







逻辑回归的特点
逻辑回归的用途
第一用来预测,第二寻找因变量的影响因素。
逻辑回归的适用范围
数据类型
自变量可以是离散值,也可以是连续值;
因变量是二分类变量,也可以是多分类;(多分类使用softmax函数而不是sigmoid函数)
逻辑回归中的离散变量
数据不平衡问题:
训练结果会偏袒大类:
来源:Logistic回归的非平衡数据问题及其解决方法
Logistic模型对非平衡数据的敏感性:测度、修正与比较
小类配平和大类配平
逻辑回归的优点
原理的相对简单,可解释性强等优点,它还可以作为众多集成算法以及深度学习的基本组成单位
Logistic回归分析报告结果解读分析
逻辑回归的局限性
逻辑回归模型的引入(从线性回归到Logistic回归)
广义线性模型
这一家族中模型的形式基本一致,不同的是因变量不同
- 如果是连续的,就是线性回归
- 如果是二项分布,就是logistic回归
- 如果是poisson分布,就是poisson回归
- 如果负二项分布,就是负二项回归
线性回归和Logistic回归都是广义线性模型的特例。
假设有一个因变量
y
y
y和一组自变量
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
x_1, x_2, x_3, ... , x_n
x1,x2,x3,...,xn,其中
y
y
y为连续变量,我们可以拟合一个线性方程:
y
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
⋯
+
w
n
∗
x
n
−
−
−
−
−
(
1
)
y =w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +\cdots+w_n*x_n-----(1)
y=w0+w1∗x1+w2∗x2+w3∗x3+⋯+wn∗xn−−−−−(1)
并通过最小二乘法估计各个
w
w
w系数的值。
如果
y
y
y为二分类变量,只能取值0或1,那么线性回归方程就会遇到困难: 方程右侧是一个连续的值,取值为负无穷到正无穷,而左侧只能取值[0,1],无法对应。为了继续使用线性回归的思想,统计学家想到了一个变换方法,就是将方程右边的取值变换为[0,1]。最后选中了sigmoid函数:
s
(
x
)
=
1
1
+
e
−
x
s(x)=\frac{1}{1+e^{-x}}
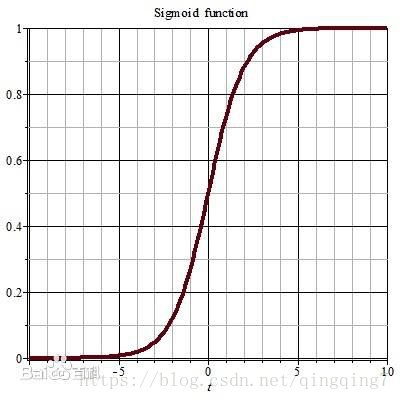
s(x)=1+e−x1,sigmoid函数曲线如下:
Sigmoid函数在两侧能很快收敛至0和1,此特性很适合逻辑回归的需要,将方程(1)右侧代入sigmoid函数有
y
=
1
1
+
e
−
(
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
)
−
−
−
−
(
2
)
y=\frac{1}{1+e^{-(w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n)}}----(2)
y=1+e−(w0+w1∗x1+w2∗x2+w3∗x3+...+wn∗xn)1−−−−(2)
按照(2)式,对于任意取值的x,因变量y的取值范围都为(0~1);但是在分类模型中,y的取值只能是1或0;如果令
y
=
p
y=p
y=p,我们还需要做一些规定,比如当
p
≥
0.5
p\geq 0.5
p≥0.5时,y的取值为1;当
p
<
0.5
p< 0.5
p<0.5时,y的取值为0;当我们通过一定的方法,得到一组合适的参数
w
0
、
w
1
、
w
2
、
w
3
、
.
.
.
、
w
n
w_0 、w_1、w_2、w_3、...、w_n
w0、w1、w2、w3、...、wn,那么只要样本代入(2)式,根据计算出来p值的大小就可以对的样本的类别进行判定;此时结果p就相当于y取1的概率,与此对应的,y取0的概率为
1
−
p
1-p
1−p。sigmoid函数好处在于在x=0的两侧能很快收敛至0和1,保证能够匹配大部分样本的类别。
那么如何来求解这样一组参数呢?
参数的最优解应该要满足这样的要求:最优参数应该让尽可能多的样本在给定的属性值下其类别尽可能呈现其本来的样子;也就是对于全体样本,在给定的属性值和类别取值下,通过(2)式计算得到的类别取值的联合概率应该最大。
这里我们就引出了逻辑回归模型参数求解的目标函数。
补充知识:
优势
Ω
\Omega
Ω
优势,是事件发生与不发生概率之比,用符号
Ω
\Omega
Ω来表示。
Ω
=
p
1
−
p
=
e
(
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
)
\Omega=\frac{p}{1-p}=e^{(w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n)}
Ω=1−pp=e(w0+w1∗x1+w2∗x2+w3∗x3+...+wn∗xn)
Ω
\Omega
Ω是
p
p
p的单调函数,保证了
Ω
\Omega
Ω和p增长的一致性,
Ω
Ω
Ω的取舍范围是
(
0
,
+
∞
)
(0,+\infty)
(0,+∞);
如果再对
Ω
\Omega
Ω取对数,则有
l
n
Ω
=
l
n
p
1
−
p
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
ln\Omega=ln\frac{p}{1-p}=w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n
lnΩ=ln1−pp=w0+w1∗x1+w2∗x2+w3∗x3+...+wn∗xn
l
o
g
i
t
logit
logit变换
上述两步变换称为
l
o
g
i
t
logit
logit变换,
l
n
Ω
ln\Omega
lnΩ称为
l
o
g
i
t
P
logitP
logitP,
l
o
g
i
t
P
logitP
logitP的取舍范围
(
−
∞
,
+
∞
)
(-\infty,+\infty)
(−∞,+∞),与一般线性回归模型吻合,同时与p之间保值单调一致性。这样我们完成了从一般线性回归到逻辑回归的转换。
l
o
g
i
t
logit
logit变换在后面的参数求解中还会用到,可以简化推导过程。
逻辑回归模型的参数估计
设
y
y
y是0-1型变量,
(
x
1
,
x
2
,
…
,
x
p
)
(x_1,x_2,\dots,x_p)
(x1,x2,…,xp)是与
y
y
y相关的确定性变量即特征变量;n组观测数据,记为
(
x
i
1
,
x
i
2
,
…
,
x
i
p
;
y
i
)
(
i
=
1
,
2
,
…
,
n
)
(x_{i1},x_{i2},\dots,x_{ip};y_i)(i=1,2,\dots,n)
(xi1,xi2,…,xip;yi)(i=1,2,…,n),其中
y
i
y_i
yi是取值为0或1的随机变量。
y
i
y_i
yi是均值为
p
i
p_i
pi的0-1分布,概率函数为
P
(
y
i
=
1
)
=
p
i
P(y_i=1)=p_i
P(yi=1)=pi;
P
(
y
i
=
0
)
=
1
−
p
i
P(y_i=0)=1-p_i
P(yi=0)=1−pi,我们可以将概率函数合写为
P
(
y
i
)
=
p
i
y
i
(
1
−
p
i
)
1
−
y
i
;
i
=
1
,
2
,
…
,
n
;
y
i
=
0
,
1
P(y_i)=p_i^{y_i}(1-p_i)^{1-y_i};i=1,2,\dots,n;y_i=0,1
P(yi)=piyi(1−pi)1−yi;i=1,2,…,n;yi=0,1;于是
(
y
1
,
y
2
,
…
,
y
n
)
(y_1,y_2,\dots,y_n)
(y1,y2,…,yn)的似然函数可以写作
L
=
∏
i
=
1
n
p
(
y
i
)
=
∏
i
=
1
n
p
i
y
i
(
1
−
p
i
)
1
−
y
i
−
−
−
−
(
3
)
L=\prod_{i=1}^{n} p(y_i)=\prod_{i=1}^{n}p_i^{y_i}(1-p_i)^{1-y_i}----(3)
L=i=1∏np(yi)=i=1∏npiyi(1−pi)1−yi−−−−(3)
(3)式中
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}
pi=1+e−(w0+w1xi1+⋯+wpxip)1,我们的目标就是求取一组参数
w
0
、
w
1
、
…
、
w
p
w_0 、w_1 、\dots、w_p
w0、w1、…、wp,使的似然函数L最大。
为了计算方便,对
L
L
L取对数(为什么要取对数呢?因为取对数后,乘法就变成了加法,后面利用梯度下降法时可更好的求偏导,且未改变原似然函数的单调性,如果lnL取到最大值则L也能取到最大值。)
l
n
L
=
l
n
(
∏
i
=
1
n
p
i
y
i
(
1
−
p
i
)
1
−
y
i
)
=
l
n
(
∏
i
=
1
n
p
i
y
i
)
+
l
n
(
∏
i
=
1
n
(
1
−
p
i
)
1
−
y
i
)
=
∑
i
=
1
n
y
i
l
n
p
i
+
∑
i
=
1
n
(
1
−
y
i
)
l
n
(
1
−
p
i
)
=
∑
i
=
1
n
l
n
(
1
−
p
i
)
+
∑
i
=
1
n
y
i
l
n
p
i
1
−
p
i
\begin{matrix} lnL&=&ln(\prod_{i=1}^{n}p_i^{y_i}(1-p_i)^{1-y_i})\\ &=&ln(\prod_{i=1}^{n}p_i^{y_i})+ln(\prod_{i=1}^{n}(1-p_i)^{1-y_i})\\ &=&\sum_{i=1}^{n}y_i lnp_i+\sum_{i=1}^{n}(1-y_i) ln(1-p_i)\\ &=&\sum_{i=1}^{n}ln(1-p_i) +\sum_{i=1}^{n}y_iln\frac{p_i}{1-p_i}\\ \end{matrix}
lnL====ln(∏i=1npiyi(1−pi)1−yi)ln(∏i=1npiyi)+ln(∏i=1n(1−pi)1−yi)∑i=1nyilnpi+∑i=1n(1−yi)ln(1−pi)∑i=1nln(1−pi)+∑i=1nyiln1−pipi
将
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}
pi=1+e−(w0+w1xi1+⋯+wpxip)1及
l
n
Ω
=
l
n
p
1
−
p
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
ln\Omega=ln\frac{p}{1-p}=w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n
lnΩ=ln1−pp=w0+w1∗x1+w2∗x2+w3∗x3+...+wn∗xn代入到上式,可以得到
l
n
L
=
−
∑
i
=
1
n
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
+
∑
i
=
1
n
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
=
∑
i
=
1
n
[
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
−
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
]
\begin{matrix} lnL&=&-\sum_{i=1}^{n}ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) + \sum_{i=1}^{n} y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})\\ &=&\sum_{i=1}^{n} \left[y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})-ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) \right]\\ \end{matrix}
lnL==−∑i=1nln(1+e(w0+w1xi1+⋯+wpxip))+∑i=1nyi(w0+w1xi1+⋯+wpxip)∑i=1n[yi(w0+w1xi1+⋯+wpxip)−ln(1+e(w0+w1xi1+⋯+wpxip))]
令
w
=
(
w
0
,
w
1
,
…
,
w
p
)
T
,
x
i
=
(
1
,
x
i
1
,
…
,
x
i
p
)
T
,
x
i
中
添
加
了
1
是
为
了
与
w
相
匹
配
w=(w_0,w_1,\dots,w_p)^T,x_i=(1,x_{i1},\dots,x_{ip})^T,x_i中添加了1是为了与w相匹配
w=(w0,w1,…,wp)T,xi=(1,xi1,…,xip)T,xi中添加了1是为了与w相匹配。
则
l
n
L
lnL
lnL可写成如下形式:
l
n
L
=
∑
i
=
1
n
[
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
−
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
]
=
∑
i
=
1
n
[
y
i
w
T
x
i
−
l
n
(
1
+
e
w
T
x
i
)
]
\begin{matrix} lnL&=&\sum_{i=1}^{n} \left[y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})-ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) \right]\\ &=&\sum_{i=1}^{n} \left[ y_i w^T x_i-ln(1+e^{w^T x_i})\right]\\ \end{matrix}
lnL==∑i=1n[yi(w0+w1xi1+⋯+wpxip)−ln(1+e(w0+w1xi1+⋯+wpxip))]∑i=1n[yiwTxi−ln(1+ewTxi)]
如何选取一组参数
w
0
、
w
1
、
…
、
w
p
w_0 、w_1 、\dots、w_p
w0、w1、…、wp使得上式最大,这是一个最优化问题。考虑到参数数量的不确定,即参数数量很大,此时直接求解方程组的解变的很困难,或者根本就求不出精确的参数。于是,可以采用梯度下降法和牛顿法等最优化算法。
使用梯度上升法(梯度下降法)求解逻辑回归模型的参数
l
n
L
lnL
lnL取到最大值,即
J
(
w
)
=
−
l
n
L
(
w
)
J(w)=- lnL(w)
J(w)=−lnL(w)取到最小值.
如果采用梯度下降法求最小值,则
β
β
β的更新过程应当如下:
w
=
w
−
α
∂
J
(
w
)
∂
w
=
w
−
α
∂
(
−
l
n
L
(
w
)
)
∂
w
w = w -\alpha \frac{\partial J(w)}{\partial w}= w -\alpha \frac{\partial (-lnL(w))}{\partial w}
w=w−α∂w∂J(w)=w−α∂w∂(−lnL(w))
下面计算梯度部分。
∂
(
−
l
n
L
(
w
)
)
∂
w
=
∂
(
−
∑
i
=
1
n
[
y
i
w
T
x
i
−
l
n
(
1
+
e
w
T
x
i
)
]
)
∂
w
=
∂
(
∑
i
=
1
n
[
l
n
(
1
+
e
w
T
x
i
)
−
y
i
w
T
x
i
]
)
∂
w
=
∑
i
=
1
n
(
e
w
T
x
i
1
+
e
w
T
x
i
−
y
i
)
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
(
1
1
+
e
−
w
T
x
i
−
y
i
)
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
(
1
1
+
e
−
w
T
x
i
−
y
i
)
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w}&=&\frac{\partial (-\sum_{i=1}^{n} \left[ y_iw^T x_i-ln(1+e^{w^T x_i})\right])}{\partial w}\\ &=&\frac{\partial (\sum_{i=1}^{n} \left[ ln(1+e^{w^T x_i}) - y_i w^T x_i\right])}{\partial w}\\ &=&\sum_{i=1}^{n}(\frac{e^{w^T x_i}}{1+e^{w^T x_i}}-y_i)\frac{\partial{(w^T x_i)}}{\partial{ w}}\\ &=&\sum_{i=1}^{n}(\frac{1}{1+e^{-w^T x_i}}-y_i)\frac{\partial{(w^T x_i)}}{\partial{w}}\\ &=&\sum_{i=1}^{n}(\frac{1}{1+e^{-w^T x_i}}-y_i)\frac{\partial{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}{\partial{w}}\\ \end{matrix}
∂w∂(−lnL(w))=====∂w∂(−∑i=1n[yiwTxi−ln(1+ewTxi)])∂w∂(∑i=1n[ln(1+ewTxi)−yiwTxi])∑i=1n(1+ewTxiewTxi−yi)∂w∂(wTxi)∑i=1n(1+e−wTxi1−yi)∂w∂(wTxi)∑i=1n(1+e−wTxi1−yi)∂w∂(w0+w1xi1+⋯+wpxip)
不防令
1
1
+
e
−
w
T
x
i
−
y
i
=
e
i
\frac{1}{1+e^{-w^T x_i}}-y_i=e_i
1+e−wTxi1−yi=ei,注意看,其实
e
i
e_i
ei正好就是样本i的预测误差)则上式可化简为
∂
(
−
l
n
L
(
w
)
)
∂
w
=
∑
i
=
1
n
e
i
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w} &=&\sum_{i=1}^n e_i \frac{\partial (w^Tx_i)}{\partial w}\\ &=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w}\\ \end{matrix}
∂w∂(−lnL(w))==∑i=1nei∂w∂(wTxi)∑i=1nei∂w∂(w0+w1xi1+⋯+wpxip)
先计算
∂
(
−
l
n
L
(
w
)
)
∂
w
\frac{\partial (-lnL(w))}{\partial w}
∂w∂(−lnL(w))各分量
∂
(
−
l
n
L
(
w
)
)
∂
w
0
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
0
=
∑
i
=
1
n
e
i
∗
1
∂
(
−
l
n
L
(
w
)
)
∂
w
1
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
1
=
∑
i
=
1
n
e
i
∗
x
i
1
⋯
=
⋯
=
⋯
∂
(
−
l
n
L
(
w
)
)
∂
w
p
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
p
=
∑
i
=
1
n
e
i
∗
x
i
p
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w_0}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_0}&=&\sum_{i=1}^n e_i *1\\ \frac{\partial (-lnL(w))}{\partial w_1}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_1}&=&\sum_{i=1}^n e_i *x_{i1}\\ \cdots&=&\cdots&=&\cdots\\ \frac{\partial (-lnL(w))}{\partial w_p}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_p}&=&\sum_{i=1}^n e_i *x_{ip}\\ \end{matrix}
∂w0∂(−lnL(w))∂w1∂(−lnL(w))⋯∂wp∂(−lnL(w))====∑i=1nei∂w0∂(w0+w1xi1+⋯+wpxip)∑i=1nei∂w1∂(w0+w1xi1+⋯+wpxip)⋯∑i=1nei∂wp∂(w0+w1xi1+⋯+wpxip)====∑i=1nei∗1∑i=1nei∗xi1⋯∑i=1nei∗xip
故
∂
(
−
l
n
L
(
w
)
)
∂
w
\frac{\partial (-lnL(w))}{\partial w}
∂w∂(−lnL(w))可写成
∂
(
−
l
n
L
(
w
)
)
∂
w
=
[
∑
i
=
1
n
e
i
∗
1
∑
i
=
1
n
e
i
∗
x
i
1
⋯
∑
i
=
1
n
e
i
∗
x
i
p
]
=
[
e
1
+
e
x
+
⋯
+
e
n
e
1
x
11
+
e
2
x
21
+
⋯
+
e
n
x
n
1
⋯
e
1
x
1
p
+
e
2
x
2
p
+
⋯
+
e
n
x
n
p
]
=
[
1
+
x
11
+
x
12
+
⋯
+
x
1
p
1
+
x
21
+
x
22
+
⋯
+
x
2
p
⋯
1
+
x
n
1
+
x
n
2
+
⋯
+
x
n
p
]
T
∗
[
e
1
⋯
e
n
]
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w} &=& \left[ \begin{matrix} \sum_{i=1}^n e_i *1\\ \sum_{i=1}^n e_i *x_{i1}\\ \cdots\\ \sum_{i=1}^n e_i *x_{ip}\\ \end{matrix}\right]\\ &=& \left[ \begin{matrix} e_1+e_x+\cdots+e_n\\ e_1x_{11}+e_2x_{21}+\cdots+e_nx_{n1}\\ \cdots\\ e_1x_{1p}+e_2x_{2p}+\cdots+e_nx_{np}\\ \end{matrix}\right]\\ &=& \left[ \begin{matrix} 1+x_{11}+x_{12}+\cdots+x_{1p}\\ 1+x_{21}+x_{22}+\cdots+x_{2p}\\ \cdots\\ 1+x_{n1}+x_{n2}+\cdots+x_{np}\\ \end{matrix}\right]^T* \left[ \begin{matrix} e_1\\ \cdots\\ e_n\\ \end{matrix}\right]\\ \end{matrix}
∂w∂(−lnL(w))===⎣⎢⎢⎡∑i=1nei∗1∑i=1nei∗xi1⋯∑i=1nei∗xip⎦⎥⎥⎤⎣⎢⎢⎡e1+ex+⋯+ene1x11+e2x21+⋯+enxn1⋯e1x1p+e2x2p+⋯+enxnp⎦⎥⎥⎤⎣⎢⎢⎡1+x11+x12+⋯+x1p1+x21+x22+⋯+x2p⋯1+xn1+xn2+⋯+xnp⎦⎥⎥⎤T∗⎣⎡e1⋯en⎦⎤
记
[
1
,
x
11
,
x
12
,
⋯
 
,
x
1
p
1
,
x
21
,
x
22
,
⋯
 
,
x
2
p
⋯
1
,
x
n
1
,
x
n
2
,
⋯
 
,
x
n
p
]
=
X
\left[ \begin{matrix} 1,x_{11},x_{12},\cdots,x_{1p}\\ 1,x_{21},x_{22},\cdots,x_{2p}\\ \cdots\\ 1,x_{n1},x_{n2},\cdots,x_{np}\\ \end{matrix}\right] =X
⎣⎢⎢⎡1,x11,x12,⋯,x1p1,x21,x22,⋯,x2p⋯1,xn1,xn2,⋯,xnp⎦⎥⎥⎤=X
[
e
1
⋯
e
n
]
=
E
\left[ \begin{matrix} e_1\\ \cdots\\ e_n\\ \end{matrix}\right]=E
⎣⎡e1⋯en⎦⎤=E
则
∂
(
−
l
n
L
(
w
)
)
∂
w
=
X
T
E
\frac{\partial (-lnL(w))}{\partial w}=X^TE
∂w∂(−lnL(w))=XTE
实际上的计算应该不需要这么麻烦,但大学时学的偏微分和矩阵运算都忘光了。就采用这种笨一点的方法
则参数更新公式可写成
w
=
w
−
α
X
T
E
w=w-\alpha X^TE\\
w=w−αXTE
到此我们就将梯度下降法求解最优参数的更新公式推导出来了。初始化的时候,我们可以先令所有参数都为1,然后逐步迭代优化。迭代足够的次数或者前后再次更新变化很小,就可以停止迭代。
分界面的求解
通过定一个阈值,比如
p
0
=
0.5
p_0=0.5
p0=0.5,然后
p
≥
p
0
p\geq p_0
p≥p0是一类,则
p
<
p
0
p< p_0
p<p0是另一类;
即
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
≥
0.5
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }} \geq 0.5
pi=1+e−(w0+w1xi1+⋯+wpxip)1≥0.5是一类,
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
<
0.5
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }} < 0.5
pi=1+e−(w0+w1xi1+⋯+wpxip)1<0.5是另一类;
或者换一种表达
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
>
0
w_0+w_1 x_i1+⋯+w_p x_ip>0
w0+w1xi1+⋯+wpxip>0是一类,
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
<
0
w_0+w_1 x_{i1}+⋯+w_p x_{ip}<0
w0+w1xi1+⋯+wpxip<0是另一类;在原数据空间,
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w0+w1xi1+⋯+wpxip就是分界面。
类别预测
将测试数据代入方程
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }}
pi=1+e−(w0+w1xi1+⋯+wpxip)1,并确定一个阈值,如果定阈值为0.5,则在二分类模型中,
p
i
>
0.5
p_i>0.5
pi>0.5即为1,小于0.5即为0
逻辑回归用于多分类
来源:https://blog.csdn.net/szu_hadooper/article/details/78619001
普通的logistic回归只能针对二分类(Binary Classification)问题,要想实现多个类别的分类,我们必须要改进logistic回归,让其适应多分类问题。
关于这种改进,有两种方式可以做到。
第一种方式
是直接根据每个类别,都建立一个二分类器,带有这个类别的样本标记为1,带有其他类别的样本标记为0。假如我们有个类别,最后我们就得到了个针对不同标记的普通的logistic分类器。
假如给定数据集
X
∈
R
m
×
n
X\in R^{m\times n}
X∈Rm×n,它们的标记
Y
∈
R
k
Y\in R^k
Y∈Rk,即这些样本有个不同的类别。
我们挑选出标记为 c ( c ≤ k ) c(c\leq k) c(c≤k)的样本,将挑选出来的带有标记的样本的标记置为1,将剩下的不带有标记的样本的标记置为0。然后就用这些数据训练出一个分类器,我们得到 h c ( x ) h_c(x) hc(x)(表示针对标记的logistic分类函数)。
按照上面的步骤,我们可以得到k个不同的分类器。针对一个测试样本,我们需要找到这个分类函数输出值最大的那一个,即为测试样本的标记:
a
r
g
m
a
x
c
h
c
(
x
)
,
c
=
1
,
2
,
⋯
 
,
k
arg~max_c h_c(x),c=1,2,\cdots,k
arg maxchc(x),c=1,2,⋯,k
第二种方式
是修改logistic回归的损失函数,让其适应多分类问题。这个损失函数不再笼统地只考虑二分类非1就0的损失,而是具体考虑每个样本标记的损失。这种方法叫做softmax回归,即logistic回归的多分类版本。
参考:Softmax函数与交叉熵
Softmax函数
在Logistic regression二分类问题中,我们可以使用sigmoid函数将输入
W
x
+
b
Wx+b
Wx+b映射到(0,1)区间中,从而得到属于某个类别的概率。将这个问题进行泛化,推广到多分类问题中,我们可以使用softmax函数,对输出的值归一化为概率值。
这里假设在进入softmax函数之前,已经有模型输出C值,其中C是要预测的类别数,模型可以是全连接网络的输出a,其输出个数为C,即输出为
a
1
,
a
2
,
.
.
.
,
a
C
a_1,a_2,...,a_C
a1,a2,...,aC。
所以对每个样本,它属于类别
i
i
i的概率为:
y
i
=
e
a
i
∑
k
=
1
C
e
a
k
∀
i
∈
1...
C
y_i=\frac{e^{a_i}}{∑^C_{k=1}e^{a_k}}~~~~~ ∀_i∈1...C
yi=∑k=1Ceakeai ∀i∈1...C
通过上式可以保证
∑
i
=
1
C
y
i
=
1
∑^C_{i=1} y_i=1
∑i=1Cyi=1,即属于各个类别的概率和为1。
Softmax函数求导
softmax 回归
损失函数:对数似然函数
机器学习里面,对模型的训练都是对Loss function进行优化,在分类问题中,我们一般使用最大似然估计(Maximum likelihood estimation)来构造损失函数。对于输入的
x
x
x,其对应的类标签为
t
t
t,我们的目标是找到这样的
θ
θ
θ使得
p
(
t
∣
x
)
p(t|x)
p(t∣x)最大。在二分类的问题中,我们有:
p
(
t
∣
x
)
=
(
y
)
t
(
1
−
y
)
1
−
t
p(t|x)=(y)^t(1−y)^{1−t}
p(t∣x)=(y)t(1−y)1−t
其中,
y
=
f
(
x
)
y=f(x)
y=f(x)是模型预测的概率值,
t
t
t是样本对应的类标签。
将问题泛化为更一般的情况,多分类问题:
p
(
t
∣
x
)
=
∏
i
=
1
C
P
(
t
i
∣
x
)
t
i
=
∏
i
=
1
C
y
i
t
i
p(t|x)=∏_{i=1}^CP(t_i|x)^{t_i}=∏_{i=1}^Cy^{t_i}_i
p(t∣x)=i=1∏CP(ti∣x)ti=i=1∏Cyiti
其中
t
i
t_i
ti是样本m属于类别i的概率,
y
i
y_i
yi是模型对样本m预测为属于类别i的概率。
由于连乘可能导致最终结果接近0的问题,一般对似然函数取对数的负数,变成最小化对数似然函数。
l
C
E
=
−
l
o
g
p
(
t
∣
x
)
=
−
l
o
g
∏
i
=
1
C
y
i
t
i
=
−
∑
i
=
i
C
t
i
l
o
g
(
y
i
)
l_{CE}=−log~ p(t|x)=−log∏_{i=1}^C y^{t_i}_i=−∑_{i=i}^C t_ilog(y_i)
lCE=−log p(t∣x)=−logi=1∏Cyiti=−i=i∑Ctilog(yi)
损失函数求导
对单个样本来说,loss function
l
C
E
l_{CE}
lCE对输入
a
j
a_j
aj的导数为:
∂
l
C
E
∂
a
j
=
−
∑
i
=
1
C
∂
t
i
l
o
g
(
y
i
)
∂
a
j
=
−
∑
i
=
1
C
t
i
∂
l
o
g
(
y
i
)
∂
a
j
=
−
∑
i
=
1
C
t
i
1
y
i
∂
y
i
∂
a
j
\frac{∂l_{CE}}{∂_{a_j}}=−∑_{i=1}^C \frac{∂t_ilog(y_i)}{∂a_j}=−∑_{i=1}^C t_i\frac{∂log(y_i)}{∂a_j}=−∑_{i=1}^C t_i\frac{1}{y_i}\frac{∂ y_i}{∂a_j}
∂aj∂lCE=−i=1∑C∂aj∂tilog(yi)=−i=1∑Cti∂aj∂log(yi)=−i=1∑Ctiyi1∂aj∂yi
上面对
∂
y
i
∂
a
j
\frac{∂ y_i}{∂a_j}
∂aj∂yi求导结果已经算出:
当
i
=
j
i=j
i=j时:
∂
y
i
∂
a
j
=
y
i
(
1
−
y
j
)
\frac{∂ y_i}{∂a_j}=y_i(1−y_j)
∂aj∂yi=yi(1−yj)
当
i
≠
j
i≠j
i̸=j时:
∂
y
i
∂
a
j
=
−
y
i
y
j
\frac{∂ y_i}{∂a_j}=−y_iy_j
∂aj∂yi=−yiyj
所以,将求导结果代入上式:
−
∑
i
=
1
C
t
i
1
y
i
∂
y
i
∂
a
j
=
−
t
i
y
i
∂
y
i
∂
a
j
−
∑
i
≠
j
C
t
i
y
i
∂
y
i
∂
a
j
=
−
t
j
y
i
y
i
(
1
−
y
j
)
−
∑
i
≠
j
C
t
i
y
i
(
−
y
i
y
j
)
=
−
t
j
+
t
j
y
j
+
∑
i
≠
j
C
t
i
y
j
=
−
t
j
+
∑
i
=
1
C
t
i
y
j
=
−
t
j
+
y
j
∑
i
=
1
C
t
i
=
−
t
j
+
y
j
\begin{matrix} −∑_{i=1}^C t_i\frac{1}{y_i}\frac{∂ y_i}{∂a_j} &=&-\frac{t_i}{y_i}\frac{∂ y_i}{∂a_j}−∑_{i\neq j}^C \frac{t_i}{y_i}\frac{∂ y_i}{∂a_j}\\ &=&-\frac{t_j}{y_i}y_i(1−y_j)−∑_{i\neq j}^C \frac{t_i}{y_i}(−y_iy_j)\\ &=&-t_j+t_jy_j+∑_{i\neq j}^C t_iy_j\\ &=&-t_j+∑_{i=1}^C t_iy_j\\ &=&-t_j+y_j∑_{i=1}^C t_i\\ &=&-t_j+y_j\\ \end{matrix}
−∑i=1Ctiyi1∂aj∂yi======−yiti∂aj∂yi−∑i̸=jCyiti∂aj∂yi−yitjyi(1−yj)−∑i̸=jCyiti(−yiyj)−tj+tjyj+∑i̸=jCtiyj−tj+∑i=1Ctiyj−tj+yj∑i=1Cti−tj+yj
这个就量参数的更新公式,其实与BPNN中的是一样的。
也可参考:Deep Learning 学习随记(三)Softmax regression
逻辑回归用于回归模型
逻辑回归主要用于分类,稍加改造也可以用于回归模型,但只适用于极特殊的分布函数,感觉没什么应用价值。
但可以从下面的角度来应用:
正如在前面在类别判断中计算取1的概率一样
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }}
pi=1+e−(w0+w1xi1+⋯+wpxip)1 ,这个函数是非线性的,越靠近1相互之间越难以区分。如果直接用上式作回归结果,在类似于信用评分这样的场景就不好用。但
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w0+w1xi1+⋯+wpxip却是线性的,个人以为可以利用逻辑回归获得各变量的权重,而
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w0+w1xi1+⋯+wpxip就是相应的综合评分。为了将评分结果约束到一定范围,可以在建模型之前对变量取值进行类似归一化的处理再建模;也可以先建模,再利用
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w0+w1xi1+⋯+wpxip对历史数据预测结果来进行约束,比如除以历史预测结果的最大值,这样就将结果约束到[-1,1]之间,但是我们知道,这样的话可能会出现新的预测结果大于1或小于-1的情况。如果大于1,说明是极好的,不防就令所有大于1的结果为1.这样整个下来就相当于一个线性预测的效果。
逻辑回归模型的检验(及自变量的选择)
逻辑回归方程的显著性检验的目的是检验所有自变量与logitP的线性关系是否显著,是否可以选择线性模型。原假设是假设各回归系数同时为0,自变量全体与logitP的线性关系不显著。如果方程中的诸多自变量对logitP
的线性解释有显著意义,那么必然会使回归方程对样本的拟合得到显著提高。可通过对数似然比测度拟合程度是否有所提高。
我们通常采用似然比检验统计量
−
l
n
(
L
L
x
i
)
2
−ln(\frac{L}{L_{x_i}})^2
−ln(LxiL)2
也可称为似然比卡方,其中
L
L
L表示引入变量
x
i
x_i
xi前回归方程的似然函数值,
L
x
i
L_{x_i}
Lxi表示引入变量
x
i
x_i
xi后回归方程的似然函数值。似然比检验统计量越大表明引入变量
x
i
x_i
xi越有意义。如果似然比卡方观测值的概率
p
p
p值小于给定的显著性水平,不接受原假设,即认为自变量全体与
l
o
g
i
t
P
logitP
logitP之间的线性关系显著。反之,线性关系不显著。
另外可参考:
怎样用SPSS做二项Logistic回归分析?结果如何解释?
Wald检验:
似然比检验
比分检验
spss二分类的logistic回归的操作和分析方法
利用R语言+逻辑回归实现自动化运营
回归系数的显著性检验
逻辑回归系数的显著性检验是检验方程中各变量与 l o g i t P logitP logitP之间是否具有线性关系。原假设是假设变量 x i x_i xi与 l o g i t P logitP logitP之间的线性关系不显著,即 w i = 0 w_i=0 wi=0。
逻辑回归模型的评估方法
来源:2016年07月14日 18:09:35
正确率
TP、FP、FN、TN

- 误检率: fp rate = sum(fp) / (sum(fp) + sum(tn))
- 查准率: precision rate = sum(tp) / (sum(tp) + sum(fp))
- 查全率: recall rate = sum(tp) / (sum(tp) + sum(fn))
- 漏检率:miss rate = sum(fn) / (sum(tp) + sum(fn))
ROC曲线、AUC
ROC曲线的横坐标为false positive rate(FPR),纵坐标为 true positive rate(TPR)
Kappa statics
Kappa值,即内部一致性系数(inter-rater,coefficient of internal consistency),是作为评价判断的一致性程度的重要指标。取值在0~1之间。Kappa≥0.75两者一致性较好;0.75>Kappa≥0.4两者一致性一般;Kappa<0.4两者一致性较差。
第一个图上,所显示的Kappa值有0.9356,那就算很好了。
Mean absolute error 和 Root mean squared error
平均绝对误差和均方根误差,用来衡量分类器预测值和实际结果的差异,越小越好。
Relative absolute error 和 Root relative squared error
相对绝对误差和相对均方根误差,有时绝对误差不能体现误差的真实大小,而相对误差通过体现误差占真值的比重来反映误差大小。
逻辑回归的正则化
当模型的参数过多时,很容易遇到过拟合的问题。而正则化是结构风险最小化的一种实现方式,通过在经验风险上加一个正则化项,来惩罚过大的参数来防止过拟合。
- 正则化是符合奥卡姆剃刀(Occam’s razor)原理 的:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的才是最好的模型。
我们来看一下underfitting,fitting跟overfitting的情况:

显然,最右这张图overfitting了,原因可能是能影响结果的参数太多了。典型的做法在优化目标中加入正则项,通过惩罚过大的参数来防止过拟合:
J
(
w
)
=
>
J
(
w
)
+
λ
∣
∣
w
∣
∣
p
J(w)=>J(w)+λ||w||_p
J(w)=>J(w)+λ∣∣w∣∣p
p=1或者2,表示L1 范数和 L2范数,这两者还是有不同效果的。
L1范数: 是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。那么,参数稀疏 有什么好处呢?
一个关键原因在于它能实现 特征的自动选择。一般来说,大部分特征 x i x_i xi和输出 $y_i $之间并没有多大关系。在最小化目标函数的时候考虑到这些额外的特征 x i x_i xi,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会干扰了对正确 y i y_i yi 的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
L2范数: 它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression)重点内容,有人也叫它“权值衰减”(weight decay)。
它的强大之处就是它能 解决过拟合 问题。我们让 L2 范数的规则项$ ||w||_2$ 最小,可以使得 w 的每个元素都很小,都接近于0,但与 L1范数不同,它不会让它等于0,而是接近于0,这里还是有很大区别的。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。咦,你为啥说越小的参数表示的模型越简单呢? 其实我也不知道,我也是猜,可能是因为参数小,对结果的影响就小了吧。
为了更直观看出两者的区别,我再放一张图:

为了简单,上图只考虑了w为二维(
w
1
w^1
w1,
w
2
w^2
w2)的情况。彩色等高线是(
w
1
w^1
w1,
w
2
w^2
w2);而左边黑色矩形 $||w||_1<C
和
右
边
的
圆
形
和右边的圆形
和右边的圆形 ||w||_2<C $是约束条件;相交的黑点就是最优解发生的地方。两者的区别可以从图中看出来,L1正则化(左图)倾向于使参数变为0,因此能产生稀疏解。而 L2 使 w 接近0;
- 一句话总结就是:L1 会趋向于产生少量的特征,而其他的特征都是0,而 L2 会选择更多的特征,同时很多特征都会接近于0。
并行逻辑回归
来源:
由逻辑回归问题的求解方法中可以看出,无论是梯度下降法、牛顿法、拟牛顿法,计算梯度都是其最基本的步骤,并且L-BFGS通过两步循环计算牛顿方向的方法,避免了计算海森矩阵。因此逻辑回归的并行化最主要的就是对目标函数梯度计算的并行化。从公式(2)中可以看出(就是梯度下降法中梯度的计算公式),目标函数的梯度向量计算中只需要进行向量间的点乘和相加,可以很容易将每个迭代过程拆分成相互独立的计算步骤,由不同的节点进行独立计算,然后归并计算结果。
将M个样本的标签构成一个M维的标签向量,M个N维特征向量构成一个
M
∗
N
M*N
M∗N的样本矩阵,如图3所示。其中特征矩阵每一行为一个特征向量(M行),列为特征维度(N列)。
如果将样本矩阵按行划分,将样本特征向量分布到不同的计算节点,由各计算节点完成自己所负责样本的点乘与求和计算(比如一个节点分到一个样本,那么它负责计算 e 1 、 e 1 x 11 、 … 、 e 1 x 1 p e_1、e_1x_{11}、\dots、e_1x_{1p} e1、e1x11、…、e1x1p;同样第二个节点负责计算 e 2 、 e 2 x 21 、 … 、 e 2 x 2 p e_2、e_2x_{21}、\dots、e_2x_{2p} e2、e2x21、…、e2x2p;依此类推;每二步进行 e 1 + ⋯ + e n ; e 1 x 11 + e 2 x 21 + ⋯ + e n x n 1 ; … e_1+\dots+e_n;e_1x_{11}+e_2x_{21}+\dots+e_nx_{n1};\dots e1+⋯+en;e1x11+e2x21+⋯+enxn1;…),然后将计算结果进行归并,则实现了“按行并行的LR”。按行并行的LR解决了样本数量的问题,但是实际情况中会存在针对高维特征向量进行逻辑回归的场景(如广告系统中的特征维度高达上亿),仅仅按行进行并行处理,无法满足这类场景的需求,因此还需要按列将高维的特征向量拆分成若干小的向量进行求解。
(1) 数据分割
假设所有计算节点排列成m行n列(m*n个计算节点),按行将样本进行划分,每个计算节点分配M/m个样本特征向量和分类标签;按列对特征向量进行切分,每个节点上的特征向量分配N/n维特征。如图4所示,同一样本的特征对应节点的行号相同,不同样本相同维度的特征对应节点的列号相同。
一个样本的特征向量被拆分到同一行不同列的节点中,即: X r , k = < X ( r , 1 ) , k > , … , < X ( r , c ) , k > , … , < X ( r , n ) , k > X_{r,k}=<X_{(r,1),k}>,\dots,<X_{(r,c),k}>,\dots,<X_{(r,n),k}> Xr,k=<X(r,1),k>,…,<X(r,c),k>,…,<X(r,n),k>
其中 X r , k X_{r,k} Xr,k表示第r行的第k个向量, X ( r , c ) , k X_{(r,c),k} X(r,c),k表示 X r , k X_{r,k} Xr,k在第c列节点上的分量。同样的,用 W c W_c Wc表示特征向量W在第c列节点上的分量,即: W = < W 1 , … , W c , … , W n > W=<W_1,\dots,W_c,\dots,W_n> W=<W1,…,Wc,…,Wn>
(2) 并行计算
观察目标函数的梯度计算公式(公式(2)),其依赖于两个计算结果:特征权重向量
W
t
W_t
Wt和特征向量
X
j
X_j
Xj的点乘,标量
[
δ
(
y
i
W
t
T
X
j
)
−
1
]
y
i
[\delta(y_iW_t^TX_j)-1]y_i
[δ(yiWtTXj)−1]yi和特征向量
X
j
X_j
Xj的相乘。可以将目标函数的梯度计算分成两个并行化计算步骤和两个结果归并步骤:
① 各节点并行计算点乘,计算
d
(
r
,
c
)
,
k
,
t
=
W
c
,
t
T
X
(
r
,
c
)
,
k
∈
R
d_{(r,c),k,t}=W_{c,t}^{T}X_{(r,c),k}\in R
d(r,c),k,t=Wc,tTX(r,c),k∈R,其中
k
=
1
,
2
,
…
,
M
/
m
k=1,2,…,M/m
k=1,2,…,M/m,
d
(
r
,
c
)
,
k
,
t
d_{(r,c),k,t}
d(r,c),k,t表示第t次迭代中节点(r,c)上的第k个特征向量与特征权重分量的点乘,
W
c
,
t
W_{c,t}
Wc,t为第t次迭代中特征权重向量在第c列节点上的分量。
② 对行号相同的节点归并点乘结果:
计算得到的点乘结果需要返回到该行所有计算节点中,如图5所示。
④ 对列号相同的节点进行归并:
G
c
,
t
G_{c,t}
Gc,t就是目标函数的梯度向量
G
t
G_t
Gt在第c列节点上的分量,对其进行归并得到目标函数的梯度向量:
这个过程如图6所示。
综合上述步骤,并行LR的计算流程如图7所示。比较图2和图7,并行LR实际上就是在求解损失函数最优解的过程中,针对寻找损失函数下降方向中的梯度方向计算作了并行化处理,而在利用梯度确定下降方向的过程中也可以采用并行化(如L-BFGS中的两步循环法求牛顿方向)。
实验及结果
利用MPI,分别基于梯度下降法(MPI_GD)和L-BFGS(MPI_L-BFGS)实现并行LR,以Liblinear为基准,比较三种方法的训练效率。Liblinear是一个开源库,其中包括了基于TRON的LR(Liblinear的开发者Chih-Jen Lin于1999年创建了TRON方法,并且在论文中展示单机情况下TRON比L-BFGS效率更高)。由于Liblinear并没有实现并行化(事实上是可以加以改造的),实验在单机上进行,MPI_GD和MPI_L-BFGS均采用10个进程。
实验数据是200万条训练样本,特征向量的维度为2000,正负样本的比例为3:7。采用十折交叉法比较MPI_GD、MPI_L-BFGS以及Liblinear的分类效果。结果如图8所示,三者几乎没有区别。
将训练数据由10万逐渐增加到200万,比较三种方法的训练耗时,结果如图9,MPI_GD由于收敛速度慢,尽管采用10个进程,单机上的表现依旧弱于Liblinear,基本上都需要30轮左右的迭代才能达到收敛;MPI_L-BFGS则只需要3~5轮迭代即可收敛(与Liblinear接近),虽然每轮迭代需要额外的开销计算牛顿方向,其收敛速度也要远远快于MPI_GD,另外由于采用多进程并行处理,耗时也远低于Liblinear。
使用spark建立逻辑回归(Logistic)模型帮Helen找男朋友
来源:https://blog.csdn.net/u013719780/article/details/52277616
作者使用得不太好,但可以参考一下,自己做改进。而且spark中逻辑回归实现了多分类算法。
为什么逻辑回归比线性回归要好?
https://blog.csdn.net/cyh_24/article/details/50359055
逻辑回归与最大熵模型MaxEnt的关系?
简单粗暴 的回答是:逻辑回归跟最大熵模型没有本质区别。逻辑回归是最大熵对应类别为二类时的特殊情况,也就是当逻辑回归类别扩展到多类别时,就是最大熵模型。
最大熵模型是约束条件下的熵最大化,可以通过拉格朗日乘子进行推导。可得到最大似然的形式。
而逻辑回归就是最大熵模型k=2的特性。
逻辑回归的python实现
逻辑回归使用心得
逻辑回归应用之Kaggle泰坦尼克之灾
来源:https://blog.csdn.net/han_xiaoyang/article/details/49797143
很详细的一个案例,尤其是最后的逻辑回归系统优化部分有时间要练习一下,自己目前还没有真正花心思去优化已经实现的模型。
其他参考资料:
逻辑回归的前世今生
Logistic Regression 的前世今生(理论篇)
《Logistic Regression 模型简介》,来源:FIN ·2015-05-08 10:00
Python实现逻辑回归(Logistic Regression in Python)














 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









