






nodejs是现在很流行的服务端语言。由于他使用的是JavaScript的语法,所以,很多时候,使用更多的是前端,后端工程师更适应的是比较流行的流式开发。其实它和JAVA类似都是由虚拟机运行,底层虚拟机由C++来实现nodejs的V8虚拟机是Chrome的核心,因为有了它,使得Chrome成为了全世界最快的浏览器之一。并且,由于Node保留了前端的浏览器在JavaScript中那些熟悉的接口和开发方法,所以,前端学习起来基本上是零成本。当然对于后端来讲,熟悉javascript需要一定的时间,主要是它使用的是回调的开发方式和传统的java/c++使用的开发方式不太一样,所以,在编程的习惯上,需要做一个转变
v8虚拟机的开发者是Lars Bak.它原来是Sum公司的工程师,也是负责Java虚拟机的开发,所以,我们可以在V8的虚拟机设计里面看到很多来hotspot虚拟机类似的设计。基本上可以看成是一个简单版的hotspot虚拟机的设计。只不过,Java在虚拟机的设计上本身是为了给服务器运行而开发,针对不同服务器类型可以提供很多优先方案。所以,设计的也比较复杂。nodejs的v8本身设计出来是为了给浏览器运行,所以比较简单。
下面分别从几个方面来介绍一下V8虚拟机的特点
1. 对象分配
在v8里面,所有的Js对象都是直接通过堆来进行分配的。 node也提供了直接的查看方式
process.memoryUsage();
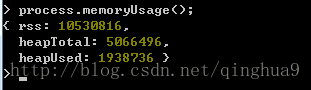
在上图中,能看到,总的堆总容量为500MB,已使用193MB,RSS为进程的常驻内存部分
在v8的堆设计时,限制了堆的大小,64位1.4G、32位0.7G。初始申请的不够会继续申请,只到能申请的最大容量为止,至于为什么限制只能到这个容量,是因为V8最初为设计给浏览器使用,很少会遇到使用大量内存的场景。而且,如果内存申请比较多会导致GC时停止的时间增长,影响正常的服务运行。
当然node也提供了参数来指定大小
node --max-old-space-size=1700 test.js //设置老年代最大内存空间
node --max-new-space-size=1024 test.js //设置新生代最大内存空间
2. 垃圾回收
v8使用分代式垃圾回收机制,这和JAVA的回收算法类似。这种回收机制将内存区分为年轻代和老年代。两个里面存放的对象生命周期不一样。两种分别使用不同的回收算法。
顾名思义,新生代存放的对象生命周期很短,老年代存放的对象生命周期相当长。。前面看到的两个参数就是分别设计这两个参数最大空间的配置了。
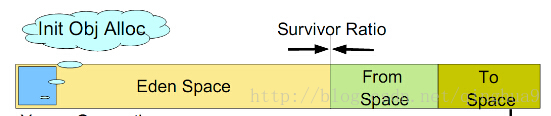
- 年轻代回收算法scavenge: 年轻代回收算法基本上和JAVA的新生代回收算法ParallelScavenge一样。它的使用cheney(强尼)算法:使用复制方式来实现垃圾回。它会将堆内存一分为二,在这两个空间里面,只有一个会使用。另一个闲置,分别是from/to 空间,当我们分配对象时,会在From空间中进行分配,在回收时,会检查from里面存活的对象,然后复制到to空间,非存活的对象会被释放掉。完成后,两个空间的功能会做一个切换。下图为很经典的图
- 老年代回收算法:Mark-Sweep &Mark-Compact:标记-清除。对应到java虚拟机的是老年代算法CMS,CMS相对来说比较复杂,会把整个清除过程分成四个阶段,即:
下面举个例子来说明mark-sweep。
a={1,2,3}
a={2,3,4}这样一段代码在执行了第二行的语句之后,1,2,3这个数组就不会再被引用了,成为GC的对象

从上面这张图可以看清晰的理解到由于a的指针指导向2,3,4前面123没有指针引用。所以,会被回收。
GC会在何时启动呢?一般来说对于虚所机而言,其中一种方法就是在内存不足的时候,即(malloc()返回null时),不过,真到这时候内存已经基本上耗完了。
所以,基本上会在耗费了一定的内在后,就启动GC。我们看一段CHECK GC的实现代码
static void check_gc(CRB_Interpreter *inter)
{
//判断堆的耗费量是否超过阀值
if(inter->heap.current_head_size> inter->head.current_threshold){
crb_garbage_collect(inter);
//设定下一个阀值
inter->heap.current_threshold=inter->heap.current_heap_size+HEAP_THRESHOLD_SIZE;}}当堆的消耗量超过了当前的阀值就启动GC.GC执行时,current_heap_size的值会变小,然后将变小后的current_heap_size和HEAP_THRESHOLD_SIZE相加,就得出下一个阀值。HEAP_THRESHOLD_SIZE是初始值
至于 crb_garbage_collect(inter );的实现就不细说了,基本上就是标记-清除算法的实现,可以看到代码里面分成两步
void
crb_garbage_collect(CR_Interpreter *inter){
gc_mark_objects(inter);
gc_sweep_objects(inter);
}与scavenge相比,mark_sweep不会将内存空间分为两半,所以,不会浪费一半空间,它会在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象,所以,和Scavenge相比,标记清除只清理死亡的对象,而标记清除只复制活着的对象。这和新生代堆和老年代堆的特点有关。活的对象在新生代中只占较小的部分,而死的对象在老生代中只占较小部分,所以,这两种方式对于大多数情况下的新生代和老生代都比较高效。
当然。Mark-sweep最大的问题是,在标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题。因此。Mark-Compact被提出。即(标记-整理)它是在前者基础之上演变而来的。让我们来看标记-整理在基维百科上的一张图
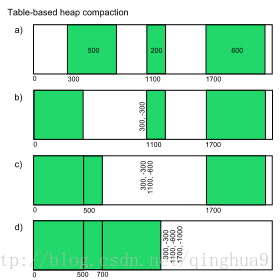
可以看到a是未整理前的内存,有三块未被回收的内存对象。在整理的过程中,将活着的对象往左边移动,移动完成以后,直接清理掉边界外的死亡对象,上图中,绿色为存活对象,白色为回收对象,这样完成回收后,内存的空间还是会保护连接的状态。解决了mark-sweep的内存空间不连接的问题。
当然Mark-sweep和Mark-Compact也不是完全可替代的关系。在v8虚拟机中,两者是结合起来使用(这一点HotSpot也是一样)
因为相对前者后者的回收速度是比较慢的,因为它有对象的移动,而mark-sweep没有对象移动,所以,效率会比较高。V8在清理时主要会使用Mark-sweep,在空间不足以对新生代中晋升过来的对象进行分配时才会使用Mark-compact
3. 停顿
以上提到的几种垃圾回收算法都需要将应用逻辑停下来,等完成垃圾回收后再恢复继续执行,即“stop-the-world”,在这点上V8也做了优化。即尽将回收分散,进行增量标记,拆分成许多小“步进”,每做完一“步进”,就让应用逻辑执行一会,垃圾回收和应用逻辑会轮流执行直到标记阶段完成。
4. 实战
最后我们找一些node的垃圾回收代码来学习一下
nohup $NODEJS --trace_gc --max-old-space-size=200 $NODEJS_SERVER/bin/server.js >$NODE_STDOUT_LOG 2>&1 &在我们执行node执行时,使用--trace_gc参数,可以看到打印垃圾回收的日志信息

可以看到,新生代的复制清除屏蔽比较高,mark-sweep清除也是持续在做
var foo =function(){
var local='helloworld';
}
var foo =function(){
var local='local var ';
var bar =function(){
var local='another var';
var baz = function(){
console.log(local);
};
baz();
};
bar();
};
foo();














 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









