






Dragon是Facebook的分布式图查询引擎,目前支撑着Facebook巨量规模的社交图谱。
每当用户打开Facebook,就会有数以百计的社交图谱信息碎片扑面而来:其中不仅有推文、照片、朋友签到记录,还有他人点赞、评论和分享记录。这些信息随时都在更新:每秒的写入记录都达到数百万,读取记录达到数十亿,因此用户所看到的内容是无法提前准备的。同时,每个Facebook用户所获得的体验也都是个性化定制的,会根据他们与之交互的内容片段差异而有所不同。
社交图谱由无数对象(节点)和关联(边)组成,同时所有的对象和关联都有一系列属性。图谱中典型的查询指令是这样运行的:始于一个节点,根据该节点的属性从数据库中取回所有的边(关联)。因此按照这个流程,可能会有这样一个指令运行:从代表“你”的节点开始,按照一定的顺序——比如添加好友的顺序,从数据库中取回你所有朋友的信息。
如今信息查询的方式已经从memcached和MySQL演变为了TAO系统(即关系与对象服务器系统),这个系统针对大容量的单跳(single-hop)查询做了特别优化。自从TAO投入使用以来,Facebook用户量显著提高,很多推文的用户参与度也大幅提高,有些推文获得了数百万个赞;而类似直播视频之内的功能也能在数分钟之内,获得以多种语言写就的上千条评论,这使得我们在筛选最密切相关的信息以呈现给用户时,也更具有挑战性。尽管大多时候TAO的内置简单架构非常有用,但在大容量的多跳(multi-hop)查询方面,还是需要一些优化。
为了解决更复杂的查询问题,并且提高查询的效率,我们创造了Dragon这个分布式的图谱查询引擎。通过将社交图谱作为对象和关联来建模,Dragon对社交图谱执行实时监控,以查看它的更新情况;同时Dragon还创建了几种不同类型的指数,以提高获取、筛选数据及重排数据顺序的效率。有了Dragon,需要从网络传输到web层的数据大大减少,在降低延迟的同时,也为其他计算腾出了CPU空间。
索引技术
假设用户Alice是双语人士(英语和西班牙语),她有上千个Facebook好友,并在Facebook上关注了Shakira。在她访问Shakira的页面时,我们会显示这样的语句:你的好友Bob、Charlie还有1.04亿用户都关注了这个页面。如果某个推文有数千个评论的话,我们会将与Alice所用语言一致的评论放在最上方。
TAO可以同时拿取几千个关联,这一点虽然大多查询引擎也能实现,但在查询的数据量过大的时候,就会导致延迟增加。在Alice访问Shakira的页面时,当前系统在RAM中缓存了一个子集的评论,按照时间戳这个单整数来排序;而应用程序通过对数千条评论进行分页来执行筛选,找出相关语言的评论,并对数据进行重新排序。
图一:Dragon索引前后的评论存储
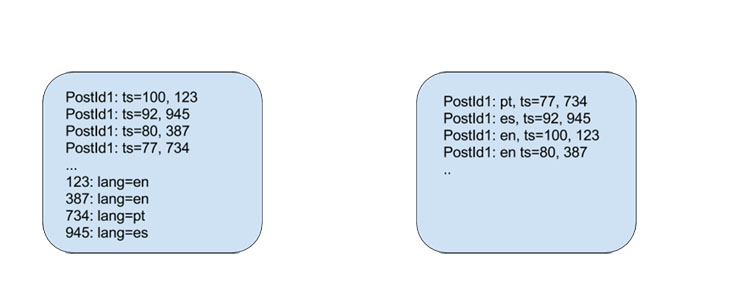
在查阅图谱时,我们通过Dragon引擎指定索引,并根据用户感兴趣的属性来执行筛选。如果初次命中某个查询,Dragon引擎会返回TAO系统中,在RocksDB的永久存储中建立初始数据。Dragon自身存储着最近用到的数据或最常查询的数据,这样在查询响应上就会更高效。因此在Alice访问Shakira的页面时,我们就可以计算出<推文ID,语言>,并直接找到她感兴趣的推文。我们还会对永久存储执行更复杂的排序,比如<语言,分数,评论ID>,以减少查询的消耗。
对Facebook的大多用户来说,他们所发布的推文并不会每条都收到大量的评论,很多人更愿意上传大量的图片。在Facebook上,一次典型的图片上传操作会导致大约20个边(关联)写入MySQL,并通过TAO缓存到RAM中。这些边(关联)可能包含:照片的上传者是谁,照片在哪里拍摄,照片中是否有人被圈出等等。这种做法的好处在于:由于这些信息大都是经常读取的内容,因此我们在信息写入时便完成了大部分的工作。但是,这些信息需要占据存储空间。六年来,数据所占据的大小已经增长了20倍,其中半数都是用来存储关联数据,只有一小部分是描述两个实体间的基础关系,比如Alice->上传->照片ID->上传者->Alice。
通过Dragon引擎,我们只需将这些基础关系写入,然后根据我们希望的导航方式来创建索引。尽管索引让读取速度更快,却让写入速度变慢了,因此我们只在确实需要的时候才创建索引。例如,一个仅有10条评论的推文是不需要索引的——使用TAO对评论执行逐条扫描非常简单。将部分索引技术与支持筛选/排序操作、更丰富的查询语言相结合,对于大小约为原系统150倍大小的新系统来说,只用缓存便能处理其中90%左右的查询量。
社会感知倒排索引
我们发现,人们经常会查询好友的基础个人信息,比如姓名和生日;这些数据主要都是读取操作,很少有写入操作,因此符合反规范化准则。如果将Alice的基础个人信息复制到所有相关的主机上,无论哪个好友在查询对应主机时,都能获得“好友姓名”的答案。这又带来了新的问题:权衡一致性与可用性。尽管索引使得读取速度更快,却让写入变慢了。每次写入都需要对所有相关主机执行写入,而其中一些写入可能会失败。
在信息检索领域,倒排索引是非常热门的技术。如果Alice like了Shakira,我们在Alice相关的主机上存入两个关系:Alice->like->Shakira,以及Shakira->被Alice like。由于like Shakra的用户不仅存在于一台主机上,我们使用了分布式倒排索引。对这样的索引进行查询,需要与集群中的所有主机进行通讯,将大幅提高延迟及查询损耗。
在Dragon引擎实现中,有一个独特之处:基于对查询模式的进一步理解(比如很多查询都是与好友相关的),我们对存储中的索引布局做了优化,而没有采用这类系统常用的随机分片方式。
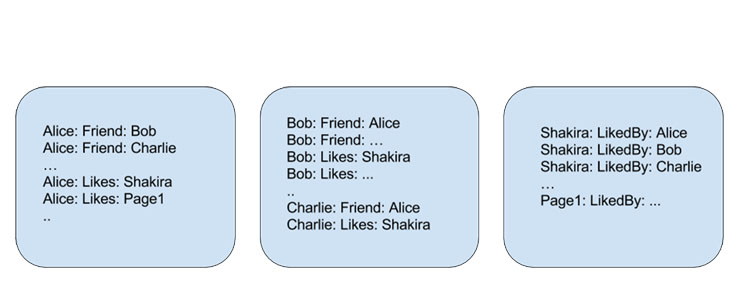
图二:在TAO中存储的好友与页面like——每个盒子代表一台主机
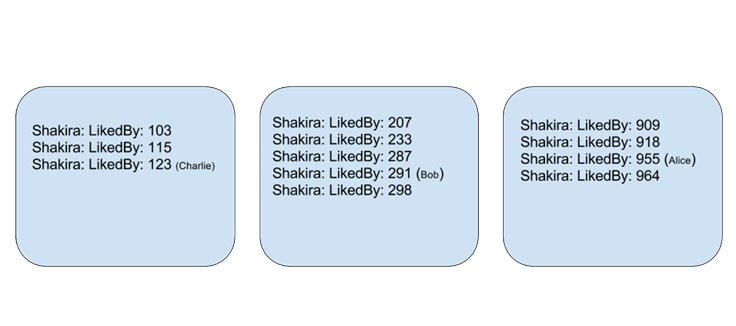
图三:倒排索引广受搜索引擎的欢迎,每个主机负责一系列的对象ID,比如[n*100, n+1*100]
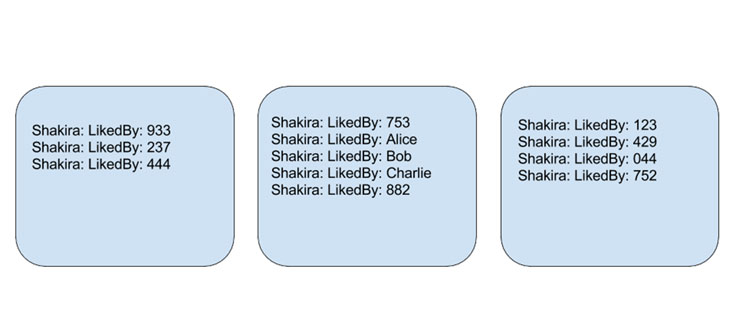
试想一下这个图谱:你的好友+好友彼此间的关系,你就能发现一些清晰的模式。很多人的图谱中包含家人、同事或高中同学之类的朋友圈,其中在同一个朋友圈里的人很有可能也彼此相识。如果Alice、Bob和Charlie在同一家公司工作,Bob和Charlie彼此也是好友,并拥有很多共同的好友,我们的算法就会试着将他们放在同一台主机上。
图四:社会感知倒排索引注意:Alice的某个朋友圈子位于一个单独的主机上
目前我们只对人群使用了这个概念,不过实际上在图谱中,这个概念也适用于其他类型的对象。对比尚未采用倒排索引的Dragon早期数据,使用这种方式能减少30%的存储使用与约7%的CPU使用。原因主要在于:使用正排索引的随机分布模式时,like Shakira的用户会占据大量的存储空间,而改成倒排索引后占用量大幅缩减。
Dragon引擎有两种用法:一个是针对在图谱中查询单个对象而做了优化的只索引(index-only)变体,分片方式与MySQL和TAO完全一致;另一种是针对朋友关系查询做了优化(“我做某事的好友”),这种用法十分常见。对于后者,我们需要一个聚合模块层,以及能将数据从一个分片方案切换到另一种方案的更新服务,需要依赖重演至少一次语义(at-least-once semantics)的分布式日志。
好友、like与评论是Facebook图谱中最常见的一些关系。我们尝试通过离线图谱分区技术(offline graph partitioning techniques)来使用这些内容。最初,我们对离线算法的尝试主要是基于好友关系对社交图谱进行均衡的分区。随着对扇出(模块直接调用的下级模块个数)的优化,在扇出降低三倍后,与随机分片服务相比,相应的平均延迟也随之降低。
图五:叶片扇出的延迟呈函数显示
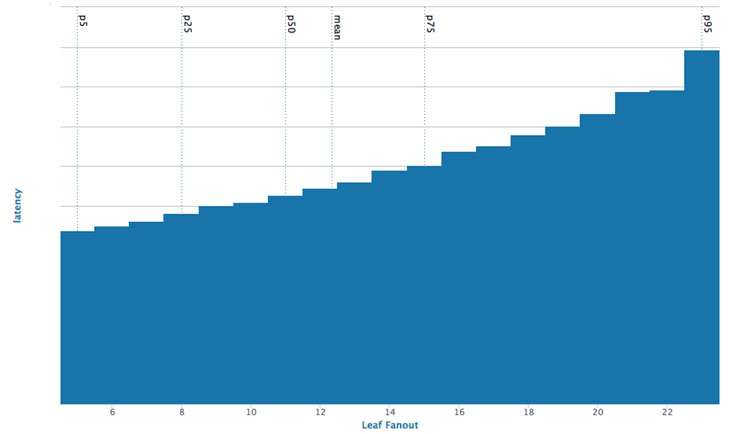
这种算法既是挑战也是机遇,由于查询时间与好友数量的关系并非线性,每批可处理的查询量比之前要多得多,使得效率提高。然而,总查询时间还要看速度最慢的查询,如果某个主机所用的响应时间几乎达到100毫秒,那么相对于10毫秒的响应时间来说,这就属于高延迟。使用多核机器的话,我们可以使用多个CPU执行并行查询,从而达到适当的均衡,并在合理的延迟范围内对大型查询予以响应。
函数式编程原语
Dragon支持20种左右简单易用的函数式编程原语,用以在图谱中表达边(关系)的筛选/排序,还支持被称为assoc的单个图谱导航原语。
例1:计算Alice20岁以上的好友数。
(->> ($alice) (assoc $friends) (assoc $friends) (filter (> age 20)) (count))例2:计算我的所有订阅组,根据成员数来排序,标注页数。
(->> ($me) (assoc $groups)
(->> (assoc $members) (count))
(orderby (count))
(limit $count $offset))在需要处理较复杂的字符串,或者需要正则表达式时,Dragon支持在Lua/JavaScript中使用自定义函数(UDFs)。
总结
以满足需求的进程内键值存储为支持,Dragon引擎能够实时更新,并保持一致性。它运用了大量的优化技术来保护存储、改善使用,查询可在1~2毫秒内执行,保障了极高的可用性与一致性。
尽管其中有些概念并不新鲜,但Dragon将其大规模结合,并以全新的方式将很多复杂的查询与存储信息放到了一起。它的结构更像是分布式数据库引擎:在尽可能高效地检索请求结果的同时,将排名数据存储在索引中。这样一来,应用就可以专注于解决业务逻辑、隐私、统计类型检验以及复杂的排名系统,而无需浪费大量时间斟酌检索图谱数据的最佳方式了。
原文地址:Dragon: A distributed graph query engine
作者:Arun Sharma
译者:孙薇
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









