










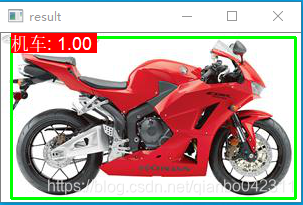
效果1 识别摩托
效果 公路场景撞击现场

定义识别名称
const char* classNames[] = { “背景”,
“飞机”, “自行车”, “鸟”, “船”,
“瓶子”, “大汽车”, “小汽车”, “猫”, “椅子”,
“奶牛”, “餐桌”, “狗”, “马”,
“机车”, “人”, “花盆植物”,
“羊”, “沙发”, “火车”, “tv监视器” };
String file_path = parser.getPathToApplication() + "/";
String modelConfiguration = file_path + "xx.prototxt";
String modelBinary = file_path + "model.caffemodel";
try
{
//加载深度神经网络模型
dnn::Net net = readNetFromCaffe(modelConfiguration, modelBinary);
if (net.empty())
{
cerr << "Can't load network by using the following files: " << endl;
cerr << "prototxt: " << modelConfiguration << endl;
cerr << "caffemodel: " << modelBinary << endl;
cerr << "Models can be downloaded here:" << endl;
cerr << "https://github.com/chuanqi305/MobileNet-SSD" << endl;
exit(-1);
}
net.setPreferableTarget(DNN_TARGET_OPENCL);
//定义图片,也可以从rtsp摄像头读取后 解码放到mat中,具体看我文章
rtsp读取摄像头进行算法识别
string image_file_name = "J:/bbbbb.jpg";
cv::Mat frame = cv::imread(image_file_name, CV_LOAD_IMAGE_COLOR);
判别过程
Mat inputBlob = blobFromImage(frame, inScaleFactor,
Size(inWidth, inHeight),
Scalar(meanVal, meanVal, meanVal),
false, false); //Convert Mat to batch of images
net.setInput(inputBlob); //set the network input
Mat detection = net.forward(); //compute output
vector<double> layersTimings;
double freq = getTickFrequency() / 1000;
double time = net.getPerfProfile(layersTimings) / freq;
Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
float confidenceThreshold = 0.5;// parser.get<float>("min_confidence");
for (int i = 0; i < detectionMat.rows; i++)
{
float confidence = detectionMat.at<float>(i, 2);
if (confidence > confidenceThreshold)
{
size_t objectClass = (size_t)(detectionMat.at<float>(i, 1));
int left = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
int top = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
int right = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
int bottom = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0),2);
String label = format("%s: %.2f", classNames[objectClass], confidence);
int baseLine = 0;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine+2),
Scalar(0, 0, 255),FILLED);
putTextZH(frame, label.c_str(), Point(left, top), Scalar(255, 255, 255), 18);
/*putText(frame, label, Point(left, top),
FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));*/
}
}
以上使用opencv3.4.1 win7 win10 调试通过,在linux下面都是一样的过程,整个的
训练过程描述
可以使用多种方式,一种是yolo,一种是tensorflow模式训练模型,比较难的是逻辑模型,也就是行为识别,没有好的显卡很难做,这里没有写真正的详细过程,后续文章会写两种模式来训练模型。请关注我.


















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











