。
3.2 Qt基础示例程序
为了简化后续步骤,本文先下载和使用一个精简的Qt Widget程序。该程序不依赖第三方库,实现了基本的图像加载和显示功能,并且预留了图像处理算法接口,整体比较简洁。后续将在此程序基础上进行二次开发,将算法集成到该程序中。
下载链接。
下载后进行解压,然后使用Qt Creator打开目录中的face.pro文件,此时会重新对项目进行构建,选择之前安装好的MSVC 2019 32bit套件进行构建即可,如下图所示:
打开项目后可以对程序标题之类的文字信息进行修改,最后编译运行,单击“选择图片”按钮,再单击“检测”按钮,效果如下图所示:
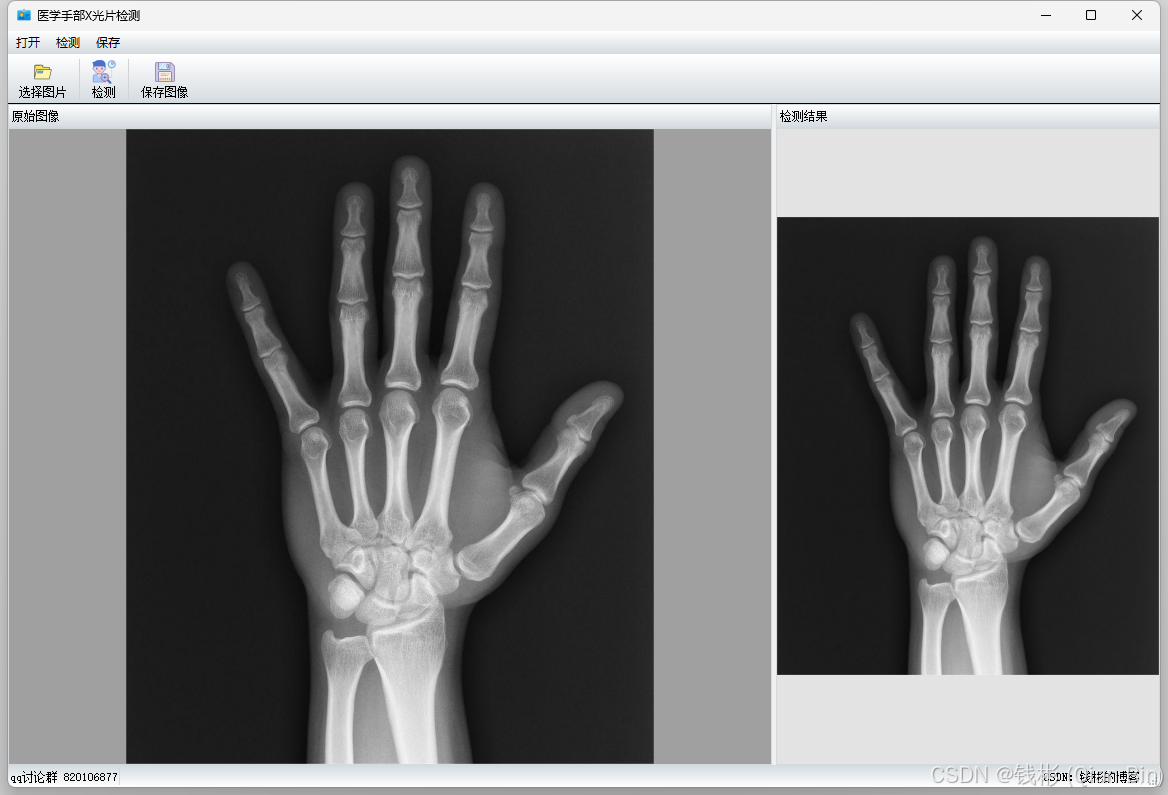
程序中仅保留了检测接口,没有具体算法,只是将原图复制了一份然后在检测结果面板中显示了出来。
程序整体功能较为简单,对Qt稍微熟悉的读者相信不难理解。
下面将详细阐述如何一步步将前面训练好的模型加载到项目中,完成真正的自动检测。
3.3 集成OpenCV
3.3.1 库导入
在faceEval.pro文件中,添加如下代码将OpenCV库导入进来:
INCLUDEPATH += D:\toolplace\opencv4_5_4_32\include
LIBS += -LD:\toolplace\opencv4_5_4_32\x86\vc16\lib\ -lopencv_world454然后将OpenCV库中的opencv_world454.dll文件拷贝到Qt编译出来的release文件夹中,与应用程序同目录。
3.3.2 应用
本小节完成一个简单的应用,旨在测试opencv的集成效果。当单击检测按钮时,使用opencv算法对图像进行上下颠倒。
打开algorithm.h文件,添加OpenCV导入的代码:
#include<opencv2/opencv.hpp>
using namespace cv;然后打开algorithm.cpp文件,添加cvMat2QImage()和QImage2cvMat()函数,同时修改MakeIDPhoto()函数,完整代码如下:
#include "algorithm.h"
//cv::Mat转换成QImage
QImage cvMat2QImage(const Mat& mat)
{
const uchar *pSrc = (const uchar*)mat.data;
QImage image(pSrc, mat.cols, mat.rows, mat.step, QImage::Format_RGB888);
return image.rgbSwapped();
}
//QImage转换成cv::Mat
Mat QImage2cvMat(QImage image)
{
Mat mat = Mat(image.height(), image.width(), CV_8UC4, (void*)image.constBits(), image.bytesPerLine());
cv::cvtColor(mat, mat, COLOR_BGRA2BGR);
return mat;
}
//检测算法
QImage MakeIDPhoto(QImage img)
{
//将QImage转换为cv::Mat
Mat mat = QImage2cvMat(img);
//opencv图像上下颠倒
cv::flip(mat, mat, 0);
//opencv图像转QImage
img = cvMat2QImage(mat);
return img;
}保存所有修改后重新编译项目,最终运行效果如下:
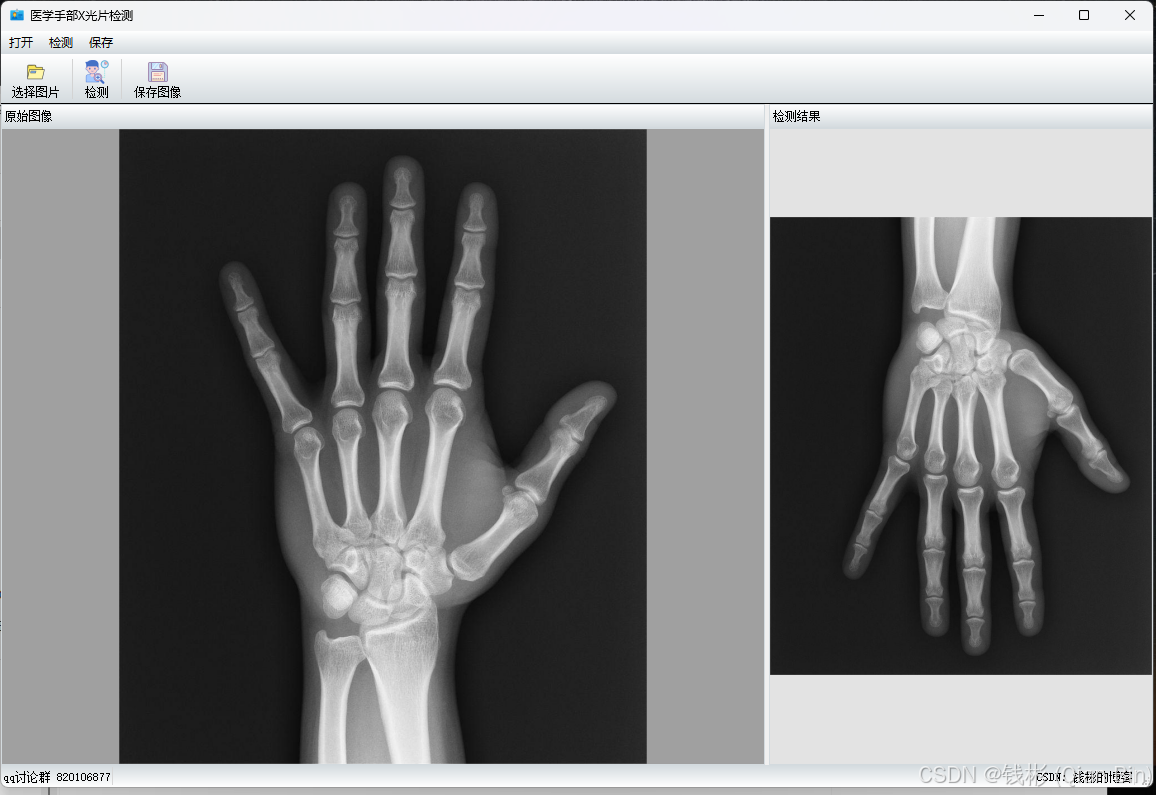
到这里就完成了opencv的导入工作并进行了验证。下面开始正式集成目标检测/关键点检测算法。
3.4 集成NCNN
3.4.1 库导入
参考NCNN官网,下载对应的适配windows的编译好的SHARED动态库。
下载的动态库包含3个版本:arm64、x64、x86,如下图所示:
本文因为最终要适配32位的windows7,因此选择x86版本下面的动态库进行使用。
在faceEval.pro文件中,添加如下代码将NCNN库导入进来:
INCLUDEPATH += D:\toolplace\ncnn-20241226-windows-vs2019-shared\x86\include\ncnn
LIBS += -LD:\toolplace\ncnn-20241226-windows-vs2019-shared\x86\lib\ -lncnn然后将NCNN库中的ncnn.dll文件拷贝到Qt编译出来的release文件夹中,与应用程序同目录。
最后将第二部分训练好的模型models整个复制到release以及Desktop_Qt_5_15_2_MSVC2019_32bit-Release文件夹(release的上一层文件夹)中。这样就做好了全部的准备工作了。
3.4.2 应用
打开algorithm.h文件,添加NCNN导入的代码:
#include "layer.h"
#include "net.h"
#include <float.h>
#include <stdio.h>
#include <vector>然后打开algorithm.cpp文件,添加相关检测函数,同时修改MakeIDPhoto()函数,完整代码如下:
//自定义关键点
struct NCNNKeyPoint
{
cv::Point2f p; //关键点坐标
float prob;//置信度
};
//自定义检测结果
struct Object
{
cv::Rect_<float> rect; //检测框
int label; //类别标签
float prob; //置信度
std::vector<NCNNKeyPoint> NCNNKeyPoints; //关键点
};
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
static void qsort_descent_inplace(std::vector<Object>& objects, int left, int right)
{
int i = left;
int j = right;
float p = objects[(left + right) / 2].prob;
while (i <= j)
{
while (objects[i].prob > p)
i++;
while (objects[j].prob < p)
j--;
if (i <= j)
{
// swap
std::swap(objects[i], objects[j]);
i++;
j--;
}
}
// #pragma omp parallel sections
{
// #pragma omp section
{
if (left < j) qsort_descent_inplace(objects, left, j);
}
// #pragma omp section
{
if (i < right) qsort_descent_inplace(objects, i, right);
}
}
}
static void qsort_descent_inplace(std::vector<Object>& objects)
{
if (objects.empty())
return;
qsort_descent_inplace(objects, 0, objects.size() - 1);
}
static void nms_sorted_bboxes(const std::vector<Object>& objects, std::vector<int>& picked, float nms_threshold, bool agnostic = false)
{
picked.clear();
const int n = objects.size();
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = objects[i].rect.area();
}
for (int i = 0; i < n; i++)
{
const Object& a = objects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = objects[picked[j]];
if (!agnostic && a.label != b.label)
continue;
// intersection over union
float inter_area = intersection_area(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0;
}
if (keep)
picked.push_back(i);
}
}
static inline float sigmoid(float x)
{
return 1.0f / (1.0f + expf(-x));
}
static void generate_proposals(const ncnn::Mat& pred, const ncnn::Mat& pred_points, int stride, const ncnn::Mat& in_pad, float prob_threshold, std::vector<Object>& objects)
{
const int w = in_pad.w;
const int h = in_pad.h;
const int num_grid_x = w / stride;
const int num_grid_y = h / stride;
const int reg_max_1 = 16;
const int num_points = pred_points.w / 3;
for (int y = 0; y < num_grid_y; y++)
{
for (int x = 0; x < num_grid_x; x++)
{
const ncnn::Mat pred_grid = pred.row_range(y * num_grid_x + x, 1);
const ncnn::Mat pred_points_grid = pred_points.row_range(y * num_grid_x + x, 1).reshape(3, num_points);
// find label with max score
int label = 0;
float score = sigmoid(pred_grid[reg_max_1 * 4]);
if (score >= prob_threshold)
{
ncnn::Mat pred_bbox = pred_grid.range(0, reg_max_1 * 4).reshape(reg_max_1, 4).clone();
{
ncnn::Layer* softmax = ncnn::create_layer("Softmax");
ncnn::ParamDict pd;
pd.set(0, 1); // axis
pd.set(1, 1);
softmax->load_param(pd);
ncnn::Option opt;
opt.num_threads = 1;
opt.use_packing_layout = false;
softmax->create_pipeline(opt);
softmax->forward_inplace(pred_bbox, opt);
softmax->destroy_pipeline(opt);
delete softmax;
}
float pred_ltrb[4];
for (int k = 0; k < 4; k++)
{
float dis = 0.f;
const float* dis_after_sm = pred_bbox.row(k);
for (int l = 0; l < reg_max_1; l++)
{
dis += l * dis_after_sm[l];
}
pred_ltrb[k] = dis * stride;
}
float pb_cx = (x + 0.5f) * stride;
float pb_cy = (y + 0.5f) * stride;
float x0 = pb_cx - pred_ltrb[0];
float y0 = pb_cy - pred_ltrb[1];
float x1 = pb_cx + pred_ltrb[2];
float y1 = pb_cy + pred_ltrb[3];
std::vector<NCNNKeyPoint> NCNNKeyPoints;
for (int k = 0; k < num_points; k++)
{
NCNNKeyPoint NCNNKeyPoint;
NCNNKeyPoint.p.x = (x + pred_points_grid.row(k)[0] * 2) * stride;
NCNNKeyPoint.p.y = (y + pred_points_grid.row(k)[1] * 2) * stride;
NCNNKeyPoint.prob = sigmoid(pred_points_grid.row(k)[2]);
NCNNKeyPoints.push_back(NCNNKeyPoint);
}
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = label;
obj.prob = score;
obj.NCNNKeyPoints = NCNNKeyPoints;
objects.push_back(obj);
}
}
}
}
static void generate_proposals(const ncnn::Mat& pred, const ncnn::Mat& pred_points, const std::vector<int>& strides, const ncnn::Mat& in_pad, float prob_threshold, std::vector<Object>& objects)
{
const int w = in_pad.w;
const int h = in_pad.h;
int pred_row_offset = 0;
for (size_t i = 0; i < strides.size(); i++)
{
const int stride = strides[i];
const int num_grid_x = w / stride;
const int num_grid_y = h / stride;
const int num_grid = num_grid_x * num_grid_y;
generate_proposals(pred.row_range(pred_row_offset, num_grid), pred_points.row_range(pred_row_offset, num_grid), stride, in_pad, prob_threshold, objects);
pred_row_offset += num_grid;
}
}
//目标检测_关键点检测
static int detect_yolov8_pose(const cv::Mat& bgr, std::vector<Object>& objects)
{
//创建ncnn网络模型
ncnn::Net yolov8;
//是否启用GPU加速
yolov8.opt.use_vulkan_compute = false;
//是否使用float16精度
yolov8.opt.use_bf16_storage = false;
//加载模型
yolov8.load_param("./models/best_pnnx.ncnn.param");
yolov8.load_model("./models/best_pnnx.ncnn.bin");
//图像预处理参数
const int target_size = 640;
const float prob_threshold = 0.25f;
const float nms_threshold = 0.45f;
const float mask_threshold = 0.5f;
int img_w = bgr.cols;
int img_h = bgr.rows;
// 检测尺度 ultralytics/cfg/models/v8/yolov8.yaml
std::vector<int> strides(3);
strides[0] = 8;
strides[1] = 16;
strides[2] = 32;
const int max_stride = 32;
// 补齐长宽
int w = img_w;
int h = img_h;
float scale = 1.f;
if (w > h)
{
scale = (float)target_size / w;
w = target_size;
h = h * scale;
}
else
{
scale = (float)target_size / h;
h = target_size;
w = w * scale;
}
//OpenCV图像数据转NCNN矩阵数据
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, img_w, img_h, w, h);
// 补齐尺寸
int wpad = (w + max_stride - 1) / max_stride * max_stride - w;
int hpad = (h + max_stride - 1) / max_stride * max_stride - h;
ncnn::Mat in_pad;
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
// 归一化
const float norm_vals[3] = {1 / 255.f, 1 / 255.f, 1 / 255.f};
in_pad.substract_mean_normalize(0, norm_vals);
//创建提取器
ncnn::Extractor ex = yolov8.create_extractor();
//输入模型推理数据推理
ex.input("in0", in_pad);
//提取模型输出数据
ncnn::Mat out;
ex.extract("out0", out);
ncnn::Mat out_points;
ex.extract("out1", out_points);
//后处理:检测结果转换为proposals
std::vector<Object> proposals;
generate_proposals(out, out_points, strides, in_pad, prob_threshold, proposals);
// 根据置信度排序(从高到低)
qsort_descent_inplace(proposals);
// 非极大值抑制 nms_threshold
std::vector<int> picked;
nms_sorted_bboxes(proposals, picked, nms_threshold);
int count = picked.size();
if (count == 0)
return 0;
const int num_points = out_points.w / 3; //每个关键点由3个值组成
//后处理:调整位置
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
for (int j = 0; j < num_points; j++)
{
objects[i].NCNNKeyPoints[j].p.x = (objects[i].NCNNKeyPoints[j].p.x - (wpad / 2)) / scale;
objects[i].NCNNKeyPoints[j].p.y = (objects[i].NCNNKeyPoints[j].p.y - (hpad / 2)) / scale;
}
// clip
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
return 0;
}
cv::Mat draw_objects(const cv::Mat& bgr, const std::vector<Object>& objects)
{
//定义目标框名称列表
static const char* class_names[] = {"hand"};
cv::Mat image = bgr.clone();
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
// 红色画关键点
for (size_t j = 0; j < obj.NCNNKeyPoints.size(); j++)
{
const NCNNKeyPoint& NCNNKeyPoint = obj.NCNNKeyPoints[j];
fprintf(stderr, "%.2f %.2f = %.5f\n", NCNNKeyPoint.p.x, NCNNKeyPoint.p.y, NCNNKeyPoint.prob);
if (NCNNKeyPoint.prob < 0.2f)
continue;
cv::circle(image, NCNNKeyPoint.p, 10, cv::Scalar(0, 0, 255), -1);
}
// 蓝色画目标矩形框
cv::rectangle(image, obj.rect, cv::Scalar(255, 0, 0), 3);
char text[256];
sprintf(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > image.cols)
x = image.cols - label_size.width;
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
return image;
}
//检测算法
QImage MakeIDPhoto(QImage img)
{
//将QImage转换为cv::Mat
Mat mat = QImage2cvMat(img);
//检测
std::vector<Object> objects;
detect_yolov8_pose(mat, objects);
mat = draw_objects(mat, objects);
//opencv图像转QImage
img = cvMat2QImage(mat);
return img;
}
上述关键代码已经给出了详细注释,详细读者分析后可以理解。
保存所有修改后,运行项目,最终效果如下图所示:
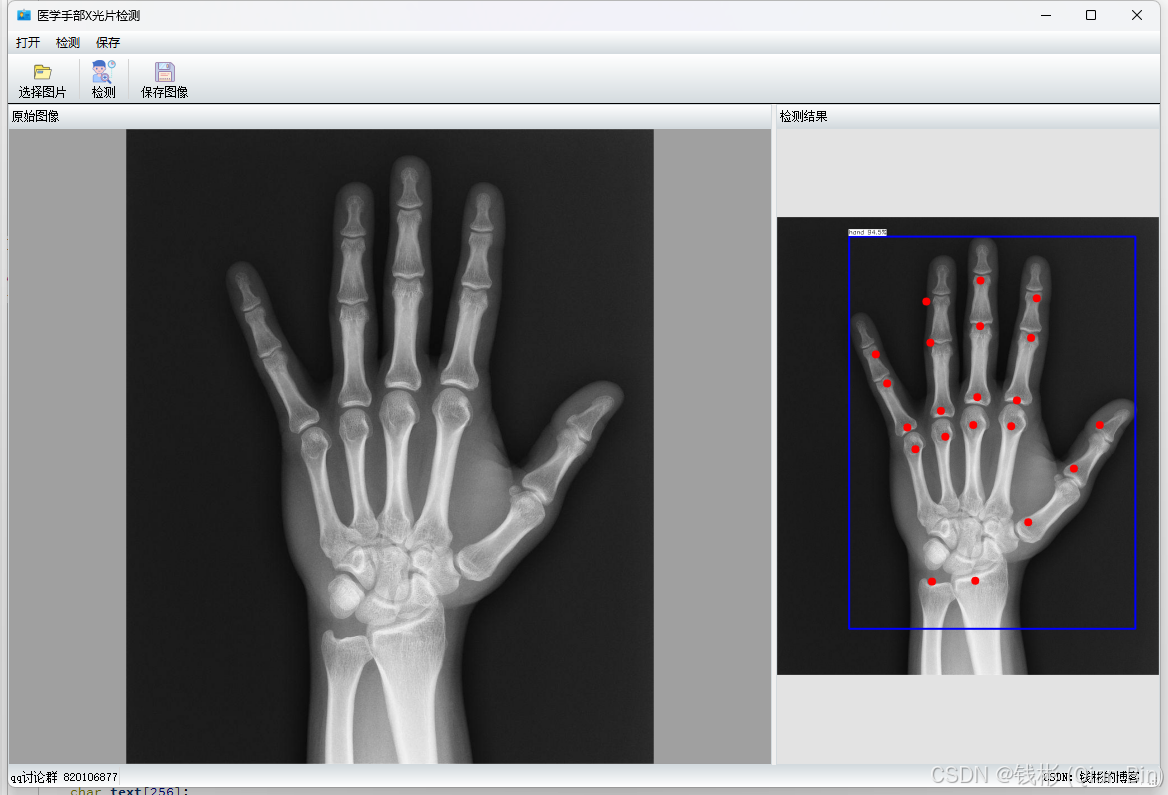
可以看到,这个检测结果跟前面研发阶段的推理是一致的。由于我们的程序全部是采用x86架构编写的,因此可以移植到window7 的32位机器上运行,而64位机器也能兼容运行。这样就满足了在旧设备上完成AI算法研发的任务。
四、小结
本文详细阐述了基于YOLO8的研发和部署教程。另外,想要深入学习图像处理/深度学习的读者可以参考我的教学书籍。该书使用国产化深度学习框架PaddlePaddle进行案例讲解,全部面向真实的工业应用场景,以实践为导向进行教学,旨在读者学完后即可以依葫芦画瓢上手做项目。如果有毕业设计困扰的同学也可以参考该书。最后再给一个qq交流群:820106877,有疑问的可以一起交流学习。
由于水平有限,文中有错误和不当的地方欢迎在评论区留言,大家一起共同进步!


















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











