









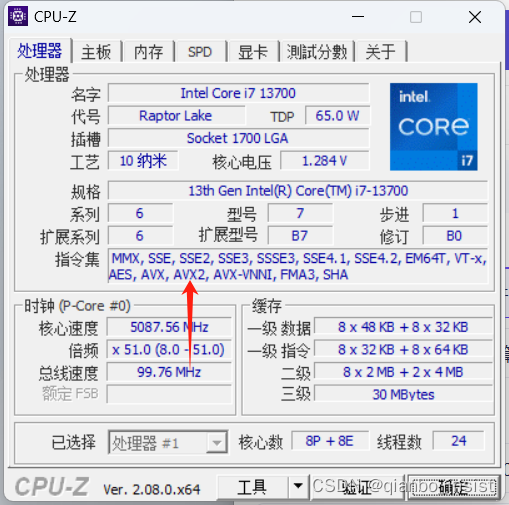
使用cpu-z 查看cpu指令集
2 向量加,乘法,除法
我们使用向量加,为什么函数是0 到 8 的计算,因为avx2 寄存器为256位,同时设置启动增强指令集
#include <immintrin.h> // 引入包含AVX2指令集的头文件
void vector_addition_avx2(float* __restrict a, float* __restrict b, float* __restrict result, size_t size)
{
// 检查size是否为2的倍数,确保可以正确处理AVX2的256位寄存器
assert(size % 8 == 0);
__m256 va, vb, vr;
for (size_t i = 0; i < size; i += 8)
{
// 加载8个浮点数到AVX寄存器
va = _mm256_load_ps(a + i);
vb = _mm256_load_ps(b + i);
// 使用AVX2指令进行向量加法
vr = _mm256_add_ps(va, vb);
// 存储结果回内存
_mm256_store_ps(result + i, vr);
}
}
// 主函数或者其他地方调用该函数
int main()
{
float a[32], b[32], result[32];
// 初始化a、b数组...
vector_addition_avx2(a, b, result, sizeof(a) / sizeof(a[0]));
return 0;
}
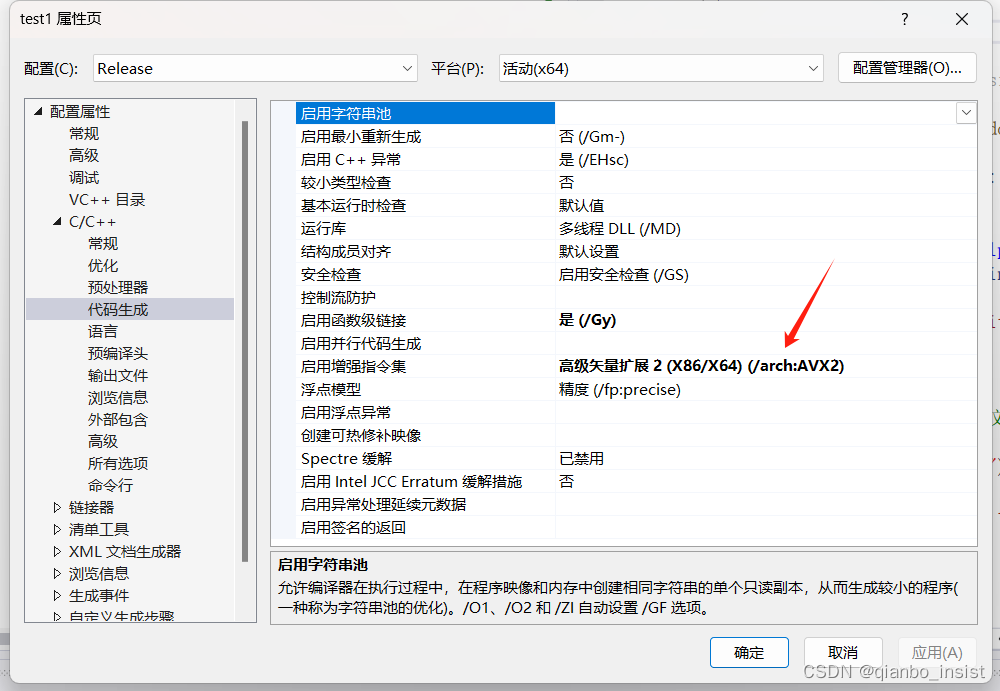
猜猜以上代码会怎么样,如果是在debug下,明显avx2 指令集会快,在release下,普通代码立刻甩开了avx2指令,所以一定要判断数据量,下面重写代码来测试
如何做
应该在数据量大的情况下使用avx2 指令,否则效果适得其反,没有达到数据的瓶颈,不会显现出好的结果,并且下面我们同时使用向量加,乘法,除法,同时增加一个我以前写过的时间计算类
#include <immintrin.h> // 引入包含AVX2指令集的头文件
#include <chrono>
class TicToc
{
public:
TicToc()
{
tic();
}
void tic()
{
start = std::chrono::system_clock::now();
}
double toc()
{
end = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
return elapsed_seconds.count() * 1000;
}
private:
std::chrono::time_point<std::chrono::system_clock> start, end;
};
void vector_addition_avx2(float* __restrict a, float* __restrict b, float* __restrict result, size_t size)
{
// 检查size是否为2的倍数,确保可以正确处理AVX2的256位寄存器
// assert(size % 8 == 0);
__m256 va, vb, vr;
for (size_t i = 0; i < size; i += 8)
{
// 加载8个浮点数到AVX寄存器
va = _mm256_load_ps(a + i);
vb = _mm256_load_ps(b + i);
// 使用AVX2指令进行向量加法
vr = _mm256_add_ps(va, vb);
vr = _mm256_mul_ps(va, vb);
vr = _mm256_div_ps(va, vb);
// 存储结果回内存
_mm256_store_ps(result + i, vr);
}
}
void addition(float* a, float* b, float* result, size_t size)
{
for (int i = 0; i < size; i++)
{
result[i] = a[i] + b[i];
result[i] = a[i] * b[i];
result[i] = a[i] / b[i];
}
}
// 主函数或者其他地方调用该函数
int main()
{
#define N 1024
//float a[NUM], b[NUM], result[NUM],result1[NUM];
float* a = new float[N * N];
float* b = new float[N * N];
float* c = new float[N * N];
// 初始化a、b数组...
for (int i = 0; i < N*N; i++)
{
a[i] = float(i) * 0.1f;
b[i] = float(i) * 0.2f;
}
TicToc t;
for(int i =0;i<1000;i++)
vector_addition_avx2(a, b, c,N*N);
printf("time is %f\n",t.toc());
TicToc t1;
for (int i = 0; i < 1000; i++)
{
addition(a, b, c, N * N);
}
printf("time is %f\n", t1.toc());
for (int i = 0; i < 8; i++)
{
printf("%04f ", c[i]);
printf("%04f \n",c[i]);
}
delete[]a;
delete[]b;
delete[]c;
return 0;
}
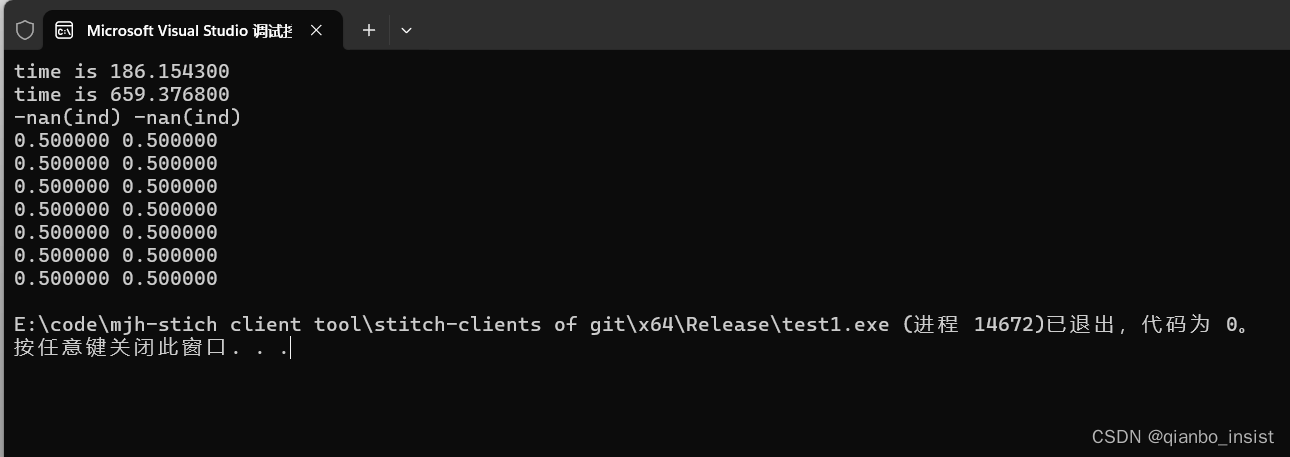
3 结果显示
在1M数据向量的运算量下,结果显示,普通计算要比avx2指令集慢了好几倍,优点显现
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











