







 本文围绕服务器CPU性能展开,介绍了性能分析整体思路,利用常见工具获取指标定位瓶颈。详细阐述了CPU使用率、上下文切换、平均负载、缓存命中率等指标,分析不同指标异常时的排查方向,还提及提升缓存命中率的方法,助力运维人员解决CPU性能问题。
本文围绕服务器CPU性能展开,介绍了性能分析整体思路,利用常见工具获取指标定位瓶颈。详细阐述了CPU使用率、上下文切换、平均负载、缓存命中率等指标,分析不同指标异常时的排查方向,还提及提升缓存命中率的方法,助力运维人员解决CPU性能问题。
系统监控-硬件资源-CPU篇-整体思路-性能指标和工具-使用率、上下文切换、负载、命中率
参考来源:
在系统监控的综合思路篇中,我曾经介绍过,系统资源的瓶颈,可以通过 USE 法,即使用
率、饱和度以及错误数这三类指标来衡量。系统的资源,可以分为硬件资源和软件资源两
类。
如 CPU、内存、磁盘和文件系统以及网络等,都是最常见的硬件资源。
而文件描述符数、连接跟踪数、套接字缓冲区大小等,则是典型的软件资源。
这样,在你收到监控系统告警时,就可以对照这些资源列表,再根据指标的不同来进行定位。
CPU 性能分析整体思路
第一种最常见的系统资源是 CPU。关于 CPU 的性能分析方法,我在如何迅速分析出系统
CPU 的瓶颈中,已经为你整理了一个迅速分析 CPU 性能瓶颈的思路。
利用 top、vmstat、pidstat、strace 以及 perf 等几个最常见的工具,
获取 CPU 性能指标后,再结合进程与 CPU 的工作原理,就可以迅速定位出 CPU 性能瓶颈。
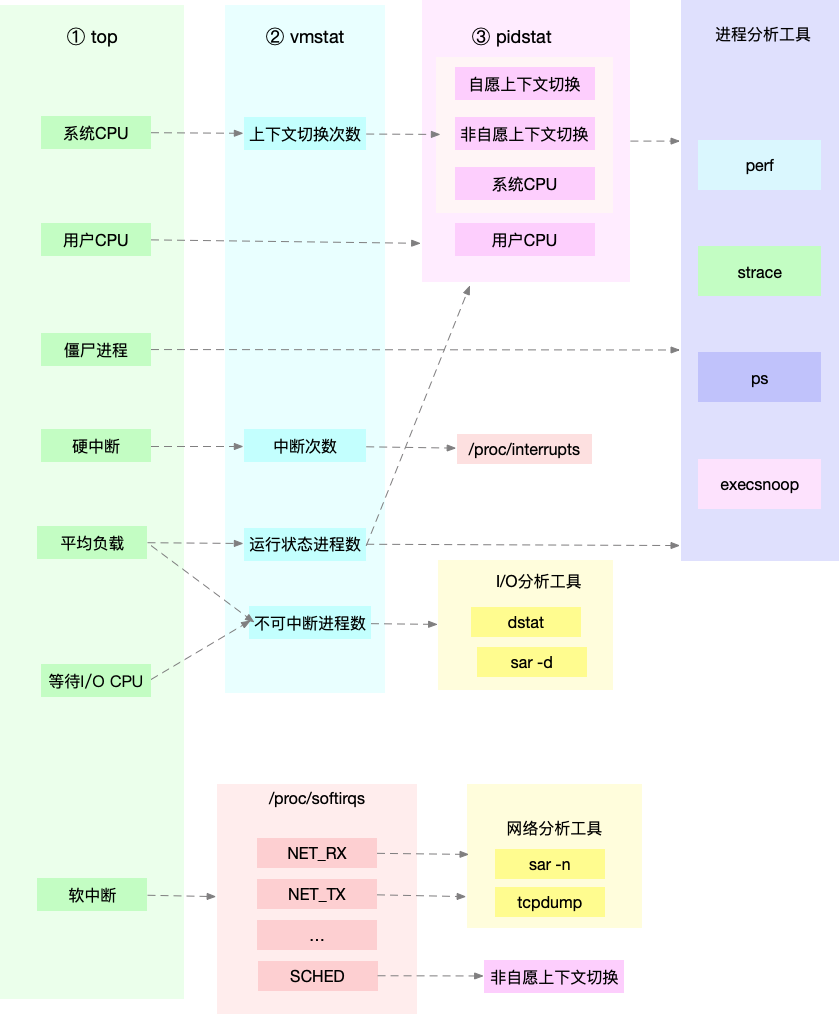
这张图里,我列出了 top、vmstat 和 pidstat 分别提供的重要的 CPU 指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
实际上,top、pidstat、vmstat 这类工具所汇报的 CPU 性能指标,都源自 /proc 文件系统(比如 /proc/loadavg、/proc/stat、/proc/softirqs等)。这些指标,都应该通过监控系统监控起来。虽然并非所有指标都需要报警,但这些指标却可以快性能问题的定位分
析。
比如说,当你收到系统的用户 CPU 使用率过高告警时,从监控系统中直接查询到,导致CPU 使用率过高的进程;然后再登录到进程所在的 Linux 服务器中,分析该进程的行为。
你可以使用 strace,查看进程的系统调用汇总;也可以使用 perf 等工具,找出进程的热点函数;甚至还可以使用动态追踪的方法,来观察进程的当前执行过程,直到确定瓶颈的根源。
cpu性能指标和CPU性能工具速查表
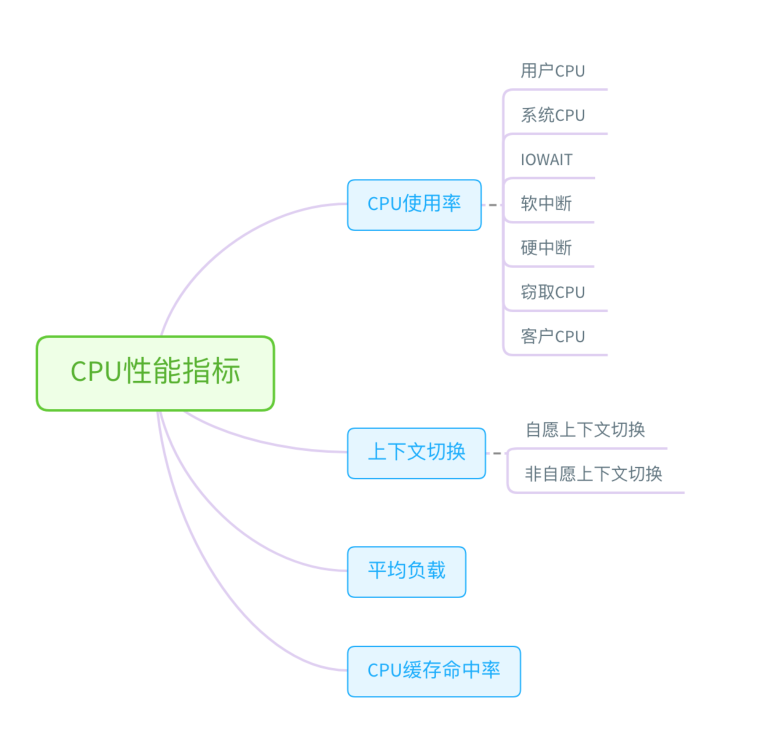
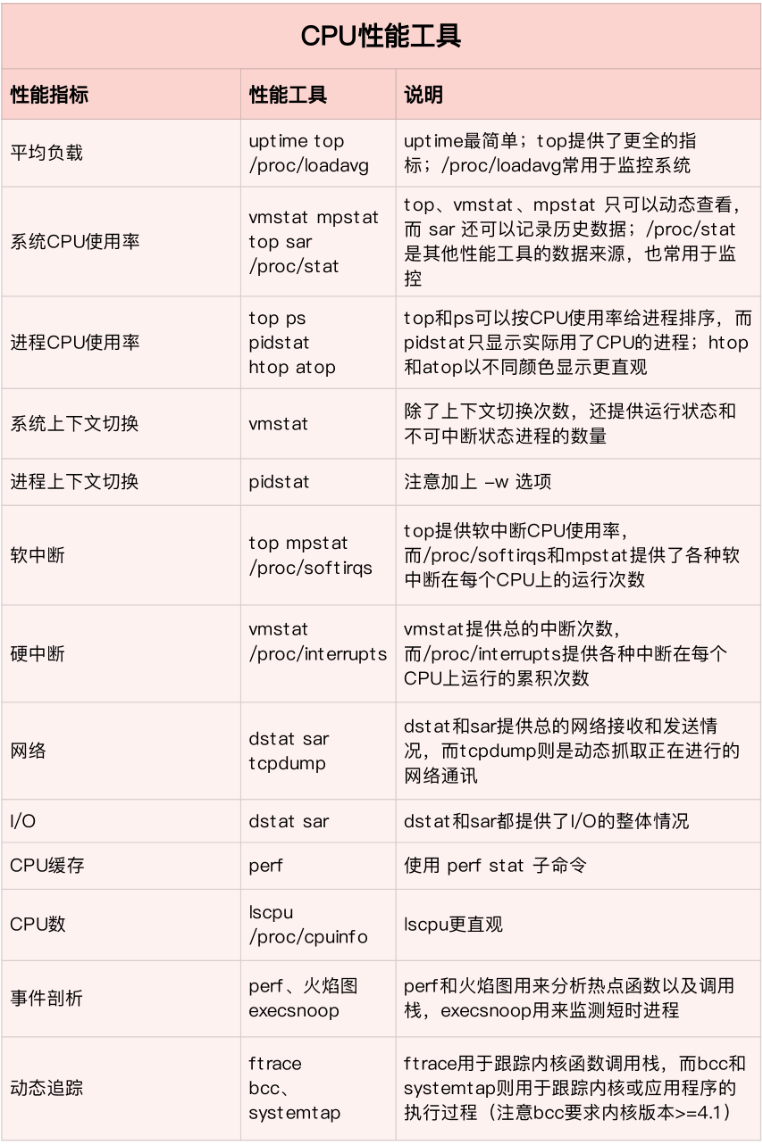
CPU性能指标01-CPU使用率(排查方向)
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
CPU 使用率相关的重要指标
你还会在很多其他的性能工具中看到它们。下面,我来依次解读一下。
user(通常缩写为 us)ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









