







MovieLens数据集介绍
MovieLens 100k数据集,下载地址:http://files.grouplens.org/datasets/movielens/ml-100k.zip
MovieLens数据集保存了用户对电影的评分。基于这个数据集,我们可以测试一些推荐算法、评分预测算法。
MovieLens 100k
该数据集记录了943个用户对1682部电影的共100,000个评分,每个用户至少对20部电影进行了评分。
文件u.info保存了该数据集的概要:
943 users
1682 items
100000 ratings
文件u.item保存了item的信息,也就是电影的信息,共1682部电影。每一行代表一部电影,格式如下
movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy |
Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western |
比如第一行如下:
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
总共有1862行这样的数据。最后19个字段保存的是该电影的类型,一个字段对应一个类型,值为0代表不属于该类型,值为1代表属于该类型,类型信息保存在文件u.genre中。
文件u.genre保存了电影的类型信息。
文件u.user保存了用户的信息,共有943个用户,其id依次是1、2、……、943。文件中每一行保存了一个用户的信息,格式如下:
user id | age | gender | occupation | zip code 文件u.occupation保存了用户职业的集合。
具体如
1|24|M|technician|85711
2|53|F|other|94043
文件u.data保存了所有的评分记录,每一行是一个用户对一部电影的评分,共有100000条记录。当然,如果某用户没有对某电影评分,则不会包含在该文件中。评分的分值在1到5之间,就是1、2、3、5这5个评分。每一行格式如下:
user id | item id | rating | timestamp
具体如:
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
其中,item id就是电影的id,时间戳timestamp是评分时间。可以自己对时间戳进行转换,一般在20世纪90年代。
将u.data按照80%/20%的比例分成u1.base和u1.test,可以将u1.base作为训练集,u1.test作为测试集。u2、u3、u4、u5系列文件和u1类似。u1、u2、u3、u4、u5的测试集是不相交的,它们可以用来做(5折交叉验证)5 fold cross validation。
文件ua.base和文件ua.test也是由u.data拆分而来,在ua.test中包含了每个用户对10部电影的评分,从u.data去掉ua.test得到ua.base。ub.base和ub.test也使用了同样的生成方法。另外,ua.test和ub.test是不相交的。
另外还可以下到更大的数据集
MovieLens 1M
该数据集保存的是6040个用户对3952部电影的1000209个评分记录。具体可以参考其README文件。
MovieLens 10M
71567个用户,10681部电影,10000054条评分记录,同时多了个用户为电影设置的标签。具体可以阅读其中的README.html。
Tag Genome
该数据集下有三个数据文件。
**movies.dat:**其每一行的格式是:
<MovieID><Title><MoviePopularity>
MoviePopularity是在MovieLens中对该电影的评分次数。
**tag.dat:**每一行的格式是:
<TagID><Tag><TagPopularity>
是使用该Tag的用户数,一个用户最多算1次。
**tag_relevance.dat:**每一行的格式是:
<MovieID><TagID><Relevance>
的值在0和1之间,值越大,Tag与Movie的关联性越强。
数据探索
探索用户数据
要运行spark程序,即使是独立模式,或者直接在类似pycharm的软件中连接spark,也要先启动spark集群。
#先载入数据
from pyspark import SparkConf,SparkContext
from pyspark.sql import SparkSession
sc=SparkContext()
user_data=sc.textFile("/home/digger/下载/ml-100k/u.user")
#初步看一样数据的样子
print(user_data.first())
结果如下:
1|24|M|technician|85711
从这样的数据里,我们可以对用户的年龄、性别、职业、地区进行统计(这里以邮编代替地区)
“ | ”字符来分隔各行数据,这将生成一个本地RDD,其中每一个记录对应一个Python列表,各列表由用户ID(user ID)、年龄(age)、性别(gender)、职业(occupation)和邮编(ZIP code)五个属性构成。
user_fields=user_data.map(lambda line:line.split('|'))
num_user=user_fields.map(lambda field:field[0]).count()
num_gender=user_fields.map(lambda field:field[2]).distinct().count()#distinct用于去重,count()用于计数
num_occupation=user_fields.map(lambda field:field[3]).distinct().count()
num_zipcode=user_fields.map(lambda field:field[4]).distinct().count()
print("共有用户:%d户,性别:%d类,职业%d类,邮编:%d种"%(num_user,num_gender,num_occupation,num_zipcode))
结果如下:
共有用户:943户,性别:2类,职业21类,邮编:795种
#下面来查看年龄的分布
import matplotlib.pyplot as plt
import seaborn as sns
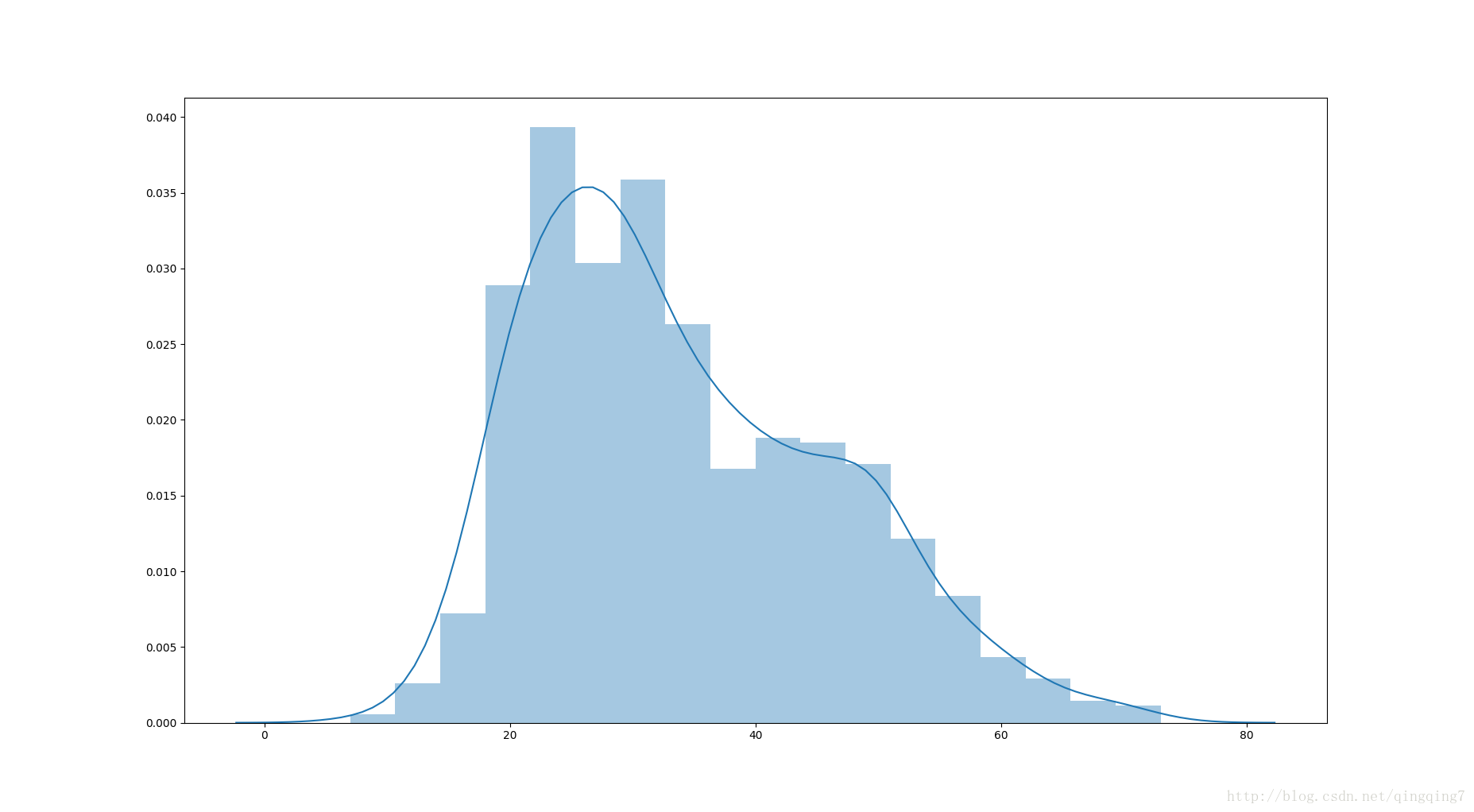
ages= user_fields.map(lambda field:field[1]).colletct()#返回RDD的所有元素,方便后面对age进行统计,之后就可以利用单机的一切函数了
ax=sns.distplot(ages)
plt.show()
结果如下:
从上图可以看到,该网站的用户以年经人为主,尤其与27-30岁人群最多。
#下面统计职业的频率直方图
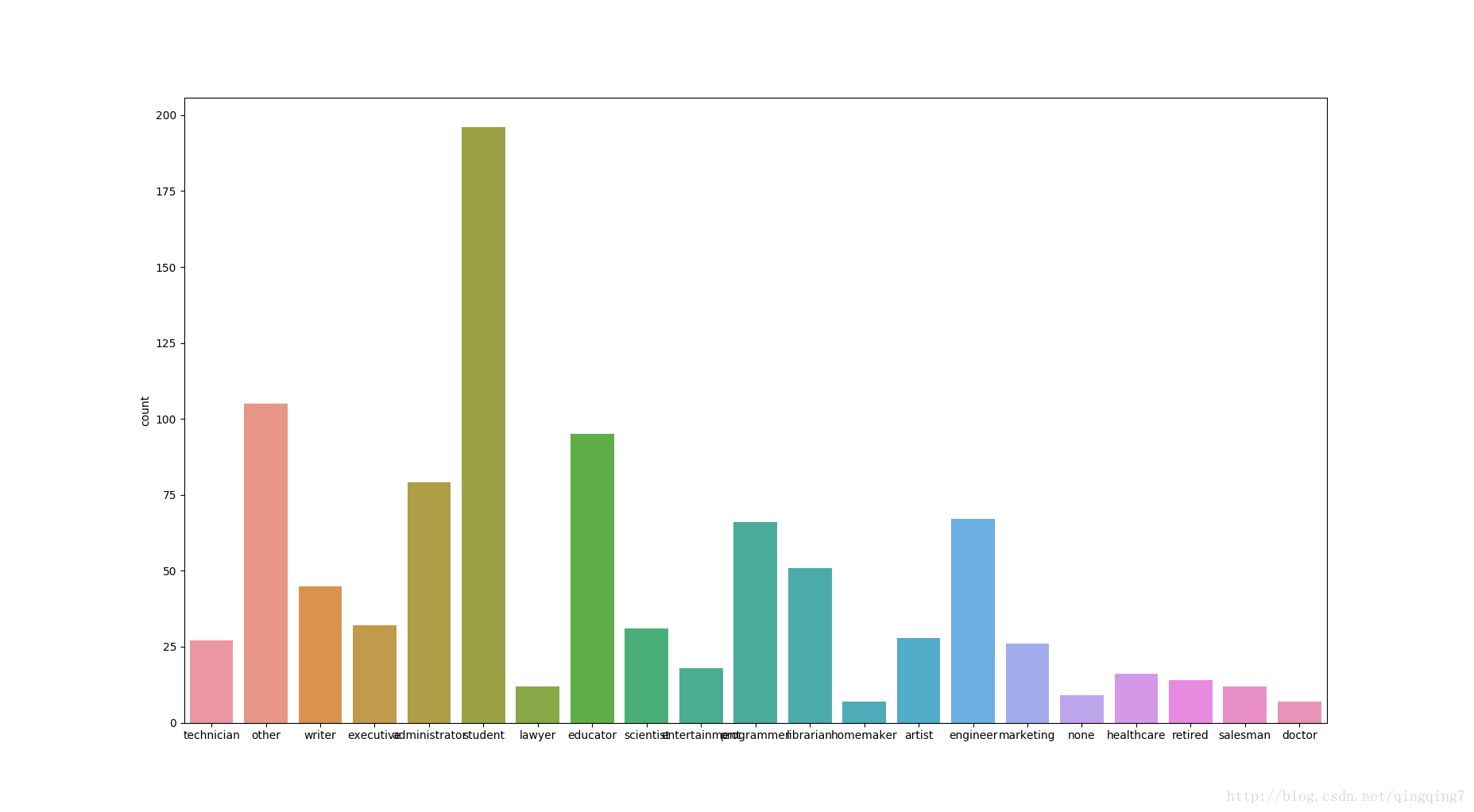
occupations=user_fields.map(lambda field:field[3]).collect()#当数据不大时,我们可以用这种方法将所有元素收集起来
ax=sns.countplot(x=occupations)
plt.show()
#当数据量很大的时候,不要直接用collect()的
上面的图形结果如下:
从图上可以看到,用户中人数排在前五的职业分别是学生、教育工作者、管理员、程序员和工程师。
**注意:**当数据量很大的时候,是不能用collect()的,要不整个集群卡死;此时如果需要展现数据的统计信息,应该先进行统计,统计的话就可以想办法设计成可拆分的任务,让各个节点进行一小块的统计任务,最后在汇总统计数据,数据量再大,汇总后也就那些指标,此时再来画图就很简单,可在单机上进行。而不应该边像上面那样直接将所有数据collect起来,然后直接画图,此时countplot同时承担了统计和画图的任务,对于大数据来讲,怎么吃得消呢。
另外,spark并不擅长画图这一类事情,个人觉得如果要统计消息,可以采取抽样的方式,在整个大数据集中获取一小部分数据,然后在单机上就可以利用这些统计类的画图函数来展示数据特点了。抽样本来就是我们认识客观世界的一种方式,初步展示不一定要大而全。
下面用分布式的思维进行统计和展示
occupation_count=user_fields.map(lambda fields:(fields[3],1))#这一步先每出现一次职业就计一次数,只要对这些数字求和就可以知道各个职业出现了多少次,即得到各职业的频率分布
occupation_counts=occupation_count.reduceByKey(lambda x,y:x+y)#利用reduceByKey()函数对各条数据进行归并,达到统计目的
occupation_counts=occupation_counts.collect()#此时不用担心数据量的问题,经过前面的shuffle过程,此时数据已经被归为有限的数目了,从前面对职业个数的统计知道,现在数据只有21对,前面是职业名称,后面是对应的人数
print(occupation_counts)
结果如下:
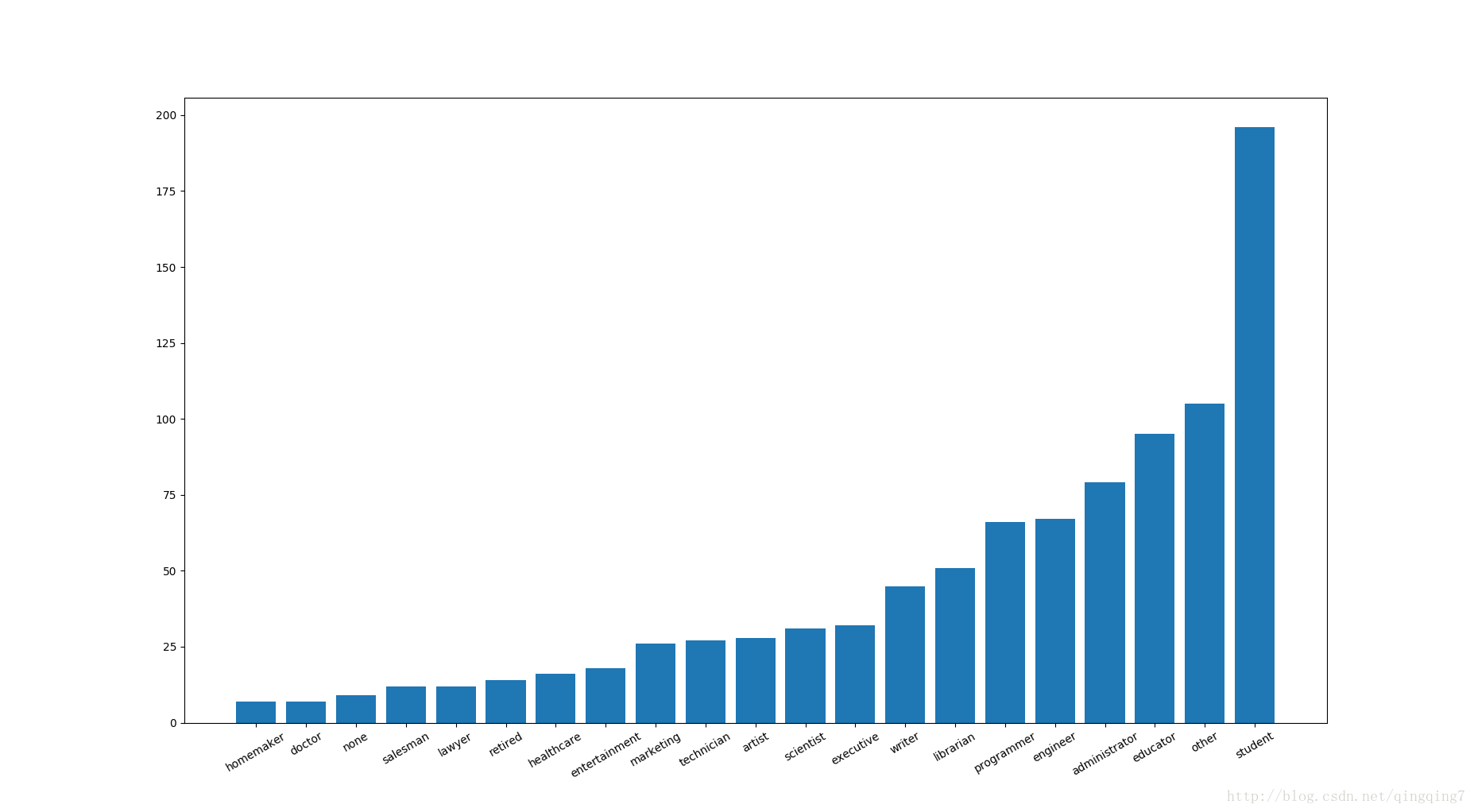
[('engineer', 67), ('homemaker', 7), ('doctor', 7), ('administrator', 79), ('student', 196), ('programmer', 66), ('other', 105), ('executive', 32), ('retired', 14), ('artist', 28), ('none', 9), ('educator', 95), ('scientist', 31), ('lawyer', 12), ('writer', 45), ('technician', 27), ('librarian', 51), ('salesman', 12), ('healthcare', 16), ('marketing', 26), ('entertainment', 18)]
#下面提取出职业和对应的人数
x_label=np.array([i[0] for i in occupation_counts])
y=np.array([i[1] for i in occupation_counts])
#我们先对统计结果进行排序以便于展现
x_label=x_label[np.argsort(y)]
y=y[np.argsort(y)]
print(x_label)
print(y)
x_pos=np.arange(len(y))#设置每一个条形图的中心位置,要不没办法画图,条形图传数值型的x,y进去;同时也作为xticks的中心位置,这样就实现了用字符对x轴进行标
plt.bar(x_pos,y)
plt.xticks(x_pos,x_label,rotation=30)#xticks与xlabel是不一样,前者就跟刻度线一样的,后者只是说明x轴代表什么。
plt.show()
结果如下:















 9417
9417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









