







总结一下这些年在项目中一些设计技巧,有些在前面的章节已经提到过。
一、属性定义
1.1、数据类型
(1)整型还是字符型
在可以为整型的情况下尽量使用整型,通常情况下整型占的空间小,可以提高I/O及缓存命中率。
(2)定长还是变长字符型
定长的好处(也就是变长的坏处):
a)定长字段不需要额外维护和计算行偏移量,当然这个成本不是很大,可以忽略;
b)如果用变长的话,很有可能会由于更新行数据而带来页拆分,这个成本是很大的;
变长的好处:
节省存储空间,可以提高I/O及缓存命中率;
那究竟使用定长还是变长呢?规则就是:同一属性列的数据长度有明显差异、且更新不太频繁的情况,使用变长字符,否则建议使用定长字符,比如:订单号、MAC地址,这类长度固定的属性应该毫不犹豫地使用定长。
(3)数据类型的长度
业务的发展总是会出乎人为意料的,所以不要太小气,在长度不是太大的情况下,大胆去放大数据类型的长度,比如:把smallint(占2字节)改为int(占4字节)。
(4)数据类型一致性
避免出现:同一个字段,在A表中为整型,在B表中为字符型,保证数据类型的一致。
1.2、NULL
建议将所有列都设为not null,原因如下:
(1)记录中存在允许为null的列时,每次都在读取该行时都需要去检查null列是否有值;
(2)索引中不会记录null值,因为这个值根本不存在,所有无论单表还是多表的查询中,is null/is not null无法使用索引,关于索引的使用可参见《SQL Server 查询优化(3)_索引的设计与使用》;
(3)null值无法进行比较运算(比如:单表查询时id=1/id<>1都得不到id为null的行,多表关联时null与null也是无法对等的)、数学运算、连接运算等,当然可以通过设置一些选项来改变null的运算行为;
(4)null值除了增加程序处理的逻辑外,还有可能在聚合运算中导致bug,比如:count()和avg(),count(col1)如果col1存在null值,则得到的是非null值的行数,avg()也一样,用count(*)或count(col2),假设col2不可为空,可以得到真实的行数;
那么对于属性列不确定的时候怎么办呢?答案就是:使用默认值,比如整型为0,字符使用
N/A或N/V,时间使用1900-01-01 00:00:00,这样以避免null值的使用。
另外,对于布尔型的0、1尽量保持逻辑一致,如:0为FALSE,1为TRUE。
DBMS中之所以引入null,只是为了完善数学模型,即3值逻辑,这个有点像cross join。
1.3、FK(外键)
为保证实体完整性,也就是第2范式,表中主键或唯一键是一定要有的,否则就可能出现重复纪录。那么外键呢?
通常矛盾在于:参照完整性及实现参照完整性的性能问题。
(1)用外键实现参照完整性,保证数据的一致性;
(2)海量数据的情况下,参照完整性检查的成本很大;
究竟怎么使用外键呢?对于海量数据的情况,为保证DML的效率,不建议使用外键,参照完整性可以使用after触发器或关联属性来实现;反之就是在不影响性能、或对性能要求不高的情况下使用外键。
1.4、CHECK
CHECK约束用于检查域完整性,不建议使用,检查工作完全可以放到界面上去做,比如:java里的正则表达式,多么强大。
目前,能够想到的不得不用CHECK约束的地方就是分区视图,但分区视图是SQL SERVER没有分区表的时候,一个替代品,所以有了分区表就再也没有使用CHECK约束的理由了。
二、实体、关系表
2.1、属性
(1)简单属性还是复合属性
举个例子:银行卡号一个长串,第一反应,它应该是一个字符串,但其实,银行卡号通常只有后四位才是唯一标识,前面都是银行编号+开户行等信息,那么这样完全可以把银行卡号作为多个整型值来存储。这要取决于业务规则;
再比如前面提到过的姓名,如果需要国际化时,姓名就要考虑FirstName、MiddleName、LastName字段,而不能像中国人一样直接就是一个Name字段;
(2)是否真的是多值属性
前面提到过多值属性需要单独抽象成实体,但有时,需要辨别是否真的是多值属性,比如:用户实体的地址、机器实体的所有元器件列表、小说实体的所有章节,它们都是单值的复合属性;
(3)备注或者描述
数据表设计应该越简洁越好,像备注或者描述(remark/description)这样的字段,如果可有可无时,最好省掉:一是没有人真正地去维护它,二是占存储空间;
(4)实体还是属性
举个例子:《数据库设计(2)_逻辑结构设计》中1:1关系里的用户与汽车。
a)如果业务需求中对于汽车的属性不作限制,只需要知道汽车编号即可,E-R模型如下图:
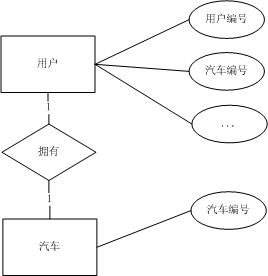
此时可以将用户与汽车实体合并为一个用户实体,E-R模型如下图:
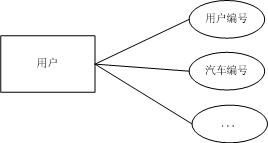
b) 如果业务需求中对于汽车的属性需要作出描述,比如:产地等,E-R模型如下图:
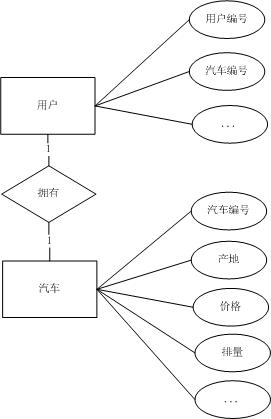
那么此时就不能实体进行合并,应该独立描述用户、汽车实体。
2.2、其他
(1)字典的使用
实体表中的状态、类型等属性,如果不是太多,不需要做成字典表。另外、经常变化的元数据不宜作为字典,因为字典这些信息通常会加载在CACHE中,如果经常变,那就意味着需要经常去更新CACHE。
(2)系统中有哪些用户
通常需要存在四种用户:管理员(全部读写权限)、业务操作用户(部分读写权限)、报表查询用户(只读权限)、测试用户(部分读写权限),测试用户通常供开发人员使用,往往在软件上线后,需要在线修改一些问题,测试用户产生的数据,不计入业务数据范围;
(3)大写还是小写
默认ORACLE把所有数据库对象大写,如果想指定成小写或大小写混写,需要用”“,但这样带来的问题就是在引用这个对象时也要加上”“,很不方便,所以索性全用大写,这对于异构数据库的互相访问很有帮助,比如:从ORACLE访问SQL SERVER;
另外,在作字符等值比较时,最好使用UPPER/LOWER函数将两端的字符全转换成大写/小写再作比较;
在后面会分别给出SQL SERVER和ORACLE数据库的命名和开发规范,
(4)实体行如何删除
不允许对已发生事实、或建立关系的实体行进行物理删除,会破坏实体的参照完整性,即使是没有发生事实、或建立关系的实体行,通常也不进行物理删除,只是逻辑删除;
(5)兼容B/S和C/S开发方式
设计实体时要考虑到B/S和C/S开发方式的元素,比如:C/S方式中的DLL、FORMNAME、根据B/S的应用使用一些新型的数据类型,比如:XML类型;
(6)数据权限
除了管理员有所有数据权限外,数据权限原则上是谁产生的数据谁有权限;
(7)如何进行数据同步
数据同步有推、拉两种方式。
推的方式:在数据发生变化后,立即发出通知给需要更新的点;
拉的方式:由定时任务,定时去数据源作增量检查,这种方式就需要在表中建立一个标识增量变化的属性,比如:时间戳;
(8)不能为了技术而技术
举个例子:用户申请编号时,发起申请编号的事务,事务完成时显示:您申请到的编号为XXX。
但如果并发量较大,即便是采用数据库自身的序号生成方式(IDENTITY或SEQUENCE),仍然会存在等待,那么,就可以考虑从客户端生成此次事务的唯一编号,到数据库层没有申请编号的排队过程,直接写入;
(9)实体还是关系
举个例子:《数据库设计(3)逻辑结构设计常用模块》中权限实体里的角色、权限、控件。
a)如果不使用权限实体,此时权限通过关系来描述,E-R模型如下图:

b)如果使用权限实体,此时权限以实体来描述,E-R模型如下图:
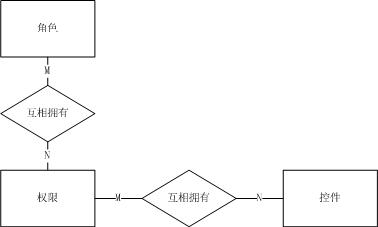
这两种方式都是可以的,但需要注意的是:一要避免由于实体或关系带来的数据多次存储,浪费存储空间;二要保证数据的一致性;
再重复一次:概念结构设计、逻辑结构设计的结果都不是唯一的。
三、事实
(1)发现及记载事实
在《数据库设计(2)_逻辑结构设计》中提到过事实的发现,通常,业务相关的事实,通过查看《需求规格说明书》、与用户直接交谈、自身的行业经验、问卷调查等方式可以获得;
但系统业务中用不到或者说暂时用不到的事实,是否就不作记载呢?比如:系统日志等等,建议在不影响系统性能及用户体验的情况下,记载尽量多的事实,日后,它对于做决策分析等这类事情时,会很有帮助;
(2)事实与报表
根据业务需要进行周期性的聚合,产生比如:日报、周报、月报这样的统计表,而不是等到需要查报表的时候才去事实表中进行汇总;
(3)事实的大类与小类
事实小类即某个具体的业务事实,这点通常都会有事实记载,但有些时候,需要查看事实大类的明细,是否需要去遍历各个小类呢?
比如:账户事实,大类为进出账,小类为:充值、提现、消费、利息、扣税等,如果想要看账户的进出账明细,可以记录一个账户进出账的大类事实,当中包括进出账及进出账的类型,如果想看某一类型的明细,再去小类事实看发生了什么,比如:消费还可以再分为交电费、交水费、交网费、饭店用餐等,同样,对于同一小类事实的不同类型,也需要加上类型字段,比如:消费类型;
再比如:用户使用系统功能的日志,大类为用户操作,小类为:点击各个控件所做的事情,如果想要看用户操作行为,可以记录一个用户操作的大类事实,当中包括用户点击了哪些功能,如果想看某一操作的明细去小类事实看用户操作的内容;
(4)事实中瞬态属性
瞬态属性的记载尤为重要,否则可能会丢失事实的真相,比如:商品的定价、账户的卡号等。
转载自:http://blog.csdn.net/seusoftware/article/details/5517514















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









