






本文将从什么是CNN?什么是RNN?什么是Transformer ?三个问题,带您一文搞懂人工智能基础(下):神经网络结构。
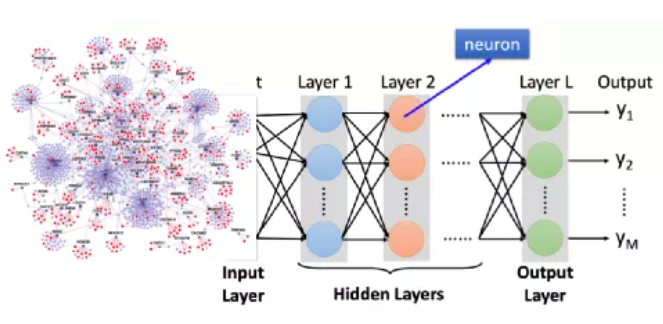 神经网络结构
神经网络结构

卷积神经网络(CNN): 通过卷积和池化操作有效地处理高维图像数据,降低计算复杂度,并提取关键特征进行识别和分类。
网络结构:
-
卷积层: 用来提取图像的局部特征。
-
池化层:用来大幅降低参数量级,实现数据降维。
-
全连接层: 用来输出想要的结果。
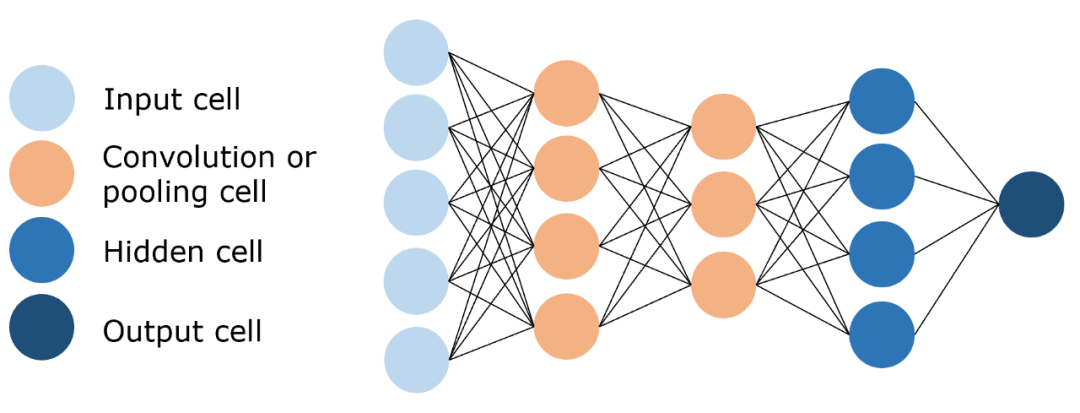
卷积神经网络(CNN)
解决问题:
-
提取特征: 卷积操作提取图像特征,如边缘、纹理等,保留图像特征。
-
数据降维: 池化操作大幅降低参数量级,实现数据降维,大大减少运算量,避免过拟合。
工作原理:
- 卷积层:通过卷积核的过滤提取出图片中局部的特征,类似初级视觉皮层进行初步特征提取。
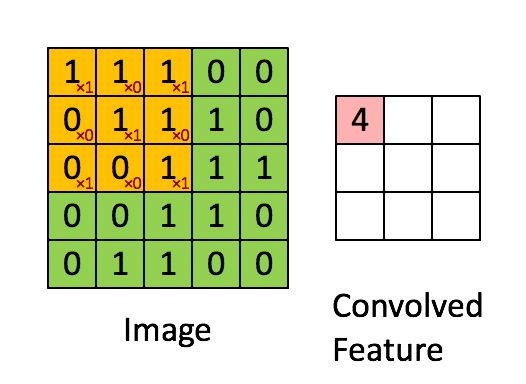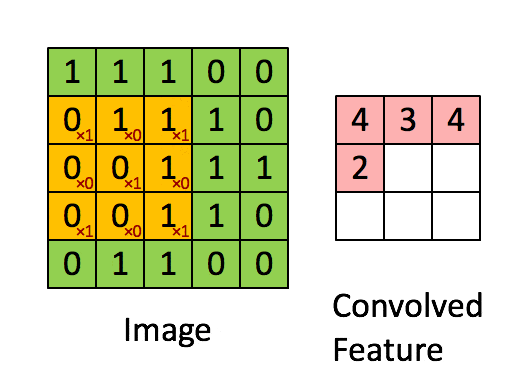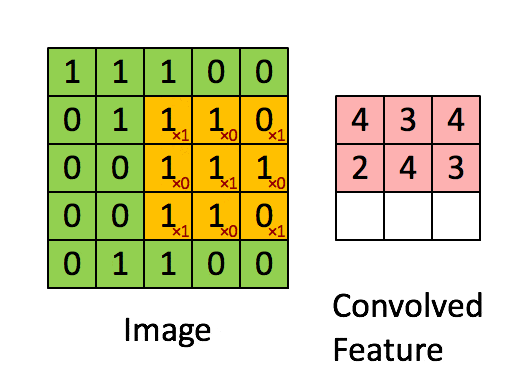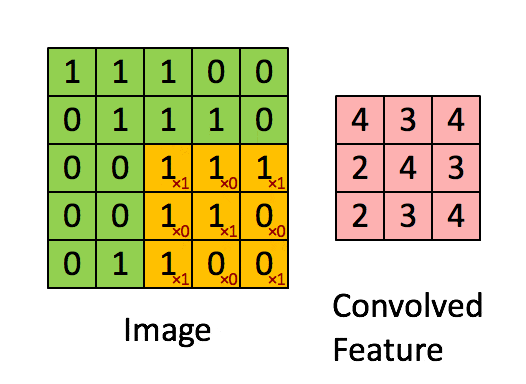
使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
- 池化层:下采样实现数据降维,大大减少运算量,避免过拟合。
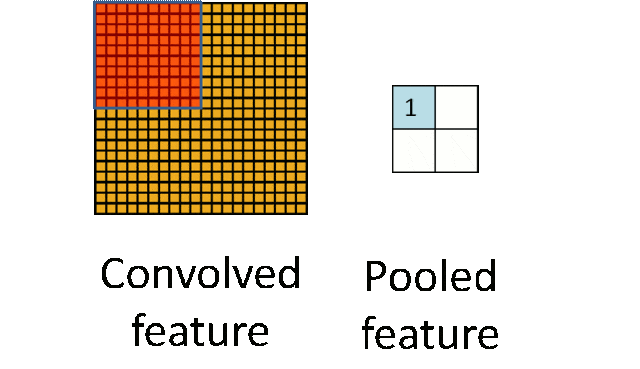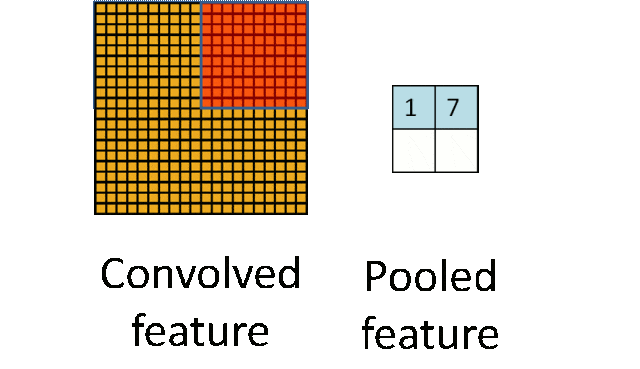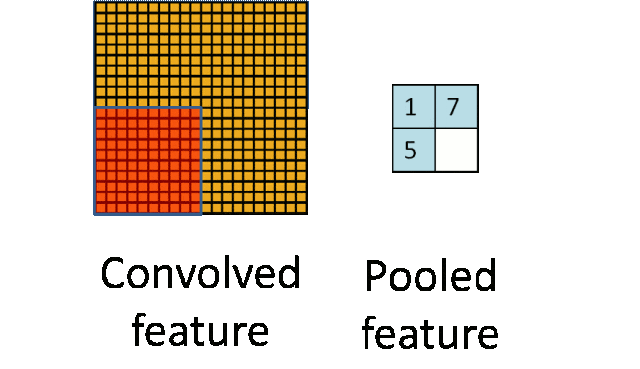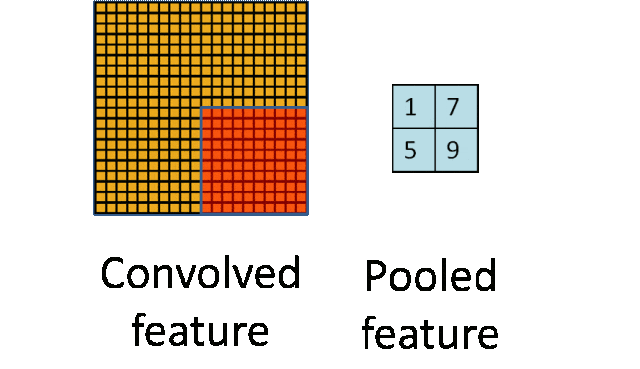 原始是20×20的,进行下采样,采样为10×10,从而得到2×2大小的特征图。
原始是20×20的,进行下采样,采样为10×10,从而得到2×2大小的特征图。
- 全连接层:经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果
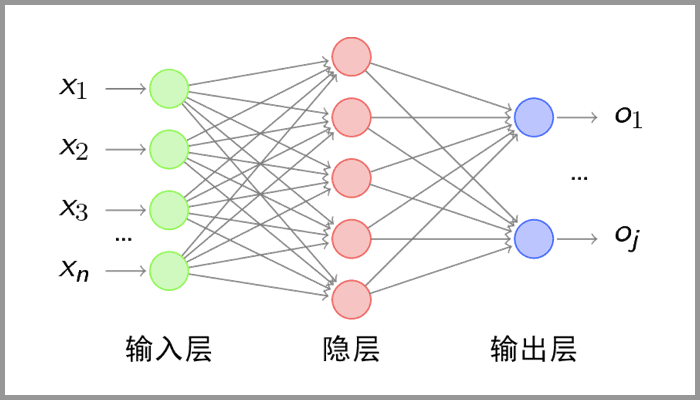 全连接层
全连接层
LeNet-5: 被誉为卷积神经网络的“Hello Word”,是图灵奖获得者Yann LeCun(杨立昆)在1998年提出的CNN算法,用来解决手写识别的问题。
LeNet-5通过引入卷积层、池化层和全连接层等关键组件,构建了一个高效且强大的图像识别网络,为后续卷积神经网络的发展奠定了基础。
-
输入层:INPUT
-
三个卷积层: C1、C3和C5
-
两个池化层: S2和S4
-
一个全连接层: F6
-
输出层:OUTPUT
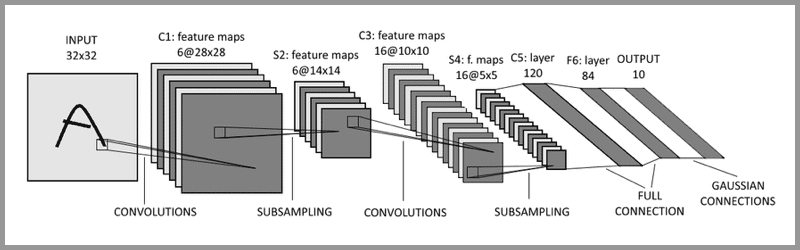 输入层- 卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层 - 输出层
输入层- 卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层 - 输出层
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

二、__什么是RNN?
循环神经网络(RNN): 一种能处理序列数据并存储历史信息的神经网络,通过利用先前的预测作为上下文信号,对即将发生的事件做出更明智的决策。
网络结构:
-
输入层:接收输入数据,并将其传递给隐藏层。输入不仅仅是静态的,还包含着序列中的历史信息。
-
隐藏层:核心部分,捕捉时序依赖性。隐藏层的输出不仅取决于当前的输入,还取决于前一时刻的隐藏状态。
-
输出层:根据隐藏层的输出生成最终的预测结果。
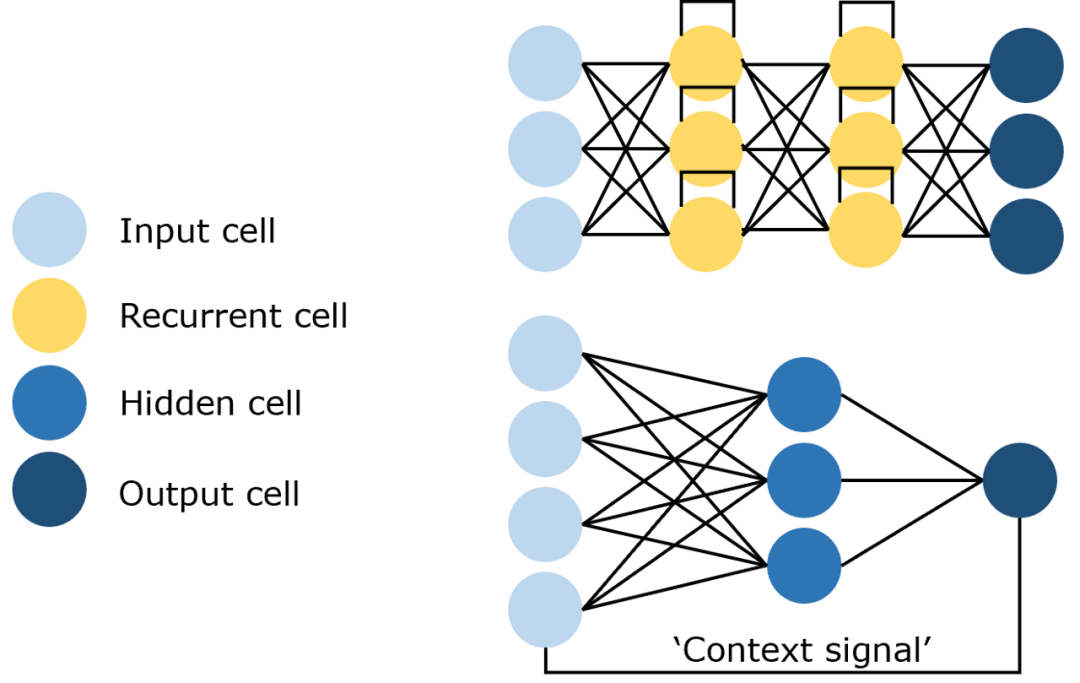 循环神经网络(RNN)
循环神经网络(RNN)
解决问题:
-
序列数据处理:RNN能够处理多个输入对应多个输出的情况,尤其适用于序列数据,如时间序列、语音或文本,其中每个输出与当前的及之前的输入都有关。
-
循环连接:RNN中的循环连接使得网络能够捕捉输入之间的关联性,从而利用先前的输入信息来影响后续的输出。
工作原理:
- 输入层:先对句子“what time is it ?” 进行分词,然后按照顺序输入。

对句子进行分词
- 隐藏层:在此过程中,我们注意到前面的所有输入都对后续的输出产生了影响。圆形隐藏层不仅考虑了当前的输入,还综合了之前所有的输入信息,能够利用历史信息来影响未来的输出。
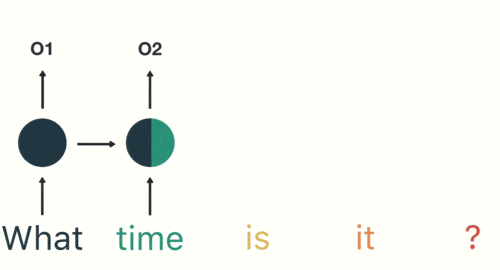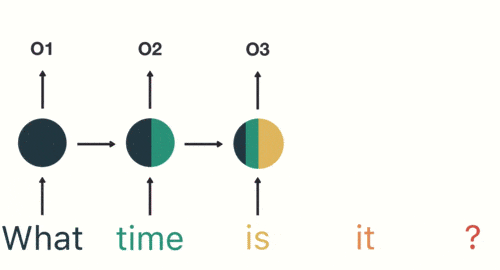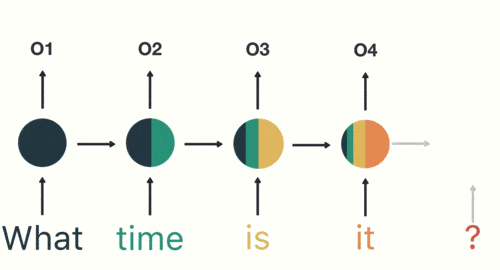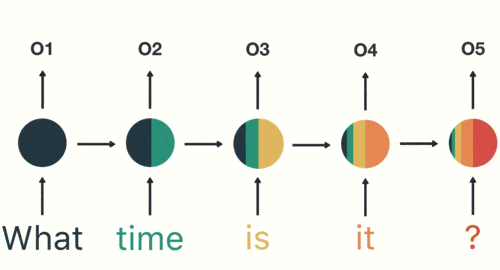
前面所有的输入都对后续的输出产生了影响
- 输出层:生成最终的预测结果:Asking for the time。
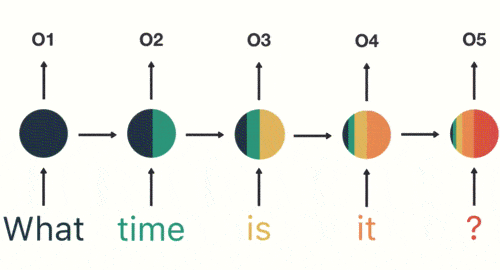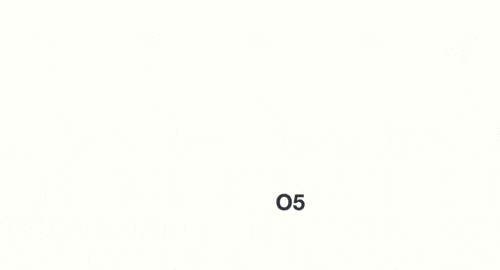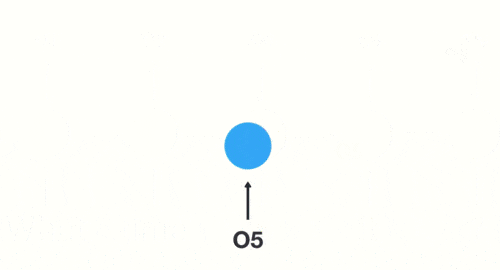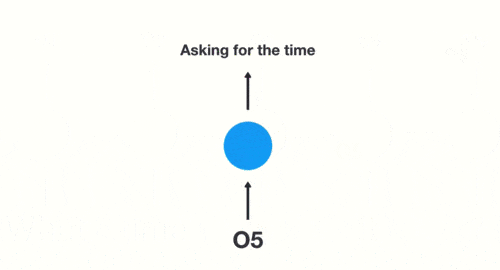
输出结果:Asking for the time
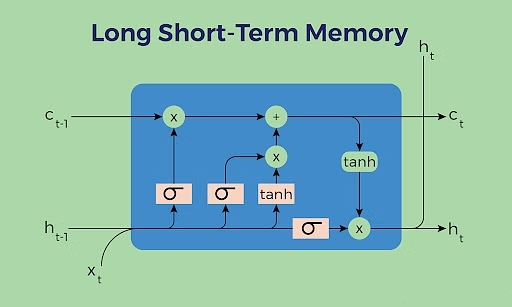
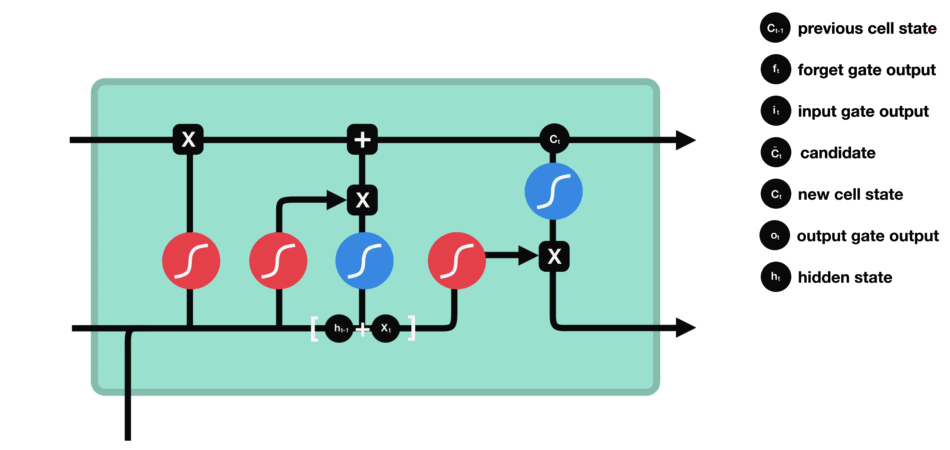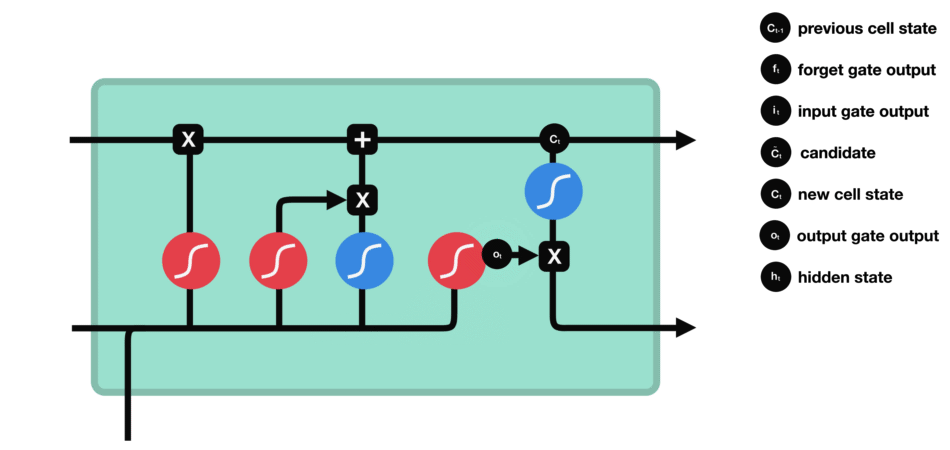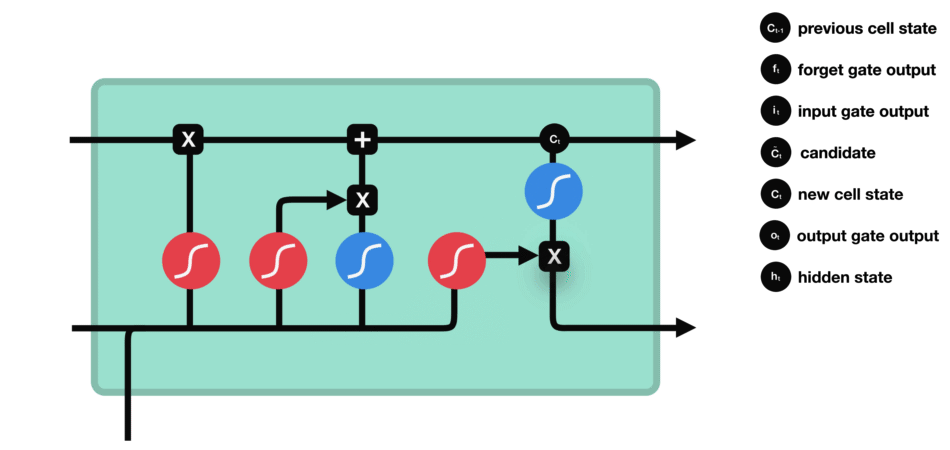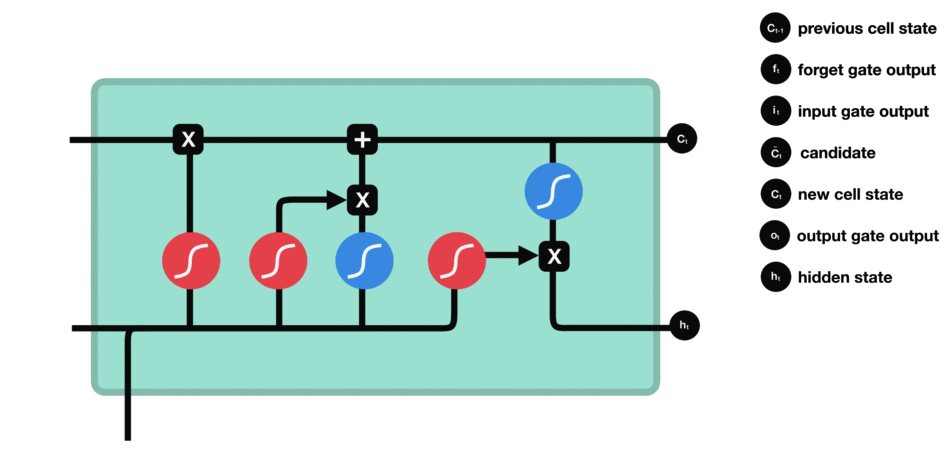
长短期记忆网络(LSTM): 一种特殊的循环神经网络,通过引入内存块和门控机制来解决梯度消失问题,从而更有效地处理和记忆长期依赖信息。
网络结构:
-
细胞状态(Cell State):负责保存长期依赖信息。
-
门控结构:每个LSTM单元包含三个门:输入门、遗忘门和输出门。
遗忘门(Forget Gate):决定从细胞状态中丢弃哪些信息。
输入门(Input Gate):决定哪些新信息被加入到细胞状态中。
输出门(Output Gate):基于细胞状态决定输出的信息。
=======================================================================================================================================================================================================================================
长短期记忆网络(LSTM)
解决问题:
-
短时记忆: RNN难以捕捉和利用序列中的长期依赖关系,从而限制了其在处理复杂任务时的性能。
-
梯度消失/梯度爆炸: 在RNN的反向传播过程中,梯度会随着时间步的推移而逐渐消失(变得非常小)或爆炸(变得非常大)。
工作原理:
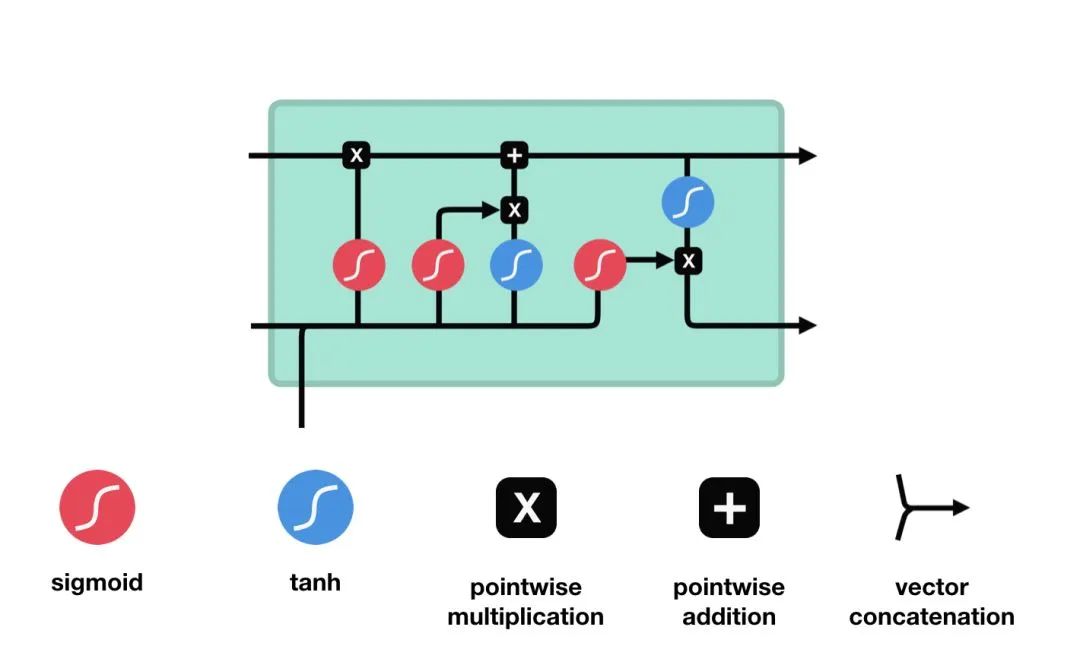
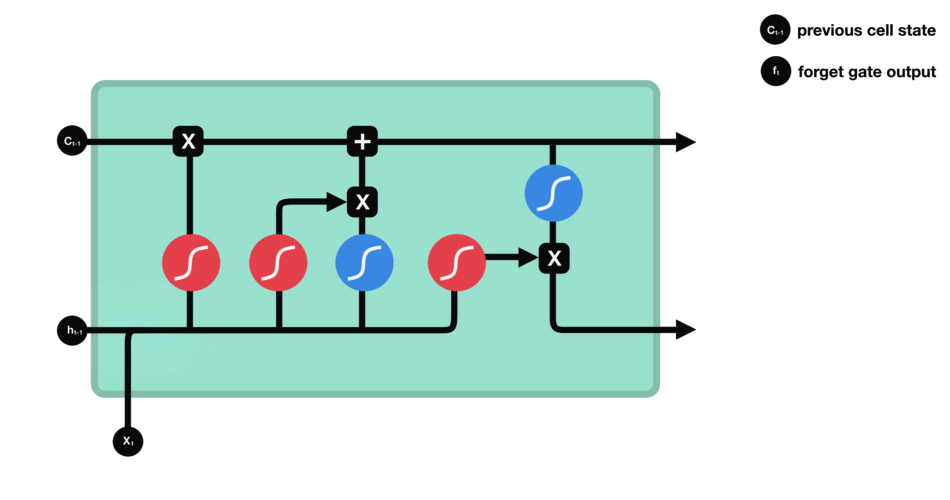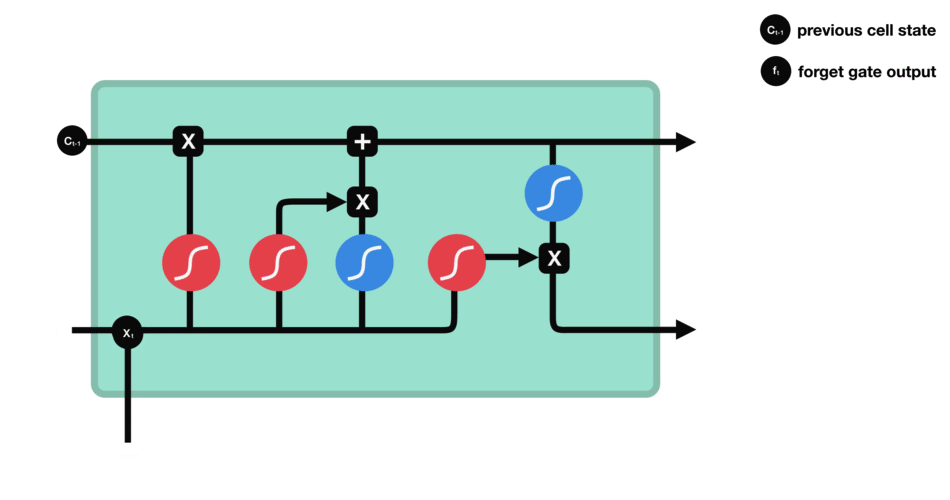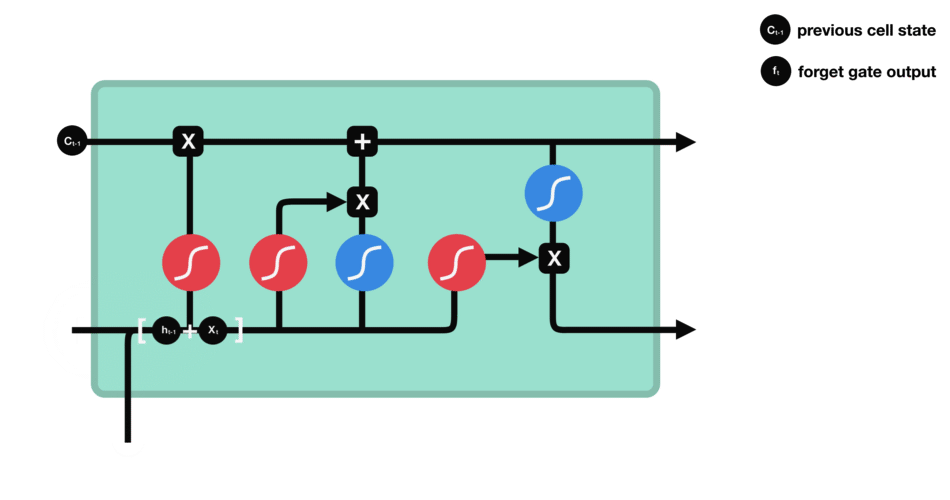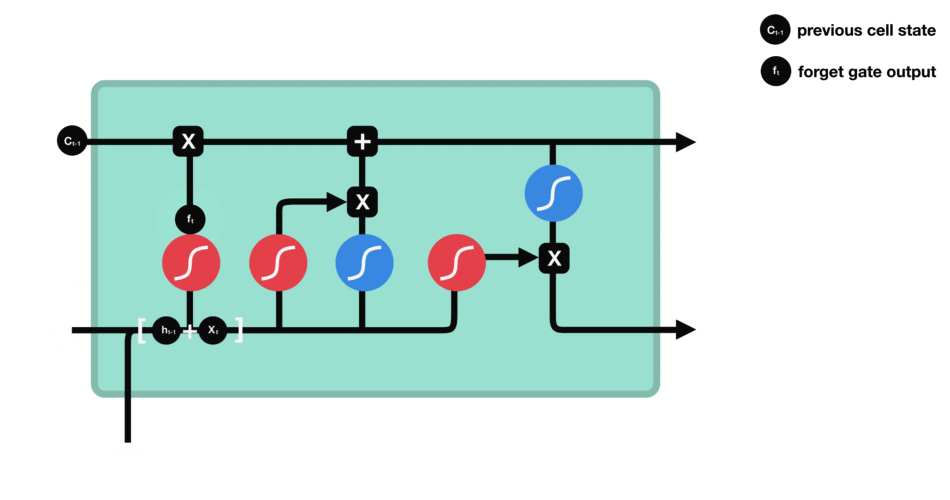
LSTM的细胞结构和运算
- 输入门:决定哪些新信息应该被添加到记忆单元中
由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息是重要的,而tanh函数则生成新的候选信息。
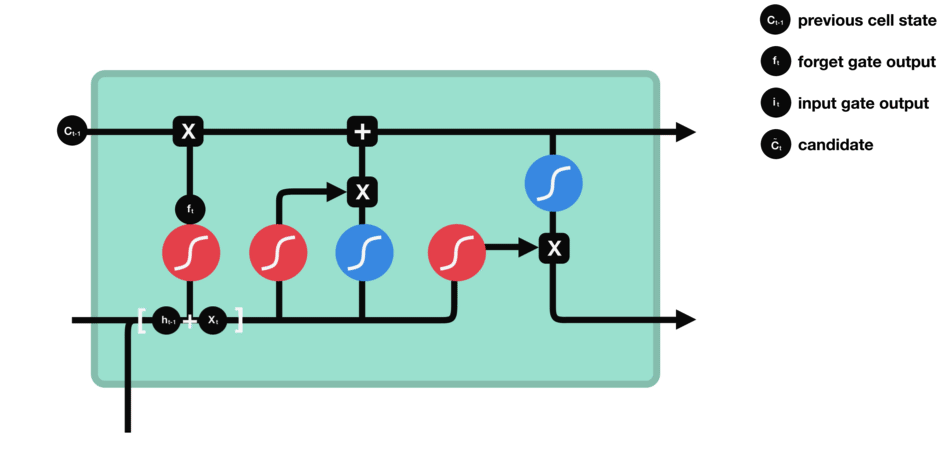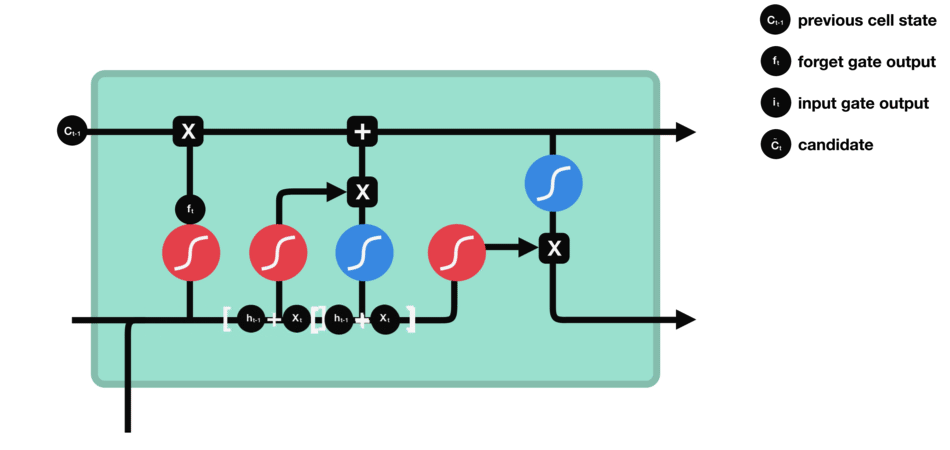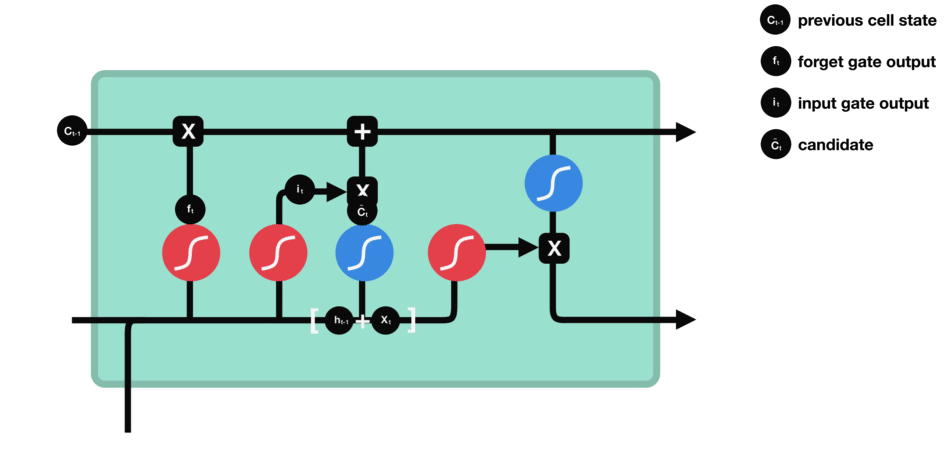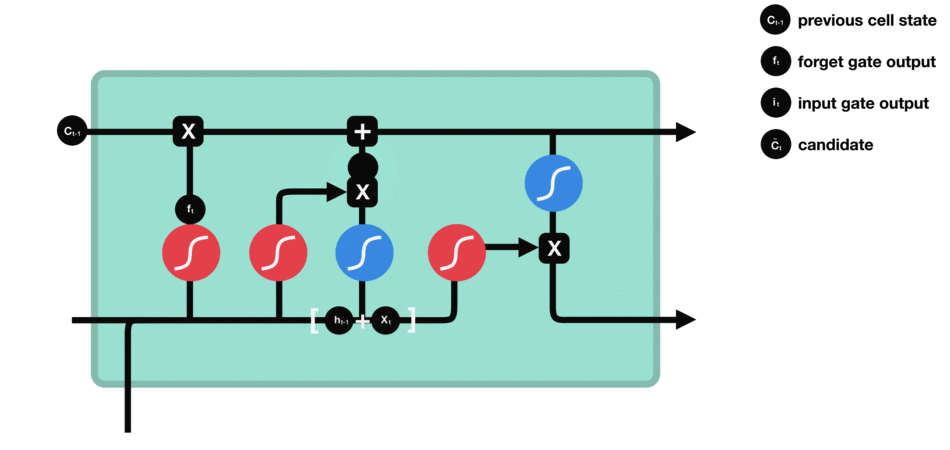
输入门(sigmoid激活函数 + tanh激活函数)
- 遗忘门:决定哪些旧信息应该从记忆单元中遗忘或移除。
遗忘门仅由一个sigmoid激活函数组成。
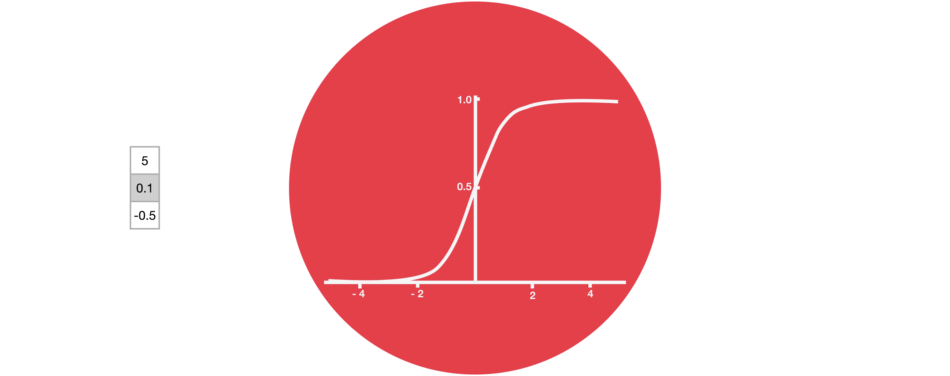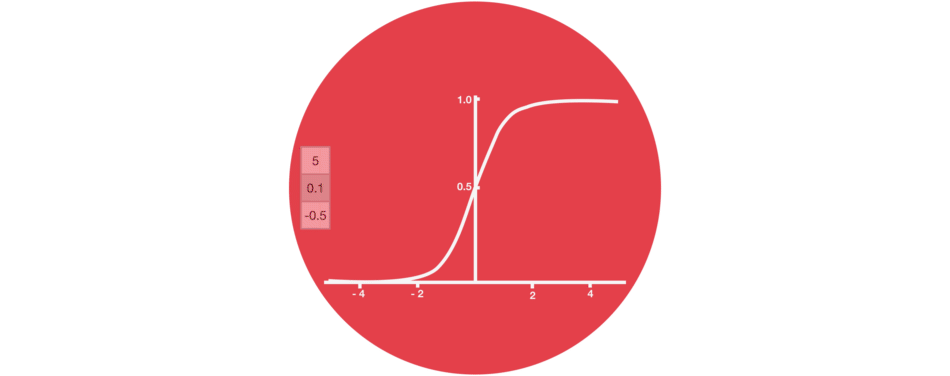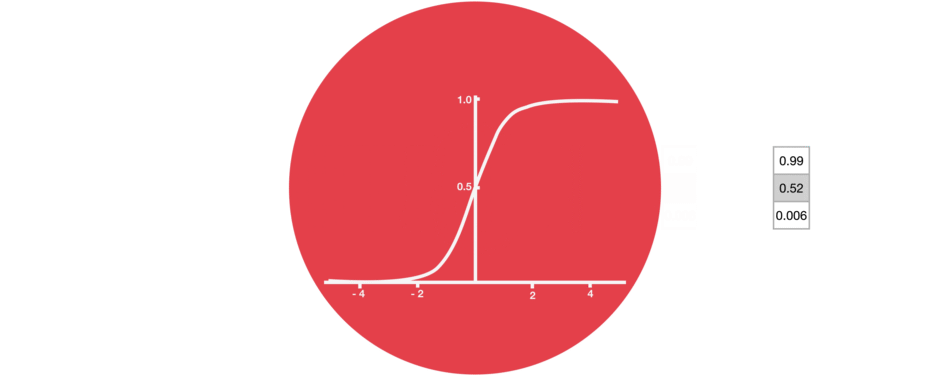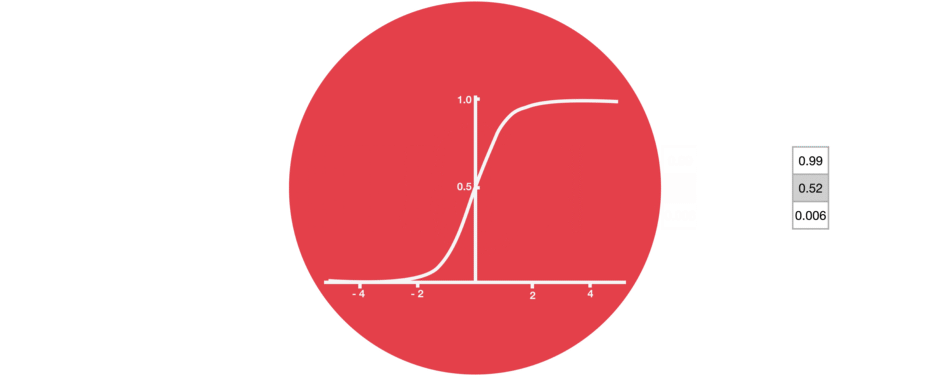
sigmoid激活函数(区间0~1)
-
遗忘门(sigmoid激活函数)
-
输出门:决定记忆单元中的哪些信息应该被输出到当前时间步的隐藏状态中。
输出门同样由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息应该被输出,而tanh函数则处理记忆单元的状态以准备输出。
输出门(sigmoid激活函数 + tanh激活函数)

Transformer:一种基于自注意力机制的神经网络结构,通过并行计算和多层特征抽取,有效解决了长序列依赖问题,实现了在自然语言处理等领域的突破。
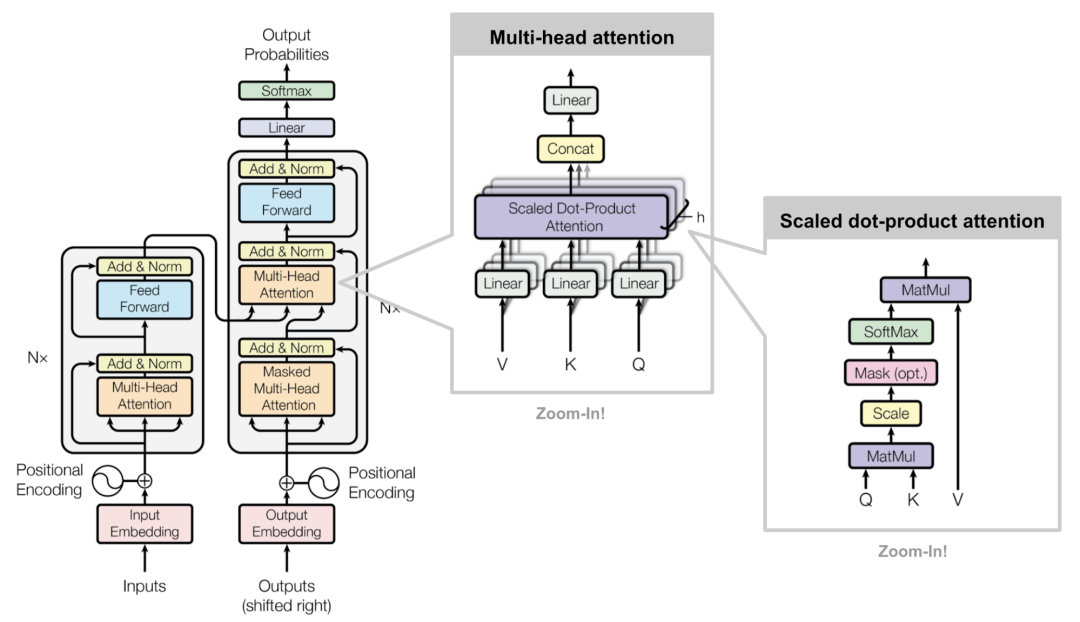
网络结构:由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
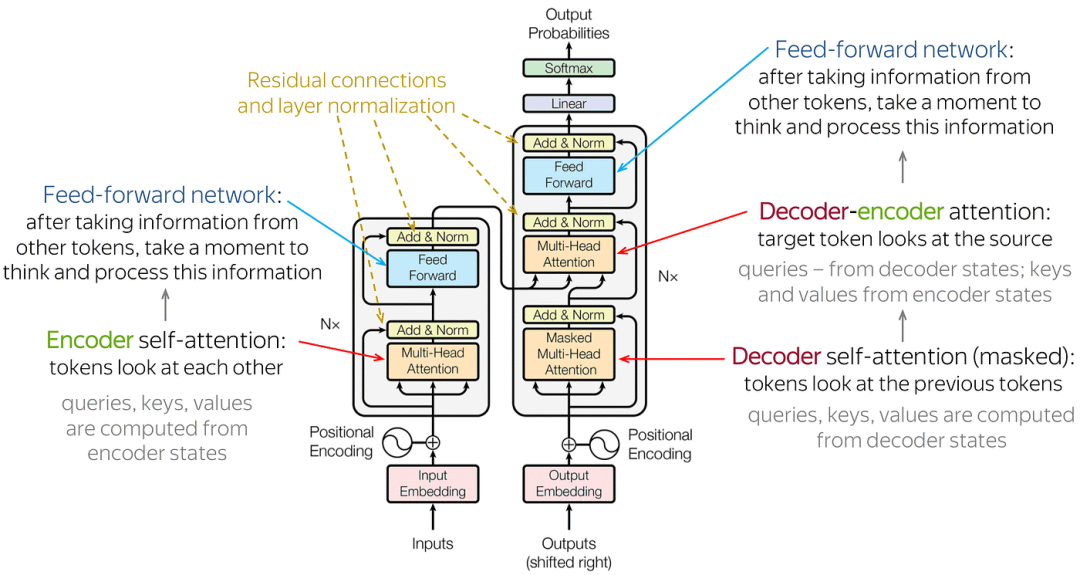
Transformer架构
-
输入部分:
-
源文本嵌入层: 将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
-
位置编码器: 为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
-
目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
-
编码器部分:
-
由N个编码器层堆叠而成。
-
每个编码器层由两个子层连接结构组成:第一个子层是一个多头自注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
-
解码器部分:
-
由N个解码器层堆叠而成。
-
每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
-
输出部分:
-
线性层: 将解码器输出的向量转换为最终的输出维度。
-
Softmax层: 将线性层的输出转换为概率分布,以便进行最终的预测。
解决问题:
-
长期依赖问题:在处理长序列输入时,传统的循环神经网络(RNN)会面临长期依赖问题,即难以捕捉序列中的远距离依赖关系。Transformer模型通过自注意力机制,能够在不同位置对序列中的每个元素赋予不同的重要性,从而有效地捕捉长距离依赖关系。
-
并行计算问题:传统的RNN模型在计算时需要按照序列的顺序依次进行,无法实现并行计算,导致计算效率较低。而Transformer模型采用了编码器-解码器结构,允许模型在输入序列上进行编码,然后在输出序列上进行解码,从而实现了并行计算,大大提高了模型训练的速度。
-
特征抽取问题:Transformer模型通过自注意力机制和多层神经网络结构,能够有效地从输入序列中抽取丰富的特征信息,为后续的任务提供更好的支持。
工作原理:
Transformer工作原理
-
输入线性变换:对于输入的Query(查询)、Key(键)和Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
-
分割多头:经过线性变换后,Query、Key和Value向量被分割成多个头。每个头都会独立地进行注意力计算。
-
缩放点积注意力:在每个头内部,使用缩放点积注意力来计算Query和Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。
-
注意力权重应用:将计算出的注意力权重应用于Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
-
拼接和线性变换:将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的Multi-Head Attention输出。
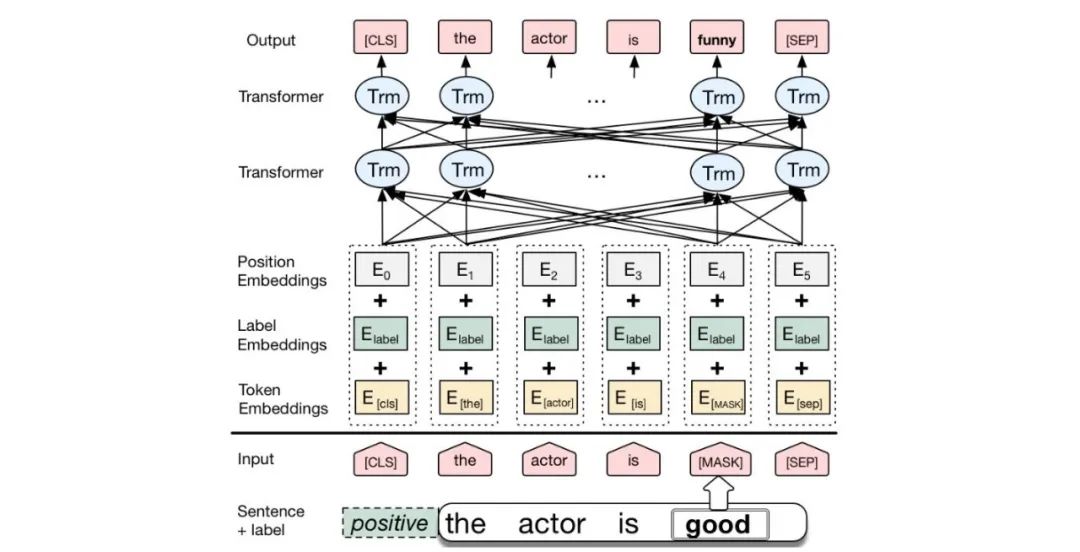
BERT: BERT是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了双向 Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。
BERT架构
- 输入层(Embedding):
-
Token Embeddings:将单词或子词转换为固定维度的向量。
-
Segment Embeddings:用于区分句子对中的不同句子。
-
Position Embeddings:由于Transformer模型本身不具备处理序列顺序的能力,所以需要加入位置嵌入来提供序列中单词的位置信息。
-
编码层(Transformer Encoder):BERT模型使用双向Transformer编码器进行编码。
-
输出层(Pre-trained Task-specific Layers):
-
MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。
-
NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。
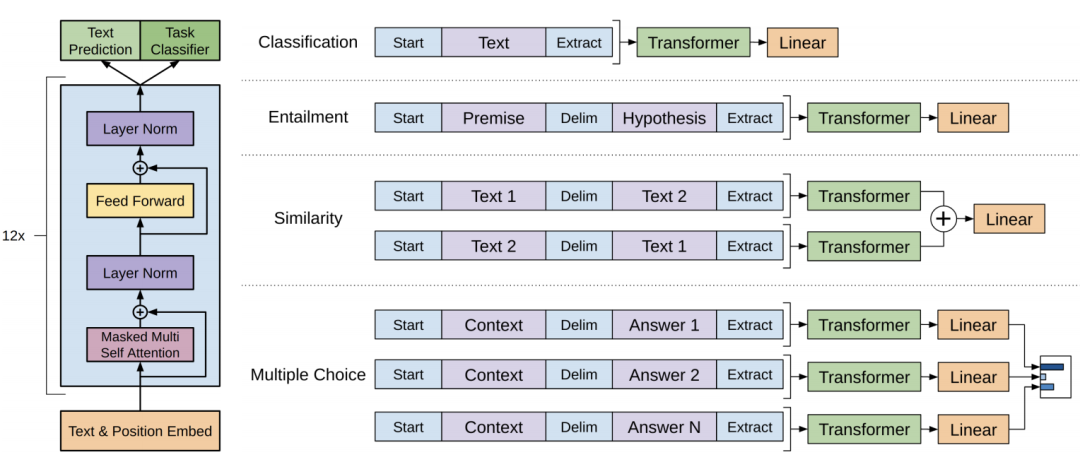
GPT: GPT也是一种基于Transformer的预训练语言模型,它的最大创新之处在于使用了单向 Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。
GPT架构
- 输入层(Input Embedding):
-
将输入的单词或符号转换为固定维度的向量表示。
-
可以包括词嵌入、位置嵌入等,以提供单词的语义信息和位置信息。
-
编码层(Transformer Encoder):GPT模型使用单向Transformer编码器进行编码和生成。
-
输出层(Output Linear and Softmax):
-
线性输出层将最后一个Transformer Decoder Block的输出转换为词汇表大小的向量。
-
Softmax函数将输出向量转换为概率分布,以便进行词汇选择或生成下一个单词。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}