







专注物联网场景特点,详解 IoTDB 设计的数据分片与负载均衡策略。
我们都知道,当数据库服务的业务负载增加时,往往需要扩展服务资源,一般有两种扩展方式:纵向扩展和横向扩展。
纵向扩展是指增加单台机器的能力,比如增加更多的内存、硬盘和更强的处理器。这种方法有一个限制,就是单台机器的硬件能力是有上限的。横向扩展是指增加更多的机器,把数据和处理请求分摊到多台机器上。这种方法更加灵活,因为可以不断增加机器,几乎没有上限。随着大数据时代的到来,横向扩展因其在性价比和灵活性上的优势,越来越受到关注,越来越多的系统开始探索分布式的解决方案。
为什么分布式系统能够利用多台机器的资源提升数据库的读写性能?其本质在于数据被分布到多个节点上,单个请求对数据的访问被转化为多个节点分别访问部分数据。这就涉及到两个重要的设计:分片和负载均衡。
数据分片:将大量数据拆分为多个较小的部分,分布在多个节点上,从而提高存储和查询性能。
负载均衡:动态调整数据分布,确保每个节点的负载均衡,从而提高集群性能和稳定性。
IoTDB 针对大部分时序场景中近期数据操作频繁、历史数据操作较少的特点,设计了专门的分片和负载均衡策略。本文将深入解析其中的关键设计,帮助您理解并掌握 IoTDB 的分片策略,从而更有效地利用每台机器的资源,提升集群性能。
01
概念与原理
在 IoTDB 中,分片被称为 RegionGroup,元数据和数据都会分片(SchemaRegionGroup 和 DataRegionGroup)。
注:
1. 元数据主要包括时间序列的定义信息,是用来描述数据的数据。
2. 数据主要包括时间戳与测点值,是会随着时间变化而变化的数据。
3. 为方便理解,本文暂不考虑单 RegionGroup 多副本间的一致性问题,下篇博客会进行详细介绍。
(1)元数据分片原理
IoTDB 中的元数据分片逻辑如下图所示:
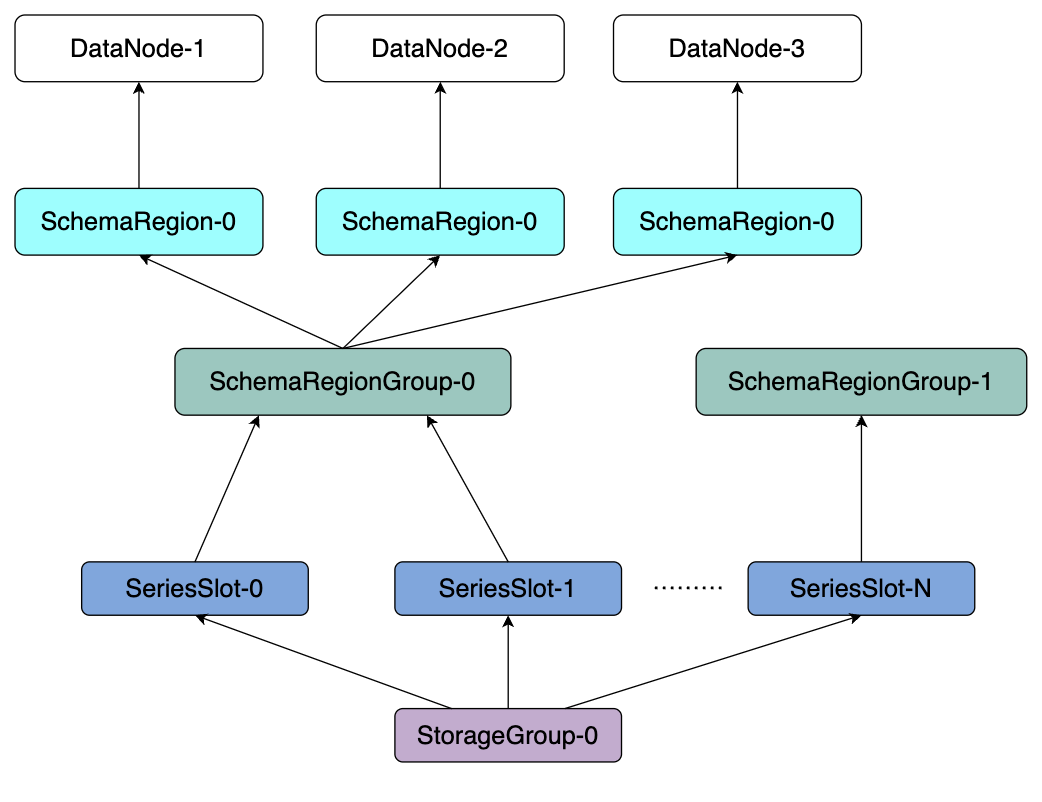
核心逻辑有以下几点:
1. 一个数据库中的所有元数据,会依据其中的设备名哈希到某一个序列槽(SeriesSlot,默认为 1000)。
2. 不同的序列槽会依据一定的负载均衡策略分配到不同的 SchemaRegionGroup。
3. 不同的 SchemaRegionGroup 会按照一定的负载均衡策略分配到 DataNode 上。
我们通过一个具体例子来了解下,当在 IoTDB 集群中具体创建一个序列时,会发生什么。
首先用户会通过执行 create timeseries root.db.d.s with datatype=booleanSQL 语句来创建元数据,当 IoTDB 收到此请求后:
1. 计算该时间序列设备的 hash 值,假设 Hash(root.db.d)%1000 = 2,说明该设备应该在 2 号序列槽中。
2. 对于 2 号序列槽:
a. 如果之前不存在,那么它将会分配至目前含有序列槽最少的 SchemaRegionGroup 上来保证负载均衡。
b. 如果之前存在,且已经分给某个 SchemaRegionGroup,则不改变这个分配的关系。
3. 将该元数据存储在该 SchemaRegionGroup,这需要向拥有该 SchemaRegionGroup 的 DataNode 发送请求。
通过上述方案,所有设备都会通过哈希算法均匀地分配到所有 SeriesSlot 中,而 SeriesSlot 到 SchemaRegionGroup 和 SchemaRegionGroup 到 DataNode 的双层映射通过负载均衡算法确保均匀分配,从而使元数据的读写可以并行均匀利用集群所有节点的资源。
值得一提的是,通过该方案,不论设备数量是万级还是亿级,其分片路由信息的维护成本依然是固定的,而具体的元数据管理又可以分散到集群中,这使得 IoTDB 在面对大规模时序元数据时具有极高的可扩展性,最大测试支持过百亿级别测点的元数据。
(2)数据分片原理
IoTDB 中的数据分片逻辑如下图所示:
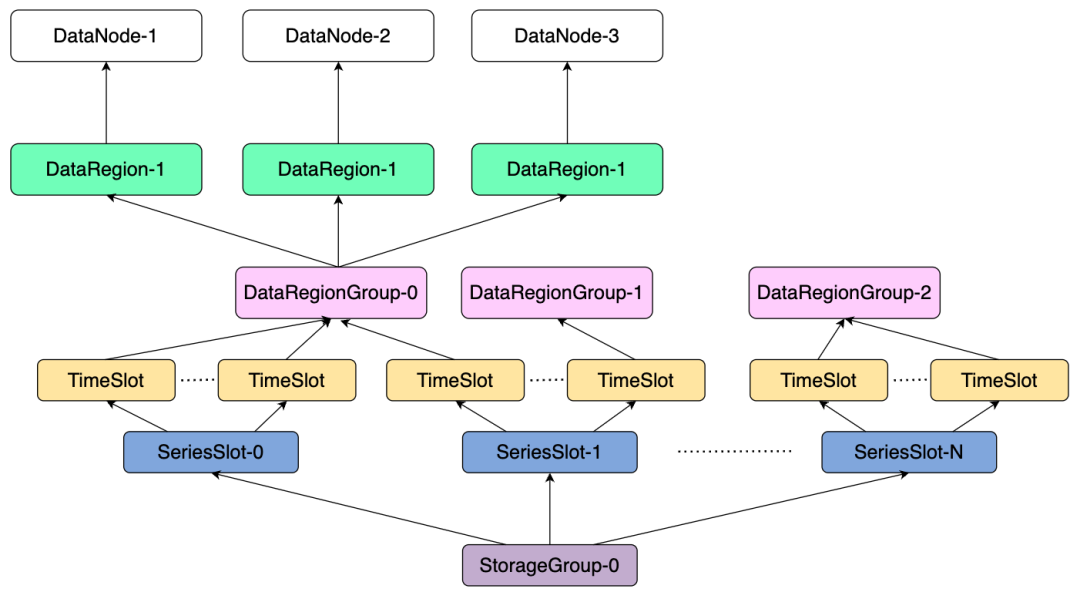
相较于元数据分片,多了一个时间槽(TimeSlot),也就是说:
1. 一个数据库中的所有数据,会先依据其中的设备名哈希到某一个序列槽(SeriesSlot,默认为 1000)。再依据该数据所处的时间区间(默认一周为一个区间),决定被分到哪一个时间槽(TimeSlot)。
2. 这样一个由序列槽和时间槽确定的数据片段(DataPartition),会依据负载分配给不同的 DataRegionGroup。
我们还是通过一个具体例子来了解下,当在 IoTDB 集群中插入一条新的数据时,会发生什么。
当用户通过 SQL 语句触发数据写入 insert into root.db.d(time,s) values(1,1):
1. 假设 Hash(root.db.d)%1000 = 2,说明该设备应该在 2 号序列槽中,再对时间戳 1 进行时间切分 1/604800000=0,所以被分在 0 号时间槽(一周一个区间,604800000 是一周对应的毫秒数)。
2. 对于 DataPartition-2-0:
a. 如果之前不存在,则将该 DataParititon 分给含有 DataParititon 最少的 DataRegionGroup。
b. 如果之前已经存在,且已经分给某个 DataRegionGroup,则不改变这个分配的关系。
3. 将数据写入到该 DataRegionGroup 中,这需要向拥有该 DataRegionGroup 的 DataNode 发送请求。
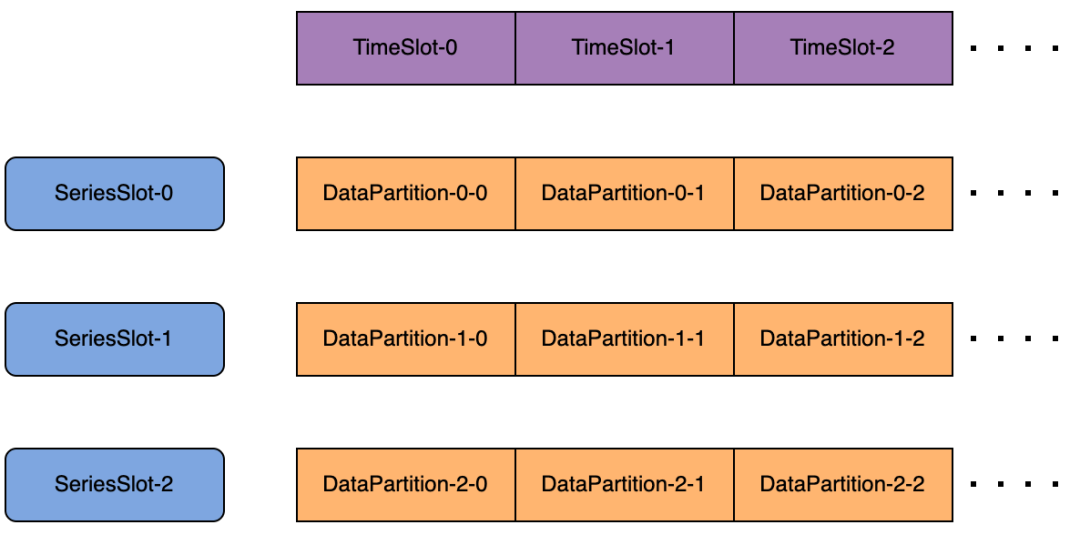
通过上述方案,所有设备的读写流量都会通过哈希算法均匀地分配到所有 SeriesSlot 中,再通过时间区间计算得到 TimeSlot 及其对应的 DataPartition,而 DataPartition 到 DataRegionGroup 和 DataRegionGroup 到 DataNode 的双层映射通过负载均衡算法确保均匀分配,从而使数据的读写可以并行均匀利用集群所有节点的资源。
值得一提的是,通过该方案,不论设备数量是万级还是亿级,时间范围的跨度是 1 年还是 10 年,IoTDB 分片路由信息的维护成本依然是非常轻量的,而具体的时序数据管理又可以分散到集群中,这使得 IoTDB 在面对大规模时序数据时具有极高的可扩展性,最大测试支持过 PB 级别的时序数据存储。
(3)为什么数据分片要新增时间维度的区分
读者可能会好奇,为什么要给数据分片增加时间维度的区分,让一个设备的数据永远处于一个节点上有什么不好?这源自于我们对时序场景业务特性的深入思考。
在 Share-Nothing 架构下,扩容必然会带来大量的数据搬迁才能利用新节点的资源,而数据搬迁无论如何限流和优化,都会影响实时的读写负载。那么在时序场景下,有没有可能避免扩容时的数据搬迁呢?这就需要考虑时序场景的特性。
首先,在传统的 KV 负载下,我们无法预知下一个请求是写入 a 还是 z,而在 IoTDB 擅长的物联网等时序场景下,实时的读写流量往往集中在最近的时间分区,老的时间分区的读写流量则会逐渐减少。其次,时序场景相比互联网场景,其负载更可预测,一般不会在短时间内出现大幅波动。基于这些考虑,我们对 IoTDB 进行了巧妙设计,使其在扩容时无需迁移数据,并在部分场景中应用,取得了良好反馈。
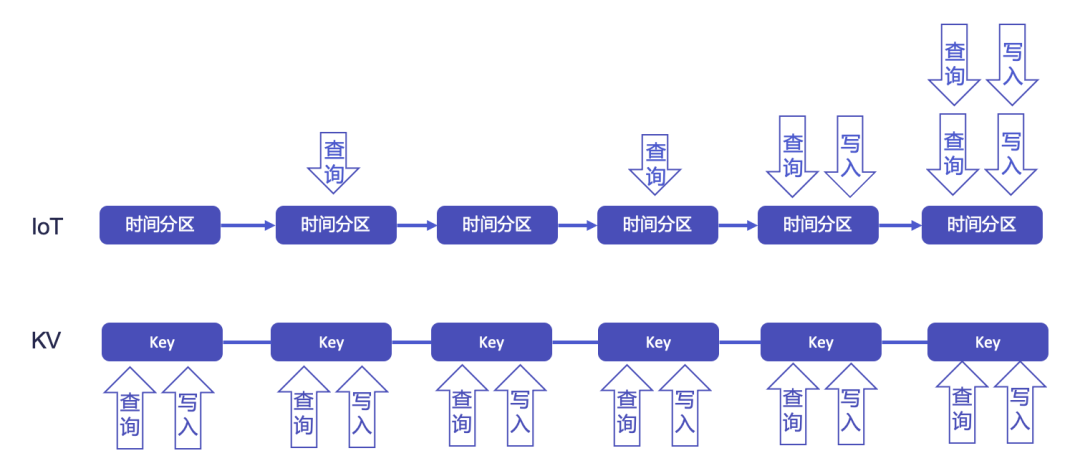
当 IoTDB 扩容 DataNode 节点后,我们可以直接将部分序列槽在新时间槽下的 DataPartition 分配给新节点上新创建的 DataRegionGroup。这样,即使在不搬迁数据的情况下,也能实现计算资源的均衡。当然,此时老节点和新节点的磁盘容量会有所不同,老节点的磁盘容量会更多一些。
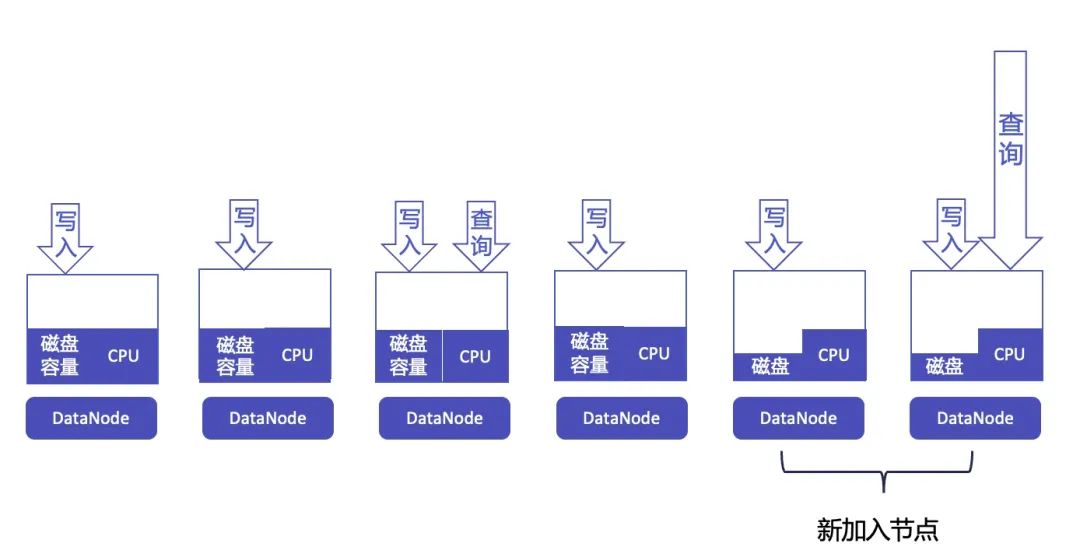
然而,时序场景一般会设置 TTL(Time To Live)属性,随着时间的推移,老节点上的陈旧数据会逐渐被删除,新节点上的数据则会逐渐增多。在经过一个 TTL 周期后,所有节点的存储和计算资源都将达到平衡。通过一个 TTL 周期,我们可以实现不搬迁数据就利用新节点资源,并最终实现存储和计算资源均衡的目标。
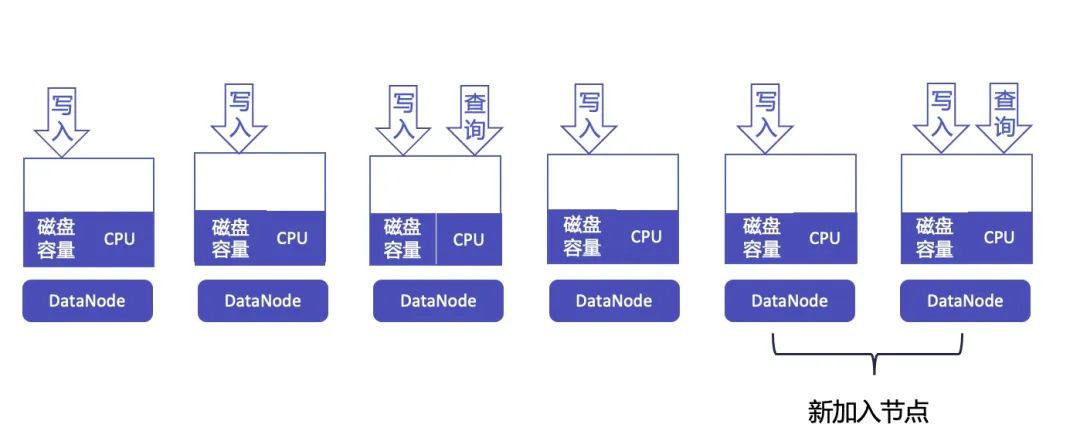
当然,这种优化需要业务提前进行预估和规划,才能在整个周期内实现扩容而无需数据迁移。如果业务没有做好规划或不便于如此实现,IoTDB 也提供了 Region 迁移指令,以供运维人员灵活地手动进行负载均衡。
02
分布式集群中的分片示例
我们已经知道了数据与分片之间的逻辑概念,现在我们具体的落到实际的节点上,来看看分片和节点间的关系。以上篇文章中的 3C3D 集群为例,其增加了分片策略后架构如下图所示:
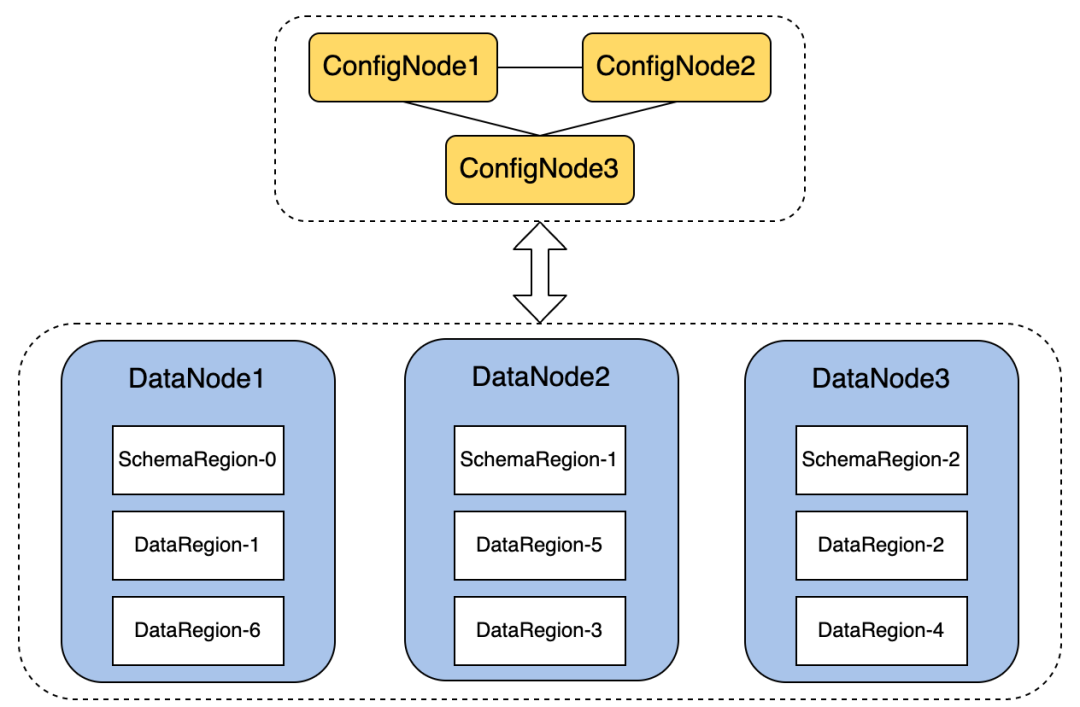
每个 DN 节点都管理多个 Region(包括 SchemaRegion 和 DataRegion),具体由 iotdb-common.properties 中的多项参数决定:
-
schema/data_region_group_extension_policy Region 扩展的方式。
-
-
CUSTOM:每一个 database 在第一次写入时直接创建 default_schema/data_region_group_per_database 个 SchemaRegionGroup / DataRegionGroup,且不再会扩展。
-
-
-
AUTO:每一个 database 在最开始设备数不断增多的写入中快速扩充到 default_schema/data_region_group_per_database 个 SchemaRegionGroup / DataRegionGroup,后续根据集群资源情况自动扩充,最多到每个节点拥有 schema/data_region_per_data_node 个 Region。
-
-
default_schema/data_region_group_num_per_database 每一个 database 的 RegionGroup 数。
-
schema/data_region_per_data_node 每一个节点的 Region 数。
-
-
只在 schema/data_region_group_extension_policy 为 AUTO 时生效,决定了 DN 在扩展 Region 时单 DataNode 持有 Region 的最大值。
-
-
-
当前 DN 如果含有多个 database 的数据,那么 Region 数可以超过该值(因为一个 database 会有 default_schema/data_region_group_per_database 个 Region)。如果此时该 DN 含有的 Region 已经超过该值,则后续不会触发扩充 Region。
-
03
常见操作
(1)如何查看数据库中的分片?
在 IoTDB 中,您可以通过 SQL 语句来查看集群目前的分片情况。
IoTDB> show regions
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+
|RegionId| Type| Status|Database|SeriesSlotNum|TimeSlotNum|DataNodeId|RpcAddress|RpcPort|InternalAddress| Role| CreateTime|
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+
| 0|SchemaRegion|Running| root.db| 1| 0| 1| xxxxxxx| 6667| xxxxxxx|Leader|2024-05-27T14:38:16.654|
| 1| DataRegion|Running| root.db| 1| 1| 1| xxxxxxx| 6667| xxxxxxx|Leader|2024-05-27T16:33:30.359|
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+SeriesSlotNum=1 说明单副本的 SchemaRegionGroup 0 被分配了一个 SeriesSlot,其存在于 DataNode 1 上。
SeriesSlotNum=1 TimeSlotNum=1 说明单副本的 DataRegionGroup 0 被分配了一个 SeriesSlot 和一个 TimeSlot,其也存在于 DataNode 1 上。
(2)如何进行手动负载均衡?
大部分情况下,IoTDB 默认的分片及负载均衡策略能够保证所有 RegionGroup 间和 DataNode 间的负载均衡。
然而,在具体的部署和使用过程中,如果观察到不同节点之间的 CPU、IO、内存等资源负载不均衡,可以通过 show regions 命令排查不同 DataNode 上的 Region 数、Leader 数以及分配的 SeriesSlot 和 TimeSlot 数是否均衡。如果发现不均衡,则可以考虑通过手动的 Region 迁移操作来使集群负载重新均衡。
(3)如何配置分片数量?
由于每一个 RegionGroup 内部基本上是串行执行的,因此一般可以将集群的总 RegionGroup 数与节点的硬件资源绑定起来。
您可以通过设置 iotdb-common.properties 中的 default_data_region_group_per_database 和 default_schema_region_group_per_database 参数来合理地设置 database 级别的 RegionGroup 个数。
一般情况下,一个 IoTDB 集群中所有 SchemaRegionGroup 的个数与节点个数 / 副本数一致即可,所有 DataRegionGroup 的个数与集群总 CPU 核心数 / 副本数一致即可。这种设置在一般情况下能够很好地利用节点的并行计算能力。
04
总结
分片与负载均衡是分布式系统中至关重要的架构设计。IoTDB 不仅将每一条数据和元数据均匀地映射到 RegionGroup 中,实现了逻辑上的分片以及 RegionGroup 间的负载均衡,还针对时序场景进行了深入思考,创新性地实现了在扩容过程中无需迁移数据也能达到存算资源均衡的目标。
这一设计有效地解决了传统系统在扩展过程中面临的性能瓶颈和数据迁移成本问题,确保了系统在处理大规模物联网数据时的高效性和稳定性。同时,这种架构设计能够根据数据访问的频率和模式进行智能调节,进一步优化资源的利用率,提升整体系统的性能和响应速度。
通过本文,您已经深入了解了 IoTDB 的分片与负载均衡策略,掌握了其在实际应用中的优势和操作技巧,期待您能使用 IoTDB 更好地应对复杂的物联网数据管理挑战。
下一篇博客我们将会解密 IoTDB 独特的共识模块设计,敬请期待!
更多内容推荐:
• 了解如何使用 IoTDB 企业版
• 了解更多 IoTDB 应用案例





















 4467
4467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











