







一、二叉查找树
1.定义
对一颗二叉查找树的任何节点,该节点的左子树中的任何一个节点的值都小于等于该节点的值,该节点的右子树中的任何一个节点的值都大于等于该节点的值。
2.删除结点
叶子节点直接删除,非叶子节点选择左最大、右最小替换该节点(即左子树最小的节点或右子树最大的节点)。
3.查找、插入、删除节点的时间复杂度
最坏时间复杂度O(n):无左子树/无右子树
一般时间复杂度O(lgn)。
二、随机化版本的二叉查找树(http://www.cnblogs.com/soyscut/p/3409542.html)
下面主要介绍随机化版本的二叉查找树,因为查找树的效率的关键就是树的高度,所以这里想通过随机化来使二叉查找树更加平衡。
主要内容是:1. BST sort与quicksort 的关系 2.二叉树的随机化版本 3.随机BST depth的分析
1. BST sort与quicksort 的关系
BST sort过程:
BST SORT(A) {
T = 0 // Create an empty BST
for i=1 to n
do Tree-Insert(T,A[i])
Perform an inorder tree walk of T
}让我们来考虑一个例子,并分析一下整个过程。 A=[3 1 8 2 6 7 5]; 建好树后的结构是:
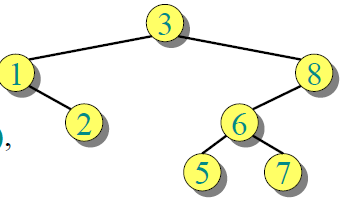
分析建立二叉树时间复杂度
最好情况是完全二叉树,树完全是平衡的,高度也达到最小,时间复杂度为Θ(nlgn)。
最差情况是当元素完全顺序或逆序时,生成的数就是一个链表,时间复杂度为Θ(n^2)。
根据上面的两个复杂度,我们很自然的想到了快排。 而实际上,BST sort和基本快排(即把第一个元素当分割点)执行了相同的比较,但是按照不同的顺序。
由基本快排的优化方案,我们自然就想到了随机化版本的BSTsort。
2.二叉树的随机化版本
随机化BST sort的主要方法是先随机化的重新排列数组,然后再执行BST sort。
根据快排的时间复杂度得BST sort的时间复杂度为:
进一步得到树的平均深度的期望:


我们关注的是平均高度而不是实际高度,即每个节点的高度和的平均值。而实际上,树的实际高度可能远大于logn。比如下面这个例子中,平均高度是lgn,但是实际高度是n(1/2)。

3.随机BST depth的分析
上面提到,随机化建立的树的高度可能不是lgn,而是节点的平均高度是lgn。
现在我们要证明的定理是随机化BST建立的树的高度的期望确实是lgn。
















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









