







本文是基于 中国大学MOOC教程 中《Python网络爬虫与信息提取》 做的学习笔记,笔者在这里做一个分享
环境(python 2.7.6)
【实例1:网络图片的爬取和存储】
将网页 http://image.nationalgeographic.com.cn/2017/0315/20170315045734460.jpg 中的图片爬取下来:
Shell代码如下:
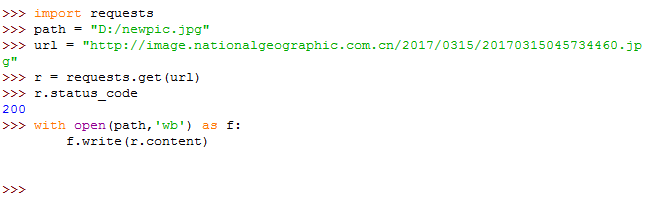
图片爬取全代码:
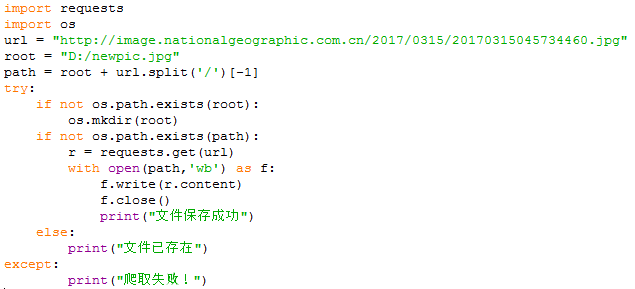
爬取结果:
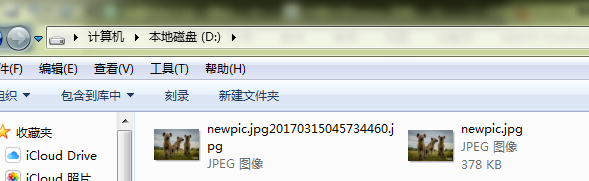
其中第二张图是shell端爬取出来的结果。
该代码不仅对图片,还对网站上所有二进制的资源格式(图片、视频、动画等),都可以用同样的代码获取它。
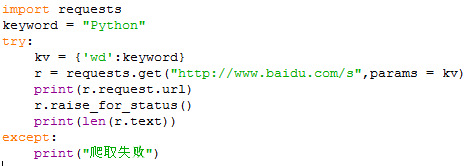
【实例2:网站关键词提交】
用python的requests库自动向搜索引擎提供关键词并且获得相应的搜索结果。
关于搜索引擎关键词提交接口:
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
在这两个关键词接口中,替换当中的keyword就可以提交它的关键词搜索了。
【重点】构造一个包含关键词的URL链接-----params可以向URL中增加相关的内容(示例中假设搜索的关键词是Python)
Shell窗口
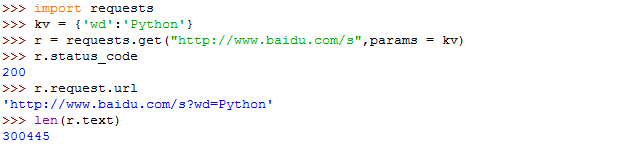
搜索的全代码如下:
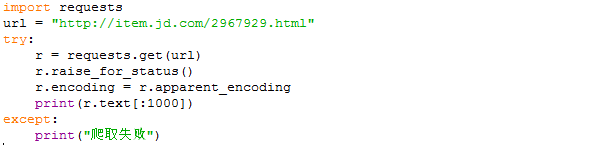
【实例3:商品页面的爬取---以京东为例】
全代码
结果(仅截取部分)

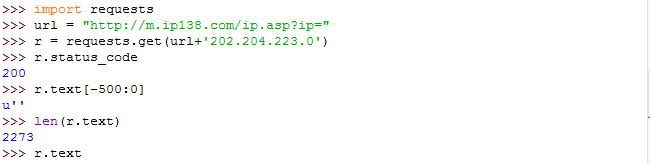
【实例4:IP地址归属地自动查询】
IP地址查询 可通过 www.ip138.com 来查询IP地址归属地
通过IP138网站提交IP地址的URL链接(接口):http://m.ip138.com/ip.asp?ip=ipadderss
Ipaddress即为提交给网页的参数,网页根据这个参数返回这个地址对应的位置。
本示例中对北京市海淀区进行查询(该URL在IP138搜索结果如下)

Shell窗口
全代码:
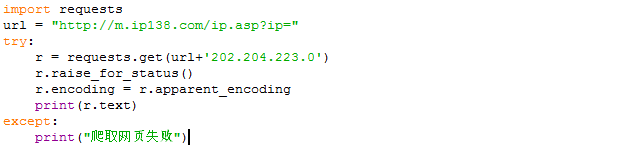
爬取结果(部分截图)

【后记】网络中的任何内容都与URL相匹配,对网站的搜索查询等操作都是通过访问它的URL实现的。















 2680
2680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









