







最近有一篇由苹果公司出品的论文,很有意思,我分享给大家。
大致就是说OpenAI和谷歌这些大模型公司,他们一直在吹嘘他们的新AI模型有多牛,说它们能推理。但是,苹果的六个工程师搞了个新研究(https://arxiv.org/pdf/2410.05229),发现这些高级的大型语言模型,一旦遇到那些标准测试题的一点点小变化,它们的数学推理能力就脆弱得跟纸糊的一样,根本靠不住。

这个新研究的结果支持了之前的研究,就是说这些大型语言模型用的是基于概率的模式匹配,但它们缺少真正可靠的数学推理能力所需要的对基本概念的形式理解。研究人员现在猜测,这些大型语言模型(LLM)其实做不了真正的逻辑推理,它们只是试图模仿它们在训练数据中看到的推理步骤。
混合一下
苹果的研究人员搞了个研究,叫做“GSM-Symbolic:理解大型语言模型在数学推理中的局限性”,现在这个研究还是预印本。他们从GSM8K开始,这是个有超过8000个小学水平的数学文字问题的标准化测试集,通常用来测试现代LLM的复杂推理能力。然后,他们用了一种新方法,动态地修改了测试集中的一部分,把一些名字和数字换成了新的值——比如,在新的GSM-Symbolic评估里,原本GSM8K里Sophie给她侄子31块积木的问题,现在变成了Bill给他兄弟19块积木的问题。
这样做可以避免直接用GSM8K的问题喂给AI模型训练数据时可能产生的“数据污染”。同时,这些小变化并没有改变数学推理的实际难度,理论上,模型在GSM-Symbolic上的表现应该和GSM8K一样好。
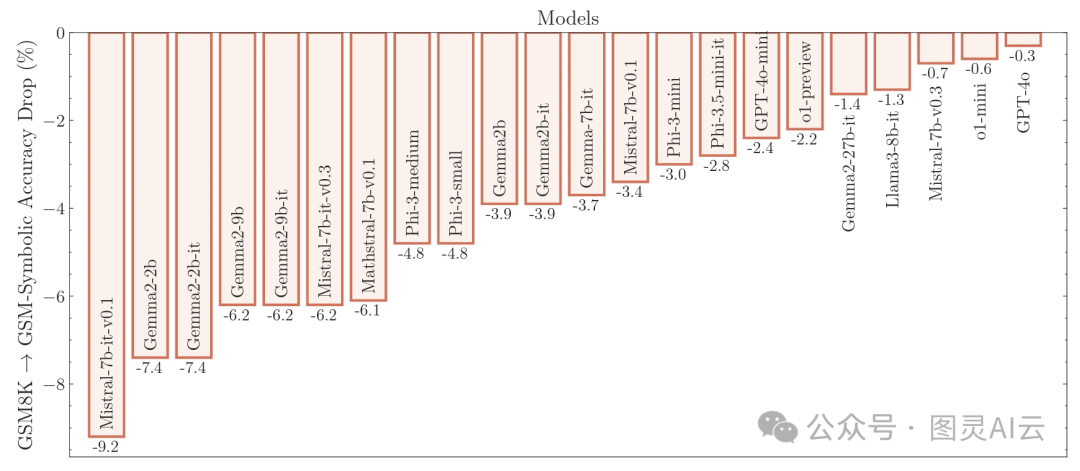
图:在GSM8K测试中,仅仅改变特定的名称和数字就会导致许多模型的性能显著下降
但是,当这些研究人员用GSM-Symbolic测试了20多个最先进的大型语言模型时,他们发现这些模型的平均准确率普遍比GSM8K测试时低,下降幅度在0.3%到9.2%之间。而且,他们在50次不同的GSM-Symbolic测试中发现,使用不同的名称和数值,结果的波动很大。在同一个模型里,最好的测试结果和最差的测试结果之间的准确率差距能达到15%,而且不知道为啥,改变数字比改变名字对准确率的影响更大。
这种波动——无论是在不同的GSM-Symbolic测试中,还是和GSM8K的结果相比——都有点让人意外。因为研究人员说,"解决一个问题需要的总体推理步骤是不变的。" 这么小的变化导致这么大的结果变化,这说明这些模型并没有真正进行"形式"推理,而是"尝试在分布内进行模式匹配,把给定的问题和解决方案步骤和训练数据里看到的类似情况对齐。"
不要被干扰
尽管这样,GSM-Symbolic测试显示的整体波动在大局上相对较小。比如,OpenAI的ChatGPT-4o在GSM8K上的准确率从95.2%降到了GSM-Symbolic上的94.9%。不管这些模型是否真的在背后使用了"形式"推理(尽管当研究人员在问题中增加了一两个额外的逻辑步骤时,很多模型的总准确率急剧下降),使用任何一个基准的成功率都相当高。

图:一个示例展示了一些模型如何被添加到GSM8K基准测试集中的无关信息所误导
但是,苹果的研究人员在GSM-Symbolic的测试中加了点料,他们在问题里塞了些“看起来重要,但实际上没啥用的陈述”,结果大型语言模型的表现更差了。比如,他们搞了个叫“GSM-NoOp”的新测试集,意思是“无操作”,里面的问题会加些额外的细节,比如“某人摘的猕猴桃里,有五个比平常的小”。
这些无关信息的加入,让模型的准确率出现了研究人员说的“灾难性下降”,根据不同的模型,准确率下降了17.5%到65.7%。这种巨大的准确率下降,暴露了这些模型的一个根本问题:它们只是简单地用“模式匹配”把“陈述转换成操作”,而没有真正理解这些陈述的含义。
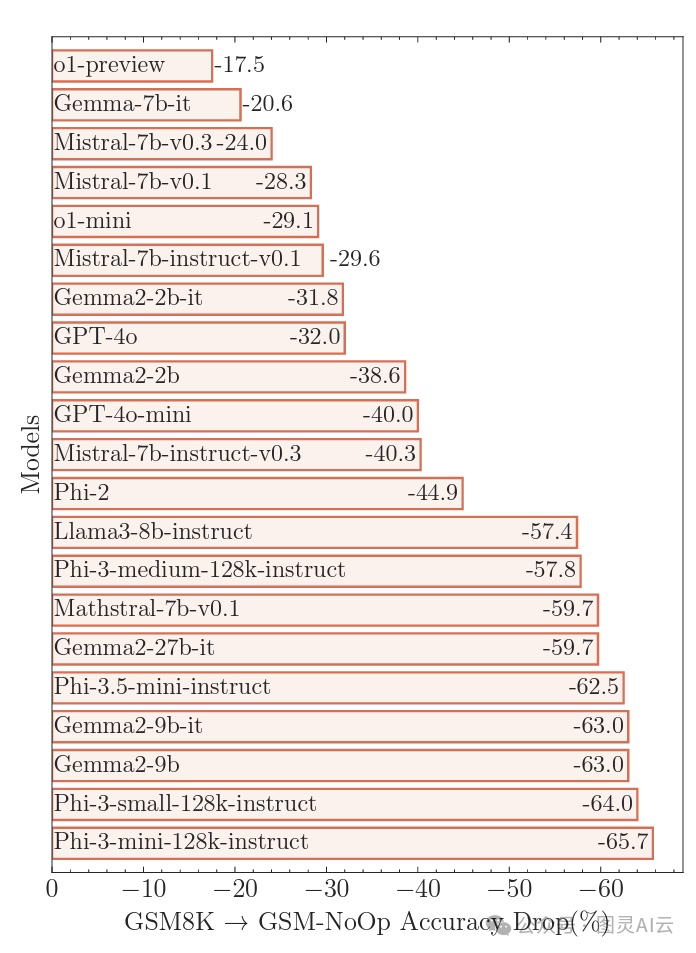
图:向提示中引入无关信息常常导致大多数“推理”型大型语言模型出现“灾难性”的失败
比如说,拿猕猴桃那个例子来说,大多数模型都试图从总数里减去那些小猕猴桃,研究人员猜这是因为模型的训练数据里有很多需要转换成减法操作的类似例子。研究人员管这叫“关键缺陷”,意味着这些模型在推理过程中有更深层次的问题,这些问题不是简单调整一下或者改进一下就能解决的。
理解的幻觉
这篇新的GSM-Symbolic论文的结果,在AI研究圈子里也不算太新鲜。其他一些最近的论文也指出,大型语言模型并没有真正进行形式推理,而是通过在它们海量的训练数据中找到最相似的数据,用概率模式匹配的方式来模仿推理。
新的研究显示,当问题提示引导模型走向那些和训练数据不完全匹配的方向时,这种模仿推理的脆弱性就暴露出来了。这也说明了,如果没有背后的逻辑或世界模型支持,尝试进行高级推理是有固有局限性的。就像Ars Technica的Benj Edwards在7月份谈到AI视频生成时说的那样:
OpenAI的GPT-4在文本合成方面之所以引人注目,部分原因是这个模型已经足够大,吸收了足够的信息(在训练数据中),给人一种它可能真的能够理解和模拟世界的印象。但实际上,它成功的一个关键方面是它“知道”的比大多数人类都多,并且能够以新颖的方式组合这些现有概念,给我们留下深刻印象。有了足够的训练数据和计算能力,AI行业最终可能会在AI视频合成中达到所谓的“理解的幻觉”……
我们在AI的最新“推理”模型中可能看到了类似的“理解的幻觉”,并且看到了当模型遇到意外情况时,这种幻觉是如何破灭的。
AI领域的专家Gary Marcus在分析了一份关于GSM-Symbolic的新研究论文(https://garymarcus.substack.com/p/llms-dont-do-formal-reasoning-and)后提出,人工智能要想实现下一个巨大的飞跃,关键在于神经网络能否实现真正的“符号操作”。这意味着,AI需要能够将知识以变量和对这些变量的操作的形式进行抽象表示,类似于我们在代数和传统计算机编程中所见到的。在那之前,我们所得到的AI“推理”能力可能会非常脆弱,导致AI模型在数学测试中失败,而这种失败方式是计算机永远不会发生的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









