






本文阐述了为什么比起Hadoop之类的知名技术,类似Apache Storm这样的系统更加有用。
让我们以经典的笔记本品牌实时情感分析(SENTIMENT ANALYSIS)为例,在进行观点分析时,处理流程应当如下图所示:
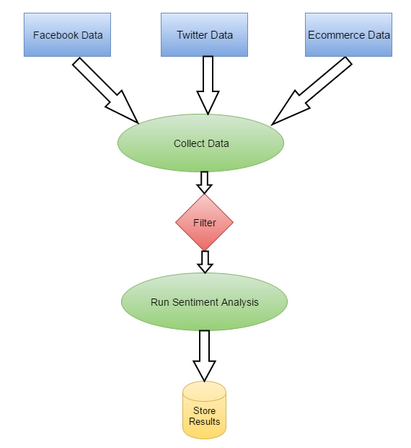
- 从类似Twitter、Facebook、电子商务网站之类的不同来源收集数据。
- 以一些“高吞吐量”这样的关键字为基础,我们筛选出了一些数据。
- 为不同来源的各条信息生成情感分析。
- 为存储处理的数据设立存储机制。
现在的问题在于:是否能够通过大数据系统来解决,请使用Hadoop来执行下列处理:
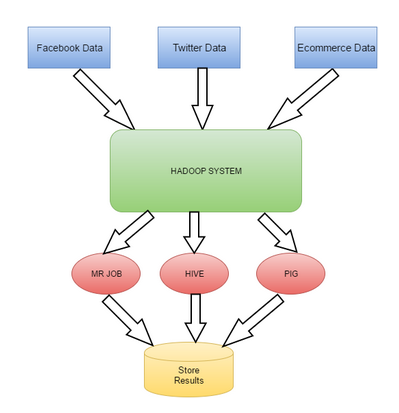
如果我们运行Hive Query、Pig Script或MapReduce的话,由于必须从HDFS(从硬盘读取)中读取数据,整个处理过程需要耗费数小时才能进行处理,因此理论上来说是无法实时执行数据处理的(它们遵循静态数据原则)。
由于Hadoop设计时就是为了执行批处理,而且需要花费数小时才能生成结果,因此针对Hadoop是否能够执行实时处理的问题,答案是否定的。
总结一下,由于所使用的是基于批处理的方式,Hadoop无法解决实时问题。
有很多需要我们执行实时数据处理的用例,比如:
- 反欺诈
- 情绪分析
- 日志监控
- 处理客户的行为
那么现在我们如何处理这类特殊的问题呢?我们需要使用一些实时的流数据机制(一切都在内存中完成,遵循动态数据原则)。
实时处理的典型流程如下图:
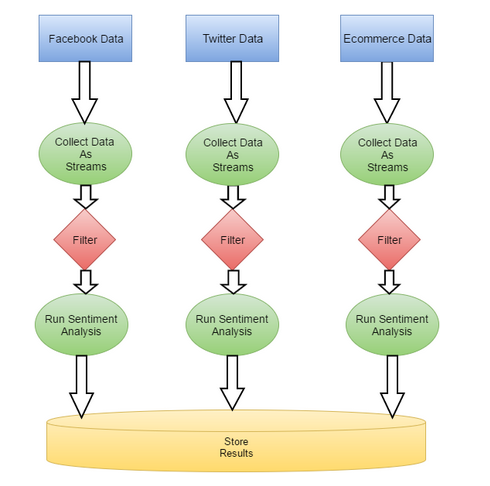
不过想要使用这种方法,需要先解决下面这些问题:
- 数据流:数据需要在数据管道(Data Pipeline)中以流数据的形式发送。
- 容错:如果有某个进程出错,那么故障转移机制是什么样的呢?
- 扩展:如果数据规模增长的话,能否很容易地扩展集群以增加处理数据的性能?
- 确保信息处理:是否能确保信息得到处理?
- 编程语言不可知论:是否会是独立的编程?
有一些类似Apache Storm之类的实时数据流机制能够帮助我们解决这些问题。现在我们试着回答上面的问题,看使用Apache Storm能否得出答案。
数据流
数据以元组的形式发送。
扩展
Storm是一个分布式平台,允许用户将更多节点添加到Storm集群运行环境中,以增加应用的吞吐量。
容错
在Storm中,工作是通过集群中的worker来执行的。如果有一个worker宕掉,Storm就会重启该worker,而如果worker所在的节点也宕掉,则Storm就会重启集群中一些其他节点上的worker。
确保信息处理
Storm如果该元组在处理时出现故障,Storm会重启出错的元组。
程序语言不可知论
可以在任何编程语言中编写。即使Storm平台运行在JVM之上,运行在上面的应用也可以用任何编程语言编写,可以使用标准的I/O来读写。
希望本文有助于澄清:利用Apache Storm之类的工具处理大数据问题时,在实时流数据中的使用问题。
原文:Use Cases for Real Time Stream Processing Systems
译者: Vera
责编:钱曙光















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









