






想要使用爬虫爬取网站上的资源首先需要导入三个库
分别是: requests re os
导入库之后就可以开始进行学习了
基本代码有关部分
第一步.获取网络源代码
def get_html(url,headers,params):
response = requests.get(url,headers=headers,params=params)
# 设置源代码的编码方式
response.encoding="utf-8"
if response.status_code == 200:
return response.text
else:
print("网站源码获取错误")
第二部.提取图片源代码
def parse_pic_url(html):
result = re.findall('thumbURL":"(.*?)"',html,re.S)
return result第三步.获取图片二进制源码
def get_pic_nic_content(url):
response = requests.get(url)
return response. Content
第四步.保存图片
def save_pic(fold_name,content,pic_name):
with open(fold_name+"/"+str(pic_name)+".jpg","wb")as f:
f.write(content)
f.close()
第五步.定义一个新的文件夹程序
def create_fold(fold_name):
# 加异常处理
try:
os.mkdir(fold_name)
except:
print("文件夹已存在")
网页有关部分
第一步.获取url
这里我选择爬取百度图片中的大熊图片,打开百度图片,搜索大熊猫
打开网页后右击鼠标,选择检查
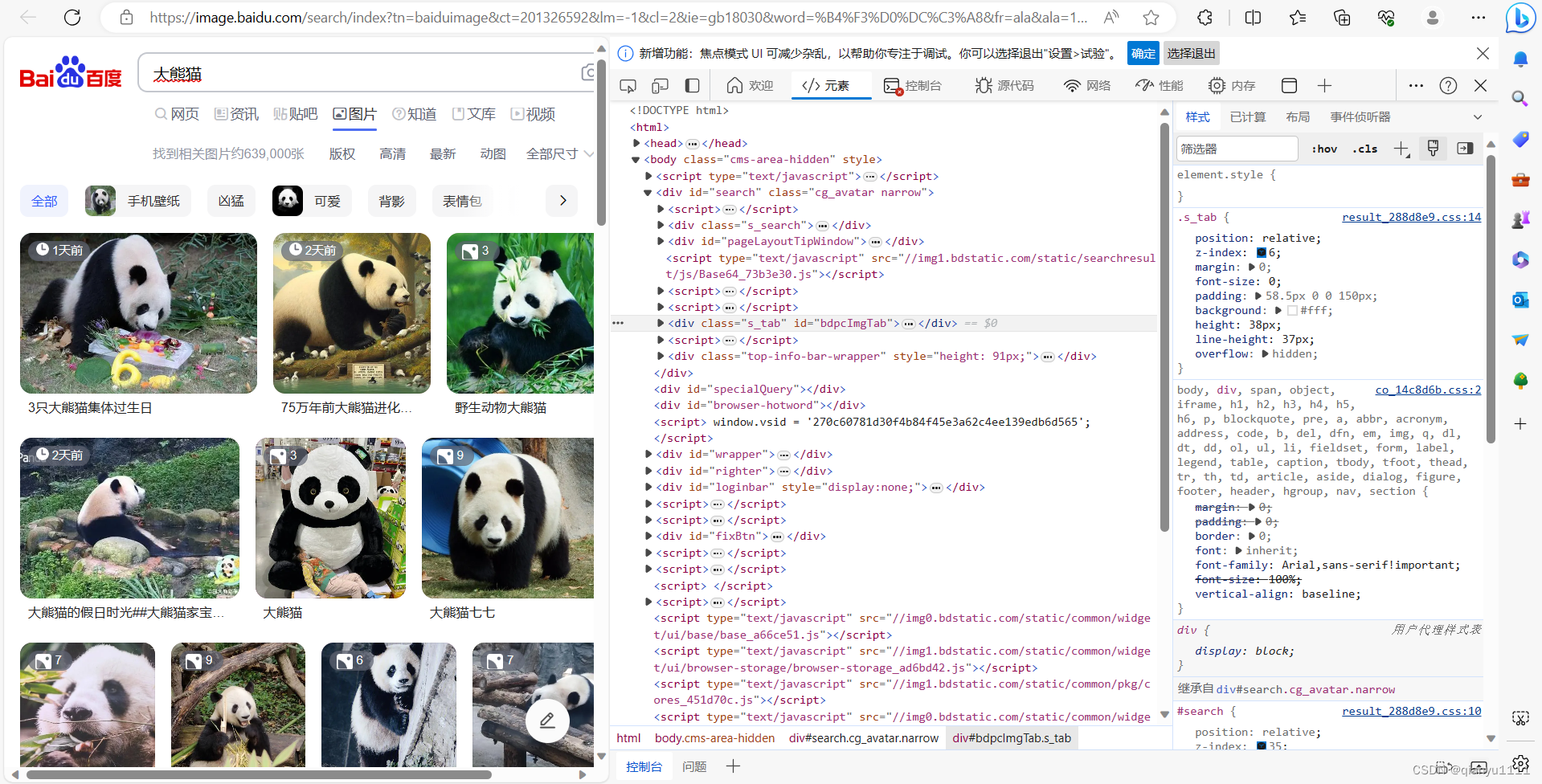
点击网络后选择Fecth/XHR
之后刷新网页将鼠标在图片上移动就会出现以下情况
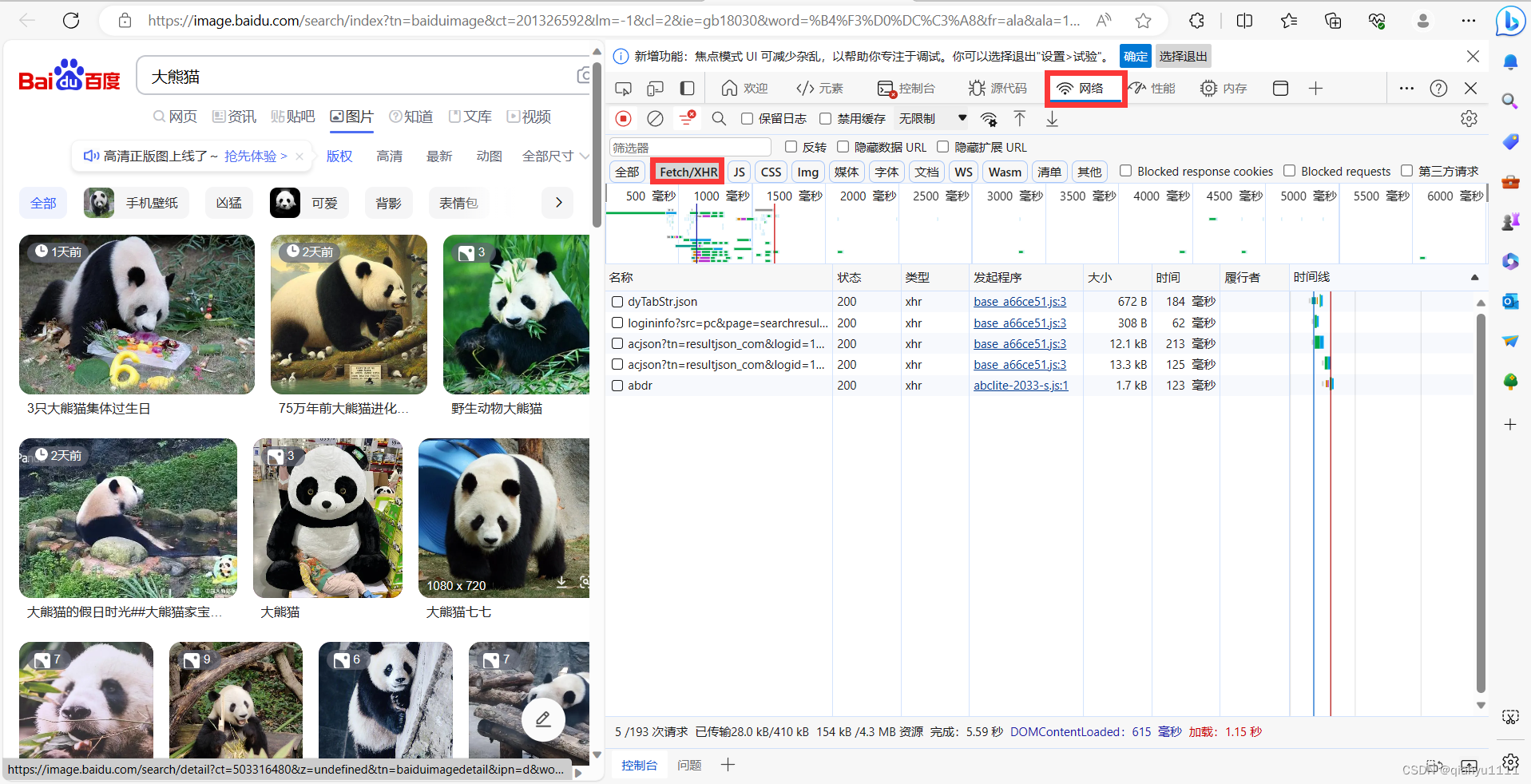
之后选择头标为 acjson 按图片中指示进行操作
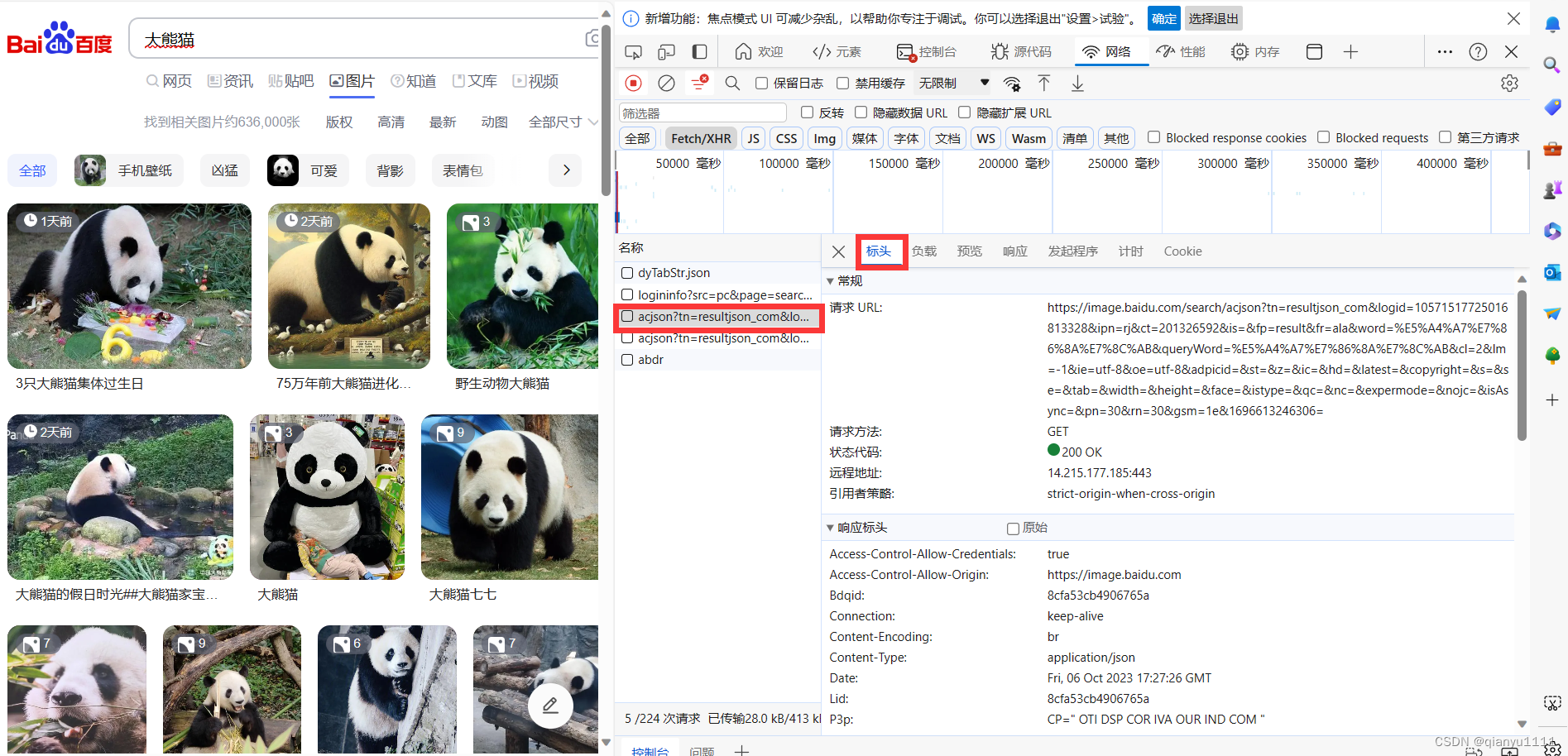
之后复制图片圈住内容就可以了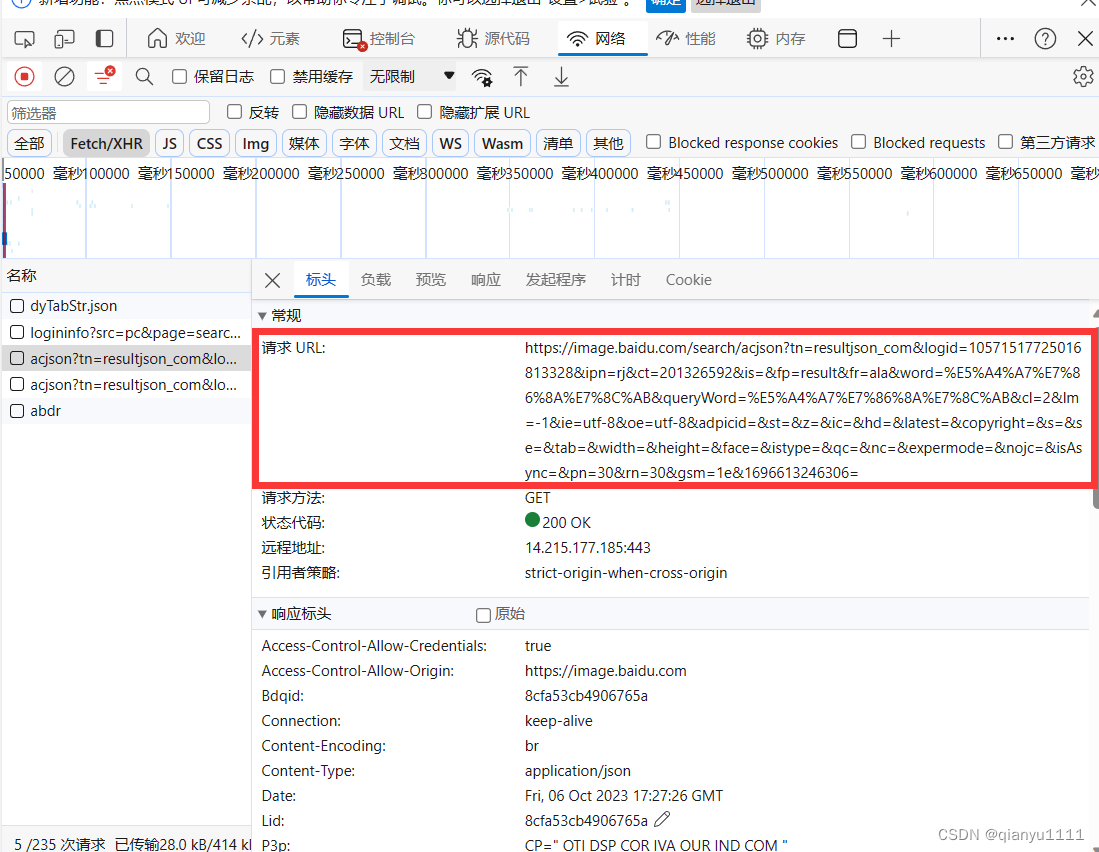
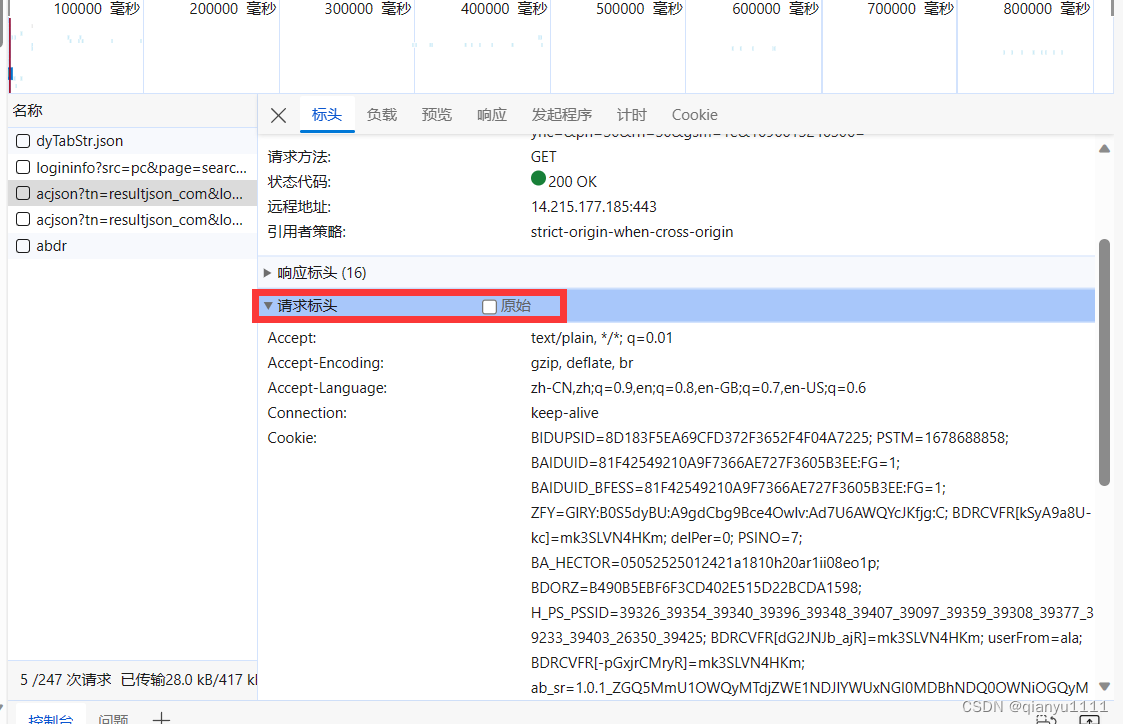
第二部.获取 headers
可以接着上一步进行,
按图片操作,复制即可获得headers
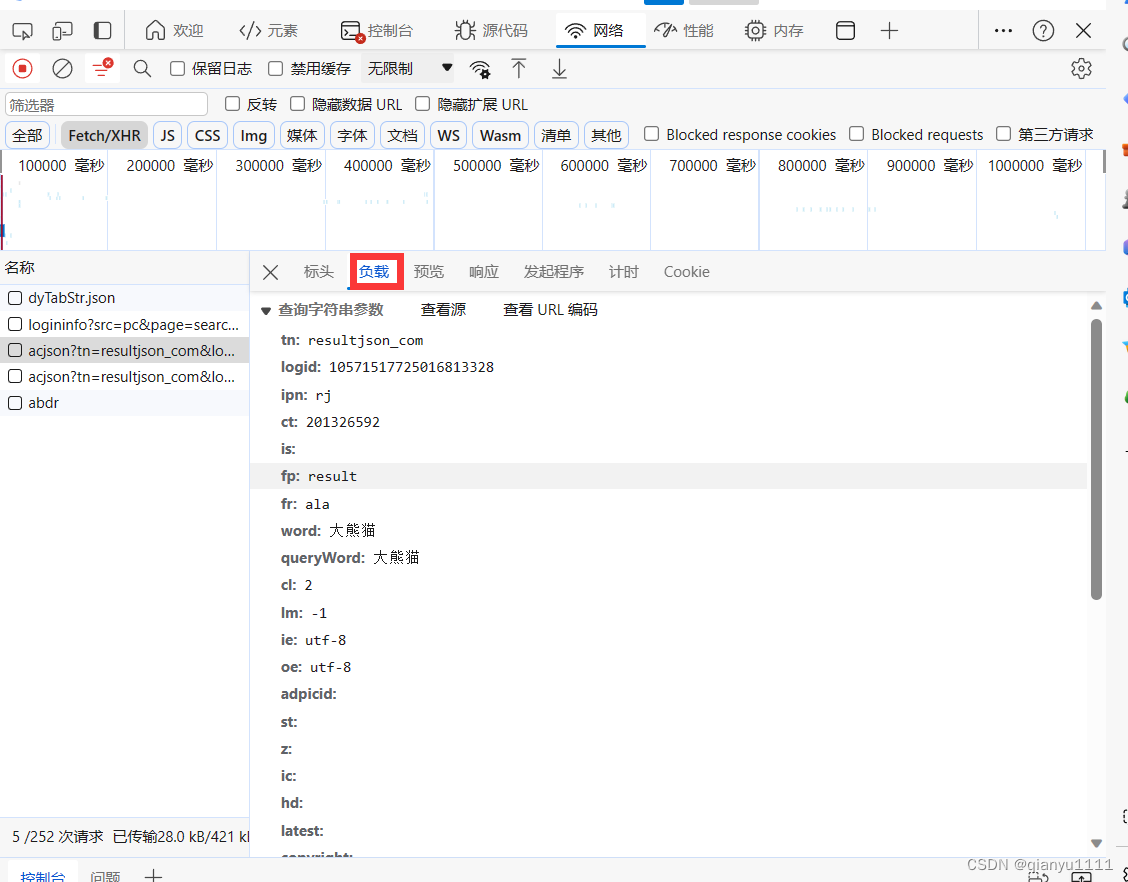
第三步.获取 params
还是可以接着操作,点击负载,复制所有内容即可
main主函数部分
在写好了基本代码,获取了url,headers,params之后我们就可以开始编写主函数了
def main():
# 输入文件夹名字
flode_name = input("请输入您想要爬取的图片的名字:")
# 输入要抓取的图片页数
page_num = input("请输入要抓取的页数(0,1,2,3,4,5,6,.....)")
# 调用函数创建文件夹
create_flode(flode_name)
# 构建循环
pic_name = 0
for i in range(int(page_num)):
url=""
headers = {
}
params = {
}
html = get_html(url, headers, params)
# print(html)
result = parse(html)
for item in result:
# 调用函数获取图片二进制源码
pic_contont = get_pic_content(item)
# 调用函数保存图片
save_pic(flode_name,pic_contont, pic_name)
pic_name += 1
print("已保存第" + pic_name.__str__() + "张图片")
将获取到网页信息分别复制到代码中,其中headers,params需要转换为字典形式
如图所示
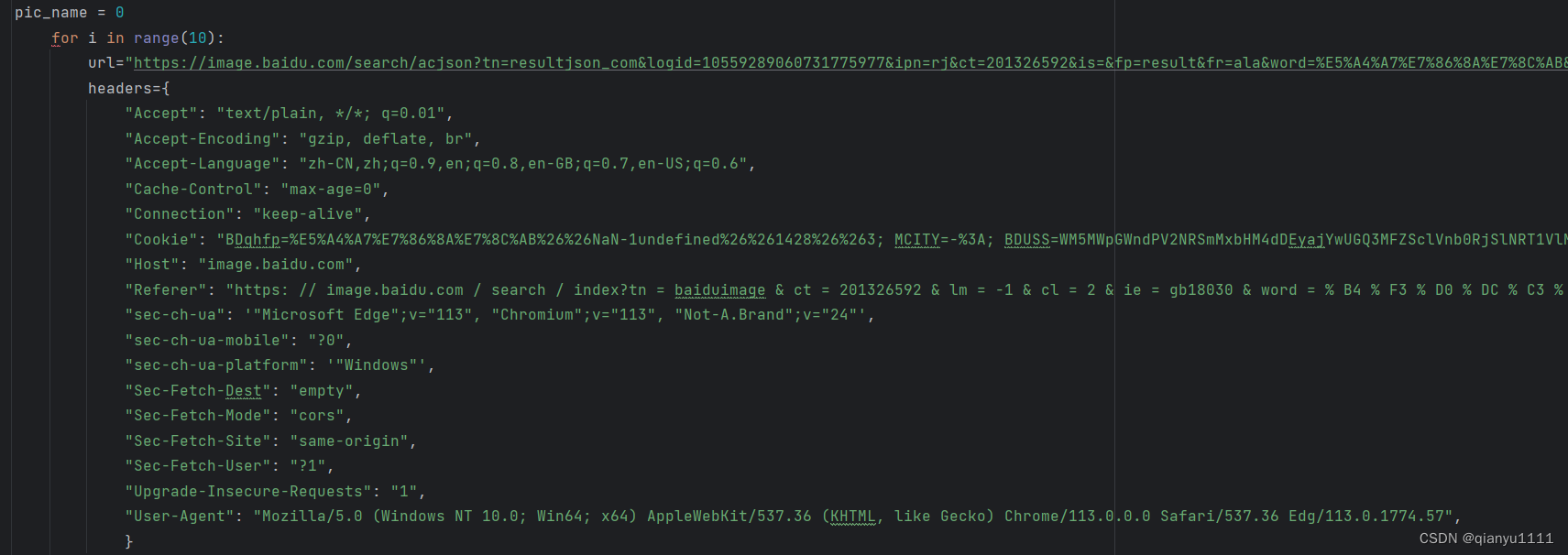
 (params中无内容部分可删除)
(params中无内容部分可删除)
再按照图片中的操作更改params的内容

这样就可以爬取图片了,谢谢观看。















 5647
5647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









