







谈到神经网络,就不得不提到最近非常火的深度学习。那么什么是深度学习?它与神经网络的关系是什么?深度学习的基本原理和常用算法是什么?我将在这篇中详细解答。
- 什么是深度学习
深度学习来源于人工神经网络,它的思想是组合低层次的特征从而构建出更加抽象的深层次特征。深度学习的概念由Hinton等人于2006年提出,
它是一个新的机器学习领域,通过更“深”层次的训练,它可以更加良好的模拟人脑运作,实现复杂的如图像、语音识别。
深度机器学习方法也有监督学习与无监督学习之分,不同的学习框架下建立的学习模型很是不同。例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。
深度学习来源于神经网络,神经网络曾经在很长一段时间里停滞不前,主要原因是参数复杂难以最优化,此外在层次较少的情况下并没有比其他算法有优势,层数多了又导致训练非常慢,因此应用不那么广泛。
- 神经网络与深度学习的异同
相同点
深度学习模型继承了神经网络的分层结构,将整个网络分成输入层、隐含层、输出层三个部分,层与层之间有连接关系。
不同点
①因为深度不同导致特征处理思路不同
传统的前馈神经网络能够被看做拥有等于层数的深度(比如对于输出层为隐层数加1)。SVM的深度可以看做2(一个对应于核输出或者特征空间,另一个对应于所产生输出的线性混合)。和深度学习模型的层数比是比较少的。
神经网络在有限样本和计算单元情况下对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受到一定的制约。而且由于层数较浅,必须人工的选取特征,由于缺乏特征选取的经验,特征选择就成了制约模型性能的关键因素。深度学习思想就是通过多层次模型,自动的学习数据的特征,这样不仅能最大程度的保持原有的重要信息,也可以让模型效果更好。
②网络训练方式不同
神经网络的效果不好一个很重要的原因是采用了梯度下降的思路,如BP网络,误差随着网络向前传播,层数越高,误差会越小,难以对参数修改起到足够作用。深度学习为了克服这个问题,采用层次化训练的思路。首先逐层构建单层神经元,每次只训练一个单层的网络,然后最后使用wake-sleep算法进行调优。
深度学习将除最顶层的其它层间的权重变为双向的,这样最顶层仍然是一个单层神经网络,而其它层则变为了图模型。向上的权重用于“认知”,向下的权重用于“生成”。然后使用Wake-Sleep算法调整所有的权重。让认知和生成达成一致,也就是保证生成的最顶层表示能够尽可能正确的复原底层的结点。
准确地说,深度学习首先利用无监督学习对每一层网络进行逐层预训练(Layerwise Pre-Training);每次用无监督学习只训练一层,并将训练结果作为更高一层的输入;最后用监督学习去调整所有层。
- 受限玻尔兹曼机
受限玻尔兹曼机(Restricted Boltzmann Machine,简称RBM)是由Hinton和Sejnowski于1986年提出的一种生成式随机神经网络(generative stochastic neural network)。RBM 只有两层神经元,一层叫做显层 (visible layer),由显元 (visible units) 组成,用于输入训练数据。另一层叫做隐层 (Hidden layer),相应地,由隐元 (hidden units) 组成,用作特征检测器 (feature detectors)。如下图:
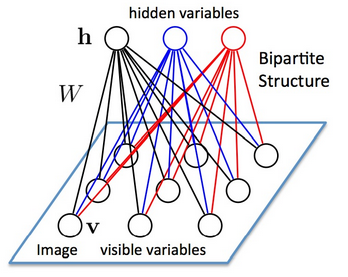
层与层之间的节点存在连接,但是同一层之间的神经元没有连接。上面一层是隐含层,我们用h表示;下面一层是可视层,我们用V表示,如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。
由于同一层之间没有连接,因此,每个节点之间是独立的。
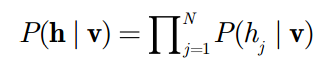
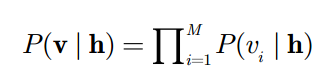
我们可以得到上式,上式意思是,在给定所有显元的值的情况下,每一个隐元取什么值是互不相关的。同样,在给定隐层时,所有显元的取值也互不相关。这个结论非常重要。
当我们输入v的时候,通过p(h|v) 可以得到隐藏层h,而得到隐藏层h之后,通过p(v|h)又能得到可视层,通过调整参数,我们就是要使得从隐藏层得到的可视层v1与原来的可视层v一样,那么得到的隐藏层可以视作与可视层等价,也就是说隐藏层可以作为可视层输入数据的特征。因此隐层又叫做特征检测器。
EBM的概率模型定义通过能量函数的概率分布,形式是:
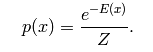
其中,Z(θ)是归一化因子,也称为配分函数(partition function),形式是:
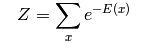
RBM是一种基于能量(Energy-based)的模型,其可见变量v和隐藏变量h的联合配置(joint configuration)的能量为:
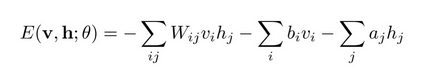
其中θ是RBM的参数{W, a, b}, W为可见单元和隐藏单元之间的边的权重,b和a分别为可见单元和隐藏单元的偏置(bias)。
有了v和h的联合配置的能量之后,我们就可以得到v和h的联合概率:
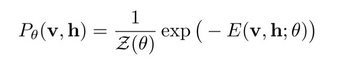
其中Z(θ)是归一化因子
联立上面两个式子:
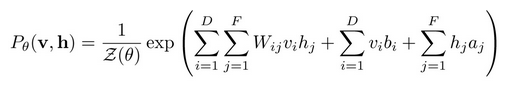
得到了概率分布后,我们要学习参数{W,a,b},表示出概率分布的最大似然函数:
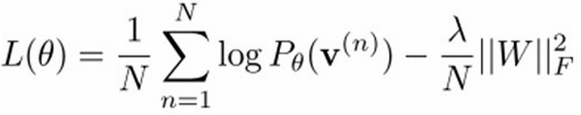
我们只要让最大似然函数最大化就可以了,也就是求偏导,可以得到下面的表达式:
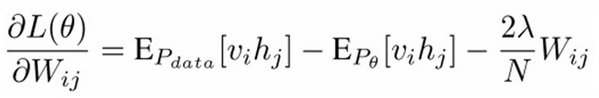
上面式子中的前者比较好计算,只需要求vihj在全部数据集上的平均值即可;而中间的式子涉及到v,h的全部2|v|+|h|种组合,计算量非常大(基本不可解)。
为了计算中间的表达式:Hinton等人提出了一种高效的学习算法-CD(Contrastive Divergence),使得这个问题可以被真正实现。
利用之前我们说到的独立的性质,首先根据数据v得到h的状态,然后通过h来重构(Reconstruct)可见向量v1,然后再根据v1来生成新的隐藏向量h1。因为RBM的特殊结构(层内无连接,层间有连接), 所以在给定v时,各个隐藏单元hj的激活状态之间是相互独立的,反之,在给定h时,各个可见单元的激活状态vi也是相互独立的,即:

这个算法就是对比散列算法,通过这个算法,可以通过迭代得到所有的参数:

上述算法比较抽象,通俗讲就是:
①将可见变量状态,设置为当前训练的样本状态{0,1}
②利用上面第一个公式更新隐藏变量的状态,计算P(hj=1|v)的概率决定。
③对于每个边vihj,计算Pdata(vihj)=vi*hj
(注意,vi和hj的状态都是取{0,1})。
④根据上面第二个公式重构v1
⑤根据v1上面的第一个公式再求得h1,计算Pmodel(v1ih1j)=v1i*h1j
⑥更新边vihj的权重Wij为Wij=Wij+L*(Pdata(vihj)=Pmodel(v1ih1j))。
⑦取下一个数据样本,重复这个过程。
- 使用受限玻尔兹曼机
现在玻尔兹曼机已经学习完毕,我们接下来怎么使用呢?现在假设有一条新的数据:
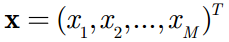
首先我们计算出每个隐元的激励值 (activation) :
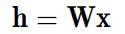
将每个隐元的激励值都用 SigMod 函数进行标准化,变成它们处于开启状 (用 1 表示) 的概率值:
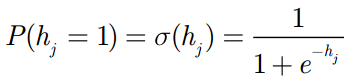
接下来就是与我们预设的阈值进行比较:
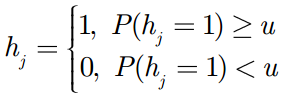
这样我们就知道是否该开启隐层。
深度学习虽然好,但是也是存在很多缺点的。优点是在图像处理、语音识别和NLP方面可以达到很高的精度,此外,可以自动的提取特征,避免了特征工程。缺点也是显而易见的,最大的缺点就是算法比较复杂,需要大量的计算资源,另外缺乏可解释性。
最后,写这篇博客参考了很多资料,其中
http://www.cnblogs.com/xiaokangzi/p/4492466.html
http://www.chawenti.com/articles/17243.html
http://blog.csdn.net/zouxy09/article/details/8781396
给了我很多启发,也提供了很多公式,避免了我很多不严谨的表述,在此表示感谢。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









