






作者:张炎泼,白山云合伙人兼研发副总裁,曾就职于新浪、美团云等。目前主要负责白山云科技对象存储研发、数据跨机房分布和修复问题解决等工作。以实现100PB级数据存储为目标,其带领团队完成全网分布存储系统的设计、实现与部署工作,将数据“冷”“热”分离,使冷数据成本压缩至1.2倍冗余度。
上篇:《XP的分布式系统下的纠删码技术之Erasure Code》
Erasure-Code(简称EC,也称擦除码或纠删码)是1组数据冗余和恢复算法的统称。本教程以Vandermonde矩阵的Reed-Solomon来解释 EC原理。
术语定义:

本教程包括:
- 分布式系统的可靠性问题:冗余与多副本——提出EC需要解决的问题;
- EC的基本原理:用到中学数学知识,举“栗子”的方式直观解释EC算法,希望对分布式存储领域增加了解的同学,可只阅读该部分;
- EC编码矩阵的几何解释:解释EC编码矩阵的原理和含义,希望深入了解EC数学原理的读者,可从此部分开始;
- EC解码过程:求解n元一次方程组;
- 新世界:伽罗华域 [Galois-Field] GF(7)
- EC使用的新世界 [Galois-Field] GF(256)
(以上两节介绍EC在计算机上的应用方法) - 实现:对工程实践方面感兴趣的同学可参考;
- 分析:需要规划存储策略的架构师可参考。
本文将对5-8章节进行介绍,1-4章节已在白山微信公众号(baishancloud)推送。
新世界: 伽罗华域Galois-Field GF(7)
实际使用中,EC并不像前篇有理数计算那么简单,所有算法在实现中都会面临一个问题:在计算机上实现必须考虑空间问题。计算机中不能天然表示任意自然数,校验块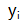
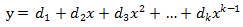
如果数据块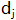
上面介绍的EC,在计算机上实现时必须解决数字大小问题,但整体算法思路不变。现在开始从最底层入手,解决这个问题。
这里所说的最底层是指曲线。多元一次方程等依赖的是底层的四则运算法则。我们需要找到另外一套运算法则:既满足EC计算需要,又能控制数值范围,将EC移植到另一套代数结构上。
这也是本人在学习EC时觉得最有趣的地方:
类似于把一段C代码写好后,既可以编译到intel CPU上,也可以编译到ARM CPU上运行(即使这2种CPU的指令完全不同,但C源代码的正确性是不变的)。
设计好EC上层算法后,将它移植到另1套代数体系中,同时需要保证上层“源代码” 在该不同的底层体系上也可正确运行。
EC在计算机上的实现: 基于伽罗华域Galois-Field
上一篇提到的数学公式,之所以能正确工作,是因为依赖于一套底层基础运算规则,即四则运算(实现EC的代数中,未用到开方运算)。
不使用四则运算,还可以使用什么?
其实广为人知的四则运算,在代数中并不是唯一的运算法则,它有很多个兄弟,它们有共同的规律和不同表现形式。
例如:可能存在1种四则运算,其建立的代数关系是: 5+5=3而不是10,5×3=1 而不是15。也可能存在1种四则运算,乘法并非加法的叠加。
最常见的是时间相加:20:00加8个小时不是28:00,而是4:00。
我们现在需要做的是:找到一种四则运算,让EC计算不越界!
现在让我们一步步开启这扇新世界大门。
首先感谢19世纪因与情敌决斗被一枪打死的伟大数学家——伽罗华。
栗子3:只有7个数字的新世界: GF(7)
大门,慢慢开启…
我们尝试定义一个新的加法规则,在新世界GF(7)中只有0~6这7个数字:其他整数需要被模7,变成0~6的数字。
在这个新世界中,四则运算也可以工作:
新世界GF(7)中的加法
新的加法被表示为⊕(原始加法仍用+来表示):
定义为:a⊕b的结果是a + b后再对7取模,例如:
1⊕1 = 2
5⊕2 = 0 ( 7 % 7 = 0 )
5⊕5 = 3 ( 10 % 7 = 3 )
在新世界GF(7)中,0 还是和以前很相像:任何数与0相加都不变。
0⊕3 = 3
2⊕0 = 2
0被称为加法的单位元。
新世界GF(7)中的减法
减法的定义很直接,是加法的逆运算。
在自然数中,-2 + 2 = 0,我们称-2是2在加法上的逆元(通常称为相反数)。在新世界GF(7)中,很容易找到每个数的加法逆元,例如: 3⊕4=0,所以4和3互为加法的逆元,或者说是(新世界的)相反数。
减法可定义为:a⊖b→a⊕(−b)
例如:
3⊖4 = 6 ( (-1) % 7 = 6 )
2⊖6 = 3 ( (-4) % 7 = 3 )
新世界GF(7)中的乘法和除法
新世界GF(7)中,也可以类似地定义乘法:
例如:
1⊗5 = 5 ( 5 % 7 = 5 )
3⊗4 = 5 ( 12 % 7 = 5 )
2⊗5 = 3 ( 10 % 7 = 3 )
0⊗6 = 0
对于新世界GF(7)的乘法来说,1是乘法的单位元,即1⊗任何数都是其本身。
也可以用类似的方法定义每个数字在乘法⊗的逆元:
例如:
3−1=5(3×5%7=1)
4−1=2(4×2%7=1)
除法的定义就是:乘以它的乘法逆元
栗子4:新世界GF(7)直线方程-1
定义了新的加法⊕和减法⊖,就可以像使用旧世界的加减法一样运算。例如:可以建立一个简单的、斜率为1的直线方程:
这个直线上的点是:(x,y)∈[(0,3), (1,4), (2,5), (3,6), (4,0), (5,1), (6,2)]。

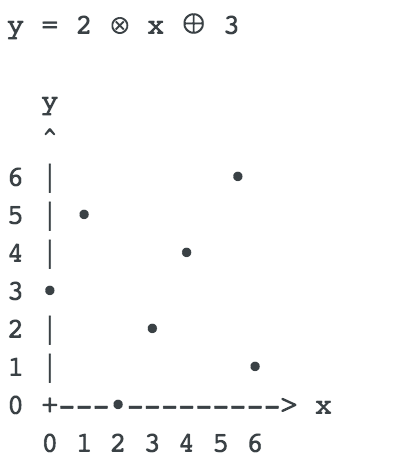
栗子5:新世界GF(7)直线方程-2
使用新世界的四则运算,可以在新世界GF(7)进行基本代数运算。例如:可设定一个斜率为2的直线方程:
这个直线上的点是:(x,y)∈[(0,3), (1,5), (2,0), (3,2), (4,4), (5,6), (6,1)]。
栗子6:新世界GF(7)中的二次曲线方程
下面我们建立一个稍复杂的二次曲线的方程:
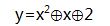
(这里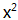
这个抛物线上的点集合是:(x,y)∈[(0, 2) (1, 4) (2, 1) (3, 0) (4, 1) (5, 4) (6, 2)]

该图像也遵循旧世界抛物线的特性:这条抛物线以x=3为轴对称。类似旧世界的多项式分解,原方程也可以分解成:
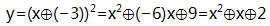
新世界GF(7)中的EC
现在可以使用上面提到的EC的算法来编码或解码:
假设新世界GF(7)中,数据块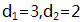
只要记住2个点的位置,就能把直线方程恢复出来:
例如:
- 记录直线上2个点: (1,5)和(3,2)
- 假设丢失的数据是
,用
表示,带入2个点的坐标,得到一个二元一次方程组:
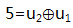
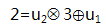
得到:
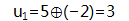
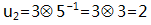
至此,应用新世界GF(7)的四则运算实现了之前的EC,同时保证了校验数据的大小可控:不会大于7!
类似的,可以通过新世界GF(7)的抛物线,实现k=3, k=4的EC。
NOTE:
模7下的四则运算构成了1个伽罗华域 Galois-Field: GF(7)。模7是1个可选数,也可以选择模11或其他质数来构造Galois-Field,但不能选择合数。
假设在新世界GF(6)中,2是6的一个因子,没有乘法逆元,即2乘以1~5任何一个数字在新世界GF(6)中都不是1。
没有乘法逆元说明该世界中没有与旧世界一样的除法,不能构成完整的四则运算体系。
为简化本文,四则运算中还有几方面并未提到,如乘法加法分配律。
乘法和加法的结合律也必须满足,才能在新世界实现上述例子中的曲线方程等元素。这部分也容易验证:在新世界GF(7)中可以满足。
现在有了EC的算法,以及多个可选择的四则运算来限定数值范围。要在计算机上实现还需要最后一步,即:模7虽可取,但因为计算机中应用二进制,模7无法对计算机中的数字有效利用。 把数值限定到7或其他质数上,无法有效利用256或65536这样的区间。
接下来需要选择一个符合计算机二进制的四则运算,作为实现EC计算的基础代数结构。
EC使用的新世界Galois-Field GF(256)
现在我们要构造一个现实中可以真正使用的伽罗华域,相较于新世界GF(7)稍复杂:
- 首先选择1个基础的、只包含2个元素的Galois-Field GF(2):{0, 1};
- 在 GF(2)基础上建立1个有256个元素的 Galois-Field GF(
)
模2的新世界: Galois-Field GF(2)
首先构建基础的四则运算:
加法(刚好和位运算的异或等价):
0⊕0 = 0
0⊕1 = 1
1⊕0 = 1
1⊕1 = 0
1的加法逆元即1本身。
乘法(刚好和位运算的与等价):
0 ⊗ 0 = 0
0 ⊗ 1 = 0
1 ⊗ 0 = 0
1 ⊗ 1 = 1
1的乘法逆元是1本身;0没有乘法逆元;
以GF(2)为基础已经可以构建一个1-bit的EC算法了。
下一步我们希望构建1个1byte大小(
0~9这10个自然数通过增加“进位”概念后扩展成能表示任意大小的多位十进制自然数,通过类似的方法可以把{0,1}这个GF(2)引入多项式:
使用GF(2)的元素作为系数,定义1个多项式:
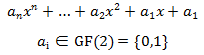
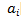
多项式的加法:
- 因为 1 + 1 = 0,所以:
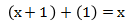
- x同指数幂的系数相加遵循系数的Field的加法规则,则有:
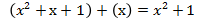
- 2个相同的多项式相加肯定为0:
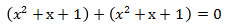
多项式的乘法:
和旧世界多项式乘法类似,仍通过乘法分配律展开多项式:
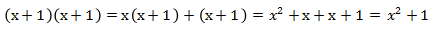
多项式的除法:
依旧使用旧世界的多项式长除法法则,唯一不同的仍旧是系数的四则运算是基于GF(2)的:
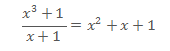
多项式的除法取余计算也类似:
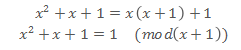
把GF(2)应用到多项式系数上,得到包含无限多个元素的多项式集合(不是伽罗华域,缺少除法逆元;类似的,整数全集也不是一个伽罗华域,它也缺少除法逆元)。
这些多项式和二进制数有一一对应关系,多项式中指数为i的项系数就是二进制数第i位的值:
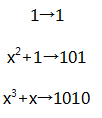
接下来可以使用多项式表达的二进制整数的全集。类似栗子中的GF(7),取模后利用多项式的集合构造1个取模的伽罗华域。
类似的,需要1个质的多项式(Prime-Polynomial),替代GF(7)中7的角色,并应用到GF(2)为系数的多项式的集合中,最终得到1个有256个元素的多项式的伽罗华域 GF(
首先让我们来熟悉下如何从较小的域扩张到较大的域。
域的扩张Field-Extension
栗子7:实数到虚数的扩张
例如:以实数为系数的多项式中,如果选择一个多项式来构造方程:
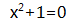
这个方程在实数域里无解,但在复数范围内有解的:
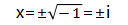
通过一个实数系数、但在实数域中无根的方程,得到了复数Complex-Number的定义:
复数就是: 所有实系数多项式模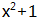
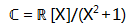
上面所有的余多项式可表示为:ax+b(a,b都是实数)。
这里ax+b就是我们熟悉的复数:多项式x对应虚数单位i,1对应实数单位1。
而任意2个多项式的四则运算也对应复数的四则运算,如:设:
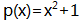

类似于将实数扩张到复数, 也可以将GF(2) 扩张到 GF(
从2到256: 扩张 GF(2)
域的扩张就是在现有域为系数的多项式中,找到1个质的多项式Prime-Polynomial,再将所有多项式模它得到的结果的集合就是域的扩张。
例如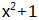
栗子8:GF(2)下的质多项式
- 1是质多项式。
- x+1是质多项式,因为它最高次幂是1,不能再拆分成2个多项式乘积(只能拆分成1次多项式和常数的乘积)。
是2次的质多项式,在GF(2)的域中不能被拆分成2个1次多项式的乘积。
可以像使用7对所有整数取模一样,用它对所有多项式取模,产生的所有余多项式,包含所有最高次幂小于2的4个多项式:0,1,x,(x+1)
这4个多项式就是GF(2)在多项式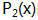
这4个多项式可以表示成4个2bit的二进制数:00,01,10,11
GF(2)扩张成GF(
为了扩张到 GF(
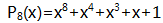
这个8次幂的质多项式,模它的所有余多项式,是所有最高次幂不超过7的多项式,共256个。它就是GF(2)到GF(256)的扩张,扩张后的元素对应0~255这256个二进制数。
因为多项式和二进制数的直接对应关系,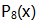
- 二进制: 1 0001 1011
- 16进制: 0x11b
GF(256)中的四则运算如下:
- 加法:a⊕b对应多项式加法,同时表示二进制数的加法对应
- 乘法:a⊗b对应多项式的乘法(模
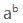
总结:GF(256)能满足EC运算的以下几个性质:
- 加法单位元:0
- 乘法单位元:1
- 每个元素对加法都有逆元,逆元就是本身( (x+1) + (x+1) = 0 )
- 每个元素对乘法都有逆元(除了0),
不可约,因此不存在a和b都不是0,但ab=0;又因为GF(256)只有255个非0元素,因此对a总能找到1个x使得
。所以
是a的乘法逆元。
- 乘法和加法满足分配律:基于多项式乘法和加法的定义。
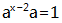
满足这些性质的四则运算,就可以用来建立高次曲线,进而在GF(256)上实现EC。
实现
标准EC的实现
以上讨论的是标准EC的原理,现在将以上内容总结,应用到实践。
- 四则运算基于 GF(
)、GF(
),分别对应1字节、2字节、4字节。
- GF(
- GF(
首先生成 GF(
以 GF(
- 生成指数表,表中元素
- 生成对数表,表中元素
- 生成指数表,表中元素
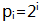
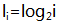
生成2个表的代码很简单,用Python表示如下:

指数表:

对数表(0没有以2为底的对数):

计算 GF(
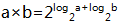
NOTE:
Galois-Field 的计算目前实现都是基于查表的,所以选择大的域虽然可以一次计算多个字节,但内存中随机访问一个大表也可能会造成cache miss太多而影响性能。
一般CPU都没有支持GF乘除法的指令,但有些专用的硬件卡可加速GF乘除法。
- 生成GF后,选择一个系数矩阵,常用Vandermonde或Cauchy。
- EC编码:校验数据生成
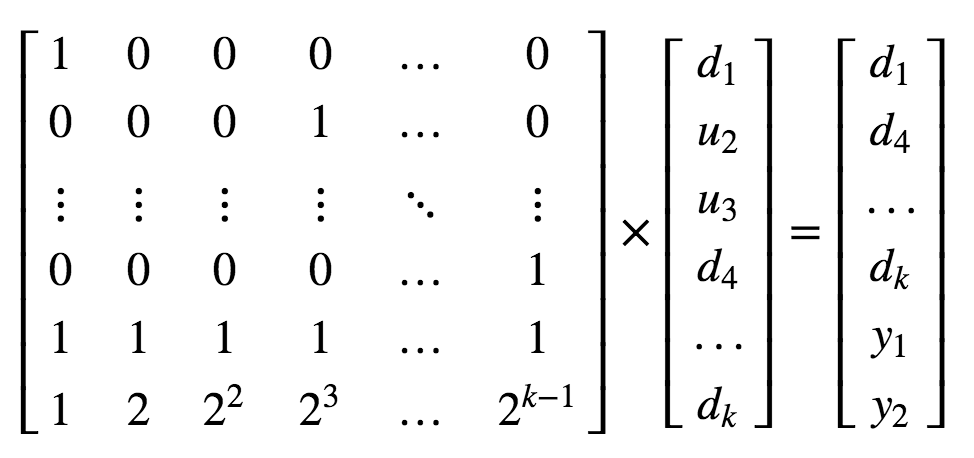
通常使用矩阵表示输入和输出的关系(而不像上文中只使用校验块的生成矩阵),这里选择自然数生成的Vandermonde矩阵:
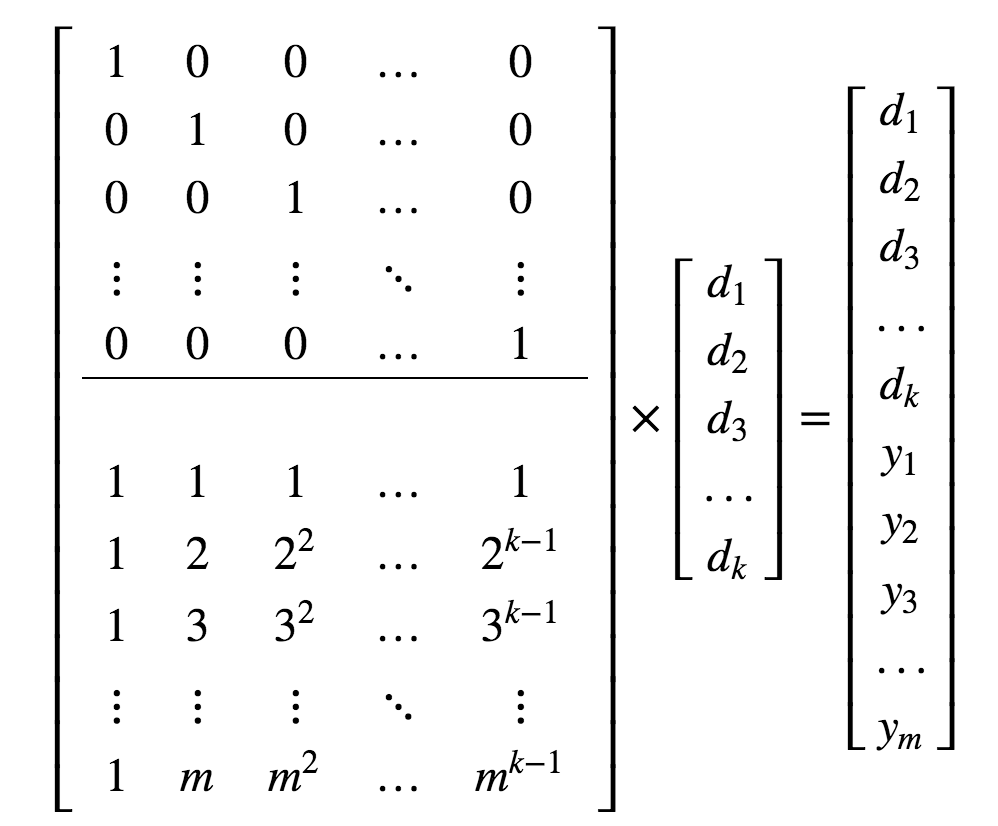
这个矩阵里上面是大小为k的单位矩阵,表示
下面一部分是m×k的矩阵表示校验块的计算。
对要存储的k组数据逐字节读入,形成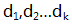
把单位矩阵也放到编码矩阵上面,看起来只是把输入无变化的输出出来。实际上,在编码理论中,并不是所有生成的Code都是k个原始数据和m个校验数据的形式,有些编码算法是将k个输入变成完全不一样的k+m个输出。对这类编码算法需要1个k*(k+m)的编码矩阵来表示全部转换过程。例如著名的 Hamming-7-4 编码的编码矩阵(输入k=4,输出k+m=7):

- EC解码:数据损坏时,通过生成解码矩阵来恢复数据
对所有丢失的数据,将它对应的第i行从编码矩阵中移除,保留编码矩阵的前k行,构成1个k*k的矩阵。
例如:第2、3个数据块丢失,移除第2, 3行,保留第k+1和k+2行:此时矩阵中,数据块(未丢失的和已丢失的)、未丢失的数据块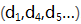
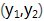
最后求逆矩阵,与未丢失的块相乘,就可以恢复出已丢失数据块 

因为只有
数据恢复IO优化: LRC [Local-Reconstruction-Code]
EC数据恢复时,需要k个块参与数据恢复。直观上,每个数据块损坏都需要k倍IO消耗。
为缓解这个问题,一种略微提高冗余度、但可大大降低恢复IO的算法被提出——[Local-Reconstruction-Code],简称 LRC。
LRC思路很简单,在原来EC基础上,对所有数据块分组对每组再做1次 k′+1的 EC。k’是二次分组的每组的数据块的数量。
LRC的校验块生成
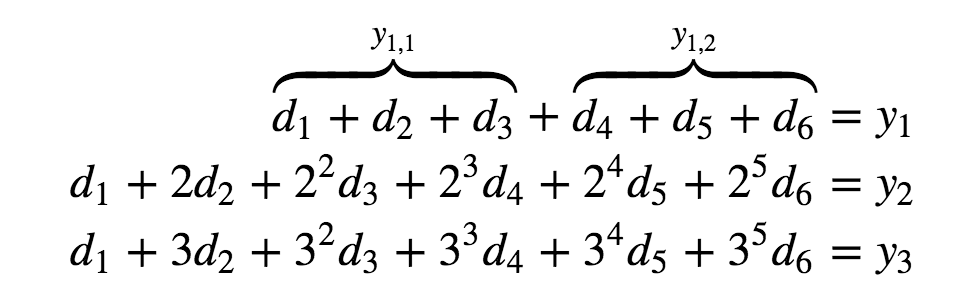
最终保存的块是所有数据块:
不需要保存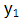
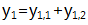
对于LRC的EC来说,生成矩阵前k行不变,去掉标准EC第k+1行,多出2个局部校验行:

LRC的数据恢复
LRC的数据恢复和标准EC类似,只有2点不同:
选择校验块的行生成解码矩阵时,如果某第k+i行没有覆盖到任何损坏的数据,则无法提供有效性信息,需要跳过。
例如:
损坏时,不能像标准EC一样选择第7行 1 1 1 0 0 0 作为补充的校验行生成解码矩阵,必须略过第7行,使用第8行。
不是所有情况下,m个数据损坏都可以通过加入m个校验行来恢复。因为LRC生成矩阵没有遵循Vandermonde 矩阵的规则,不能保证任意k行满秩。
分析
可靠性分析
可靠性方面,假设EC的配置是k个数据块、m个校验块。根据EC的定义:k+m个块中,任意丢失m个都可找回,这个EC组丢失数据的风险就是丢失m+1个块或更多的风险:
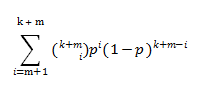
p是单块数据丢失的风险,一般选择磁盘的日损坏率-大约为0.0001。p一般很小,所以近似就只看第1项:
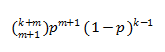
2个校验块和3副本可靠性对比:

3个校验块和4副本可靠性对比:
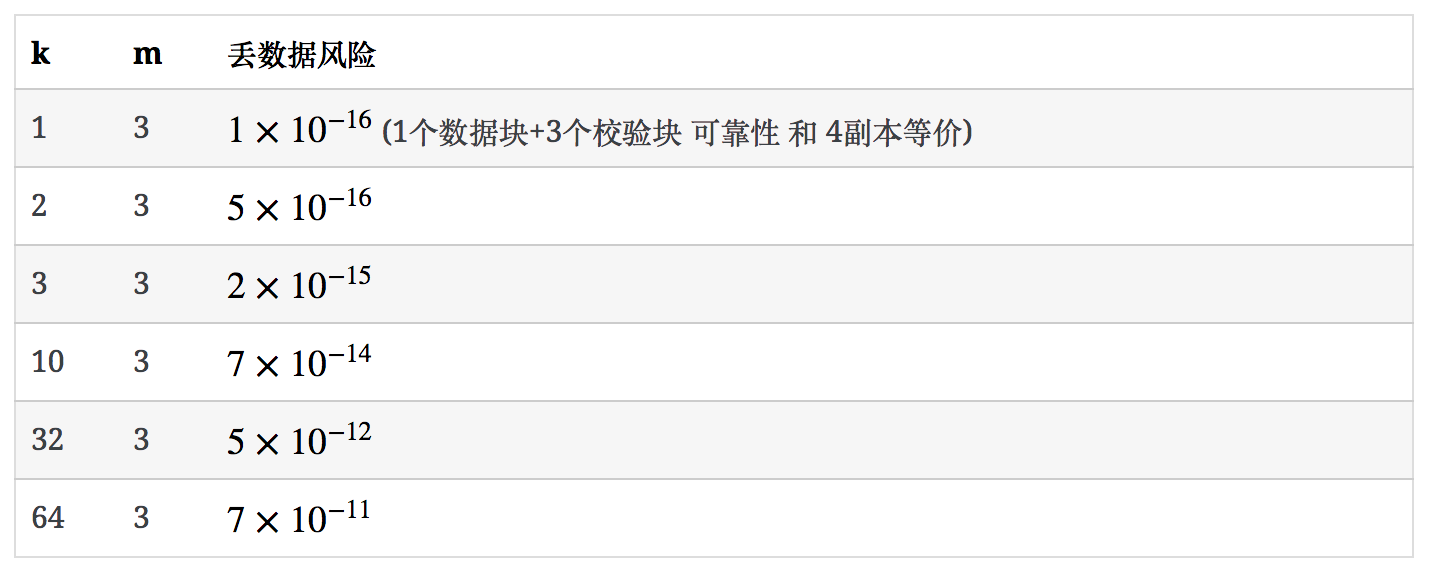
4个校验块和5副本可靠性对比:

IO消耗
以一个EC组为例来分析,1个块损坏概率是p,这个组中有块损坏的概率是:
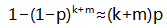
每次数据损坏都需要读取全组数据恢复。不论1块或者多块损坏,数据恢复都需要读取1次,输出1或多次。恢复数据的输出比较小,一般是1,可忽略。
每存储一个字节一天数据恢复产生的传输量是:
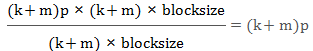
(blocksize是一个数据块或校验块的大小)
即:使用EC每存储1TB数据,每天用于数据恢复而产生的IO是k*0.1GB/TB
磁盘IO大致上也等同于网络流量,因为大部分实现必须将数据分布到不同服务器上。
NOTE:
随着 k增加,整体成本虽会下降(1+m/k),但数据恢复的IO开销也会随k(近似于)线性增长。
例如:
假设k+m = 12
如果整个集群有100PB数据,每天用于恢复数据的网络传输是100TB。
假设单台存储服务器的容量是30TB,每台服务器每天用于数据恢复的数据输出量是30GB,如果数据恢复能平均到每天的每1秒, 最低的带宽消耗是:30GB/86400 sec/day=3.0Mbps。
一般来说数据恢复不会在时间上均匀分布,带宽消耗需要预估10到100倍。















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









