







《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
##创建一个hadoop用户
$ sudo adduser hadoop
##将hadoop用户添加进sudo用户组
$ sudo usermod -G sudo hadoop
2. 安装JDK并配置环境变量
Ubuntu自带的jdk是open jdk 的,当然也可以用,但是感觉之前在Windows上都是用的sun jdk,对正宗的jdk还是更亲切些,并且sun jdk 比open jdk 功能更强大,更全所以就下载安装了sun jdk 。
jdk 下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

下载下来后,可以把jdk 装(解压)在你想要的目录:
tar -zxvf jdk-8u171-linux-x64.tar.gz
比如我的jdk 就放在了 /usr/local/jdk/jdk1.8.0_211 目录下。接下来配置环境变量。说实话这个折痛了我很久,差不多花了我4、5个小时才弄好,归根结底还是Linux系统不熟悉导致的,不过不经历风雨怎见彩虹,走过的路每一步都算数。不折痛这一番怎让自己印象深刻。
配置Java环境变量可以在两个地方配置:1. 修改 /ect/profiles 这是系统的配置文件,修改起来有风险,我就是掉到这个坑去了,因为把在这个配置文件中加上Java环境变量,然后没有配置。结果导致我重启电脑后死活进不去,选择用户,输入正确的密码,然后又自动调回登录界面了,吓得我不行,以为我把系统搞崩了,网上这种情况方法一大推,找到属于自己的才行,我也是想着我只修改了这个文件才导致的。所以大家碰到这个一直在登录界面循环的问题,还是要认真分析自己之前做了什么才导致的。我也在网上找了很久,最后把这个/etc/profiles这个文件的内容改正确了,才能正确的进入系统。
2.修改用户目录的.bashrc文件。这个配置文件是针对当前用户的。比如上面我创建的Hadoop用户,那当我用这个用户进入系统的时候,怎么能使用jdk呢,就是在./bashrc添加java环境变量就可以了。个人建议,修改用户目录的.bashrc 文件比较靠谱,风险小些。
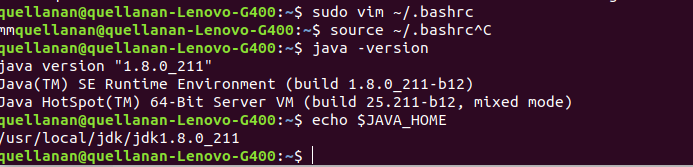
sudo vim ~/.bashrc
进入到.bashrc 文件后,在最后加上下面配置,jdk路径写自己的
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.: J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
export PATH=.: J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:PATH

保存退出后,执行
$ source ~/.bashrc
##让上面修改的文件生效,和重启电脑起到相同效果。
##接下来测试一下你的java环境变量是否配置好了把
$ java -version
$ java
$ javac
$ echo $JAVA_HOME
上面的四个都可以试试,配置好了是有的
3.配置ssh免密登录
切换到 hadoop 用户,hadoop 用户时密码为 hadoop。后续步骤都将在 hadoop 用户的环境中执行。
$ su hadoop
配置ssh环境免密码登录。 在/home/hadoop目录下执行
$cd ~
$ ssh-keygen -t rsa #一路回车
$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
$ chmod 600 .ssh/authorized_keys
验证登录本机是否还需要密码,第一次需要密码以后不需要密码就可以登录。
$ ssh localhost
#仅需输入一次hadoop密码,以后不需要输入

4.下载并安装Hadoop
我选的是Hadoop 2.6.0,大家可以选择自己想要的Hadoop版本,但是方法都是一样的
$ wget http://labfile.oss.aliyuncs.com/hadoop-2.6.0.tar.gz
$ tar zxvf hadoop-2.6.0.tar.gz
$ chmod 777 /home/hadoop/hdfs/hadoop-2.6.0
为什么要修改文件夹的权限呢,因为下载的的Hadoop解压后的所有者和用户组是20000,不知道你们是什么,应该不是你的当前用户,所以你当前用户在操作这个文件的时候总提示权限不足,者也是后面的一个坑啊。
5.配置Hadoop
一样的,打开当前用户的.bashrc 文件,进行修改
#HADOOP START
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.: J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
export HADOOP_HOME=/home/hadoop/hdfs/hadoop-2.6.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export PATH=.: J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:PATH: H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin
#HADOOP END

其实配置Hadoop用不到这么多,之后待会部署伪分布式模式的时候要加上这些变量,所以才一次给出来,如果只配置单机模式,配置下面就好
#JAVA
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.: J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
#HADOOP START
export HADOOP_HOME=/home/hadoop/hdfs/hadoop-2.6.0
export PATH=.: J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:PATH: H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin
#HADOOP END
保存之后,同样执行$ source ~/.bashrc生效。
6. 单机模式测试
到此其实单机模式就已经配置好了。现在可以看看你的hadoop 配置好没。
$ hadoop version
会显示出当前你安装的hadoop 版本,证明安装成功啦
接下来测试一下:
创建输入临时目录的内容文件。可以在任何地方创建此输入目录用来工作。
$ mkdir input
$ cp $HADOOP_HOME/*.txt input
$ ls -l input
它会在输入目录中的给出以下文件:
total 24
-rw-r–r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r–r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r–r-- 1 root root 1366 Feb 21 10:14 README.txt
接下来进行Hadoop自带的单词统计的例子
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.6.0.jar wordcount input ouput
这里我也碰到一个坑,就是上面的说的权限问题。我执行这个语句之后,疯狂报错,最后仔细看看是创建ouput文件夹以及生成里面的文件失败。最后也是找了很久才知道把权限改一下,然后就正常运行了。
看看结果:
cat ouput/*

到此就单机模式部署好啦,接下虚分布模式
7. 伪分布模式部署
伪分布模式,修改的配置文件有点多,一步一步来。
1.首先修改.bashrc 把文章前面说的那些变量加上去。最后的效果图再看一遍
2.接下来的配置修改都是在这个目录下的。
$ cd $HADOOP_HOME/etc/hadoop

3.修改 hadoop-env.sh
把JAVA_HOME路径改成你对应的路径,不然最后测试会提示找不到JAVA_HOME

4.修改 core-site.xml
core-site.xml文件中包含如读/写缓冲器用于Hadoop的实例的端口号的信息,分配给文件系统存储,用于存储所述数据存储器的限制和大小。
打开core-site.xml 并在,标记之间添加以下属性。
fs.default.name
hdfs://localhost:9000
5.修改hdfs-site.xml
hdfs-site.xml 文件中包含如复制数据的值,NameNode路径的信息,,本地文件系统的数据节点的路径。这意味着是存储Hadoop基础工具的地方。
打开这个文件,并在这个文件中的标签之间添加以下属性。
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hadoopinfra/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hadoopinfra/hdfs/datanode
读者福利
由于篇幅过长,就不展示所有面试题了,感兴趣的小伙伴



更多笔记分享

《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
dfs.data.dir
file:///home/hadoop/hadoopinfra/hdfs/datanode
读者福利
由于篇幅过长,就不展示所有面试题了,感兴趣的小伙伴
[外链图片转存中…(img-n8zj3oLY-1714770318400)]
[外链图片转存中…(img-HXpDFXTW-1714770318400)]
[外链图片转存中…(img-r6jwYc28-1714770318401)]
更多笔记分享
[外链图片转存中…(img-0DCQGFjJ-1714770318401)]
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









