







在SAS的DATA步中,可以使用by分组,在处理过程中会产生两个临时变量FIRST.variable和LAST.variable,这两个临时变量的值不会写到结果集中。
这两个临时变量的赋值情况如下:
由于DATA step是按行处理每一条观测的,当一条观测为某一组的第一条记录时,那么FIRST.variable就为1,否则为0;每当一条观测为某一组的最后一条记录时,LAST.variable就为1,否则为0; 如果一个组中只有一个观测,那么两者皆为1。
因此,可以使用这两个变量来筛选每一组中的第1条或最后1条观测。
以sashelp.class为例子,原始数据如下:
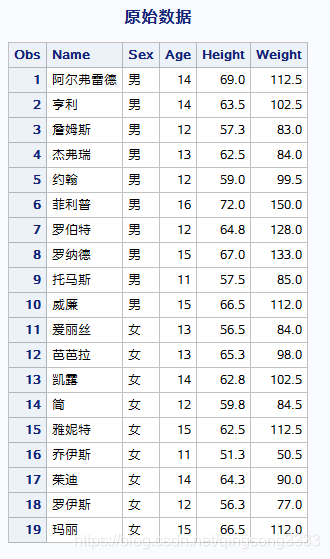
现在如果我们分别输出男生和女生中年龄最大和最小的人的信息怎么办? 可以先按照性别和年龄排序,然后按照姓别分组,只取每一组中的第一条和最后一条观测即可。
第1步是先按照姓别和年龄排序,输出到临时表tmp1中。
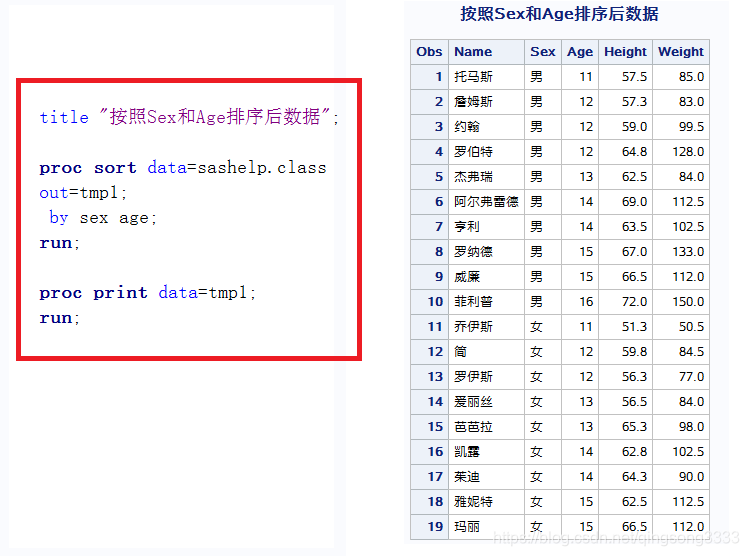
然后将tmp1中的数据按照sex分组,只取每一组的第一条和最后一条数据即可
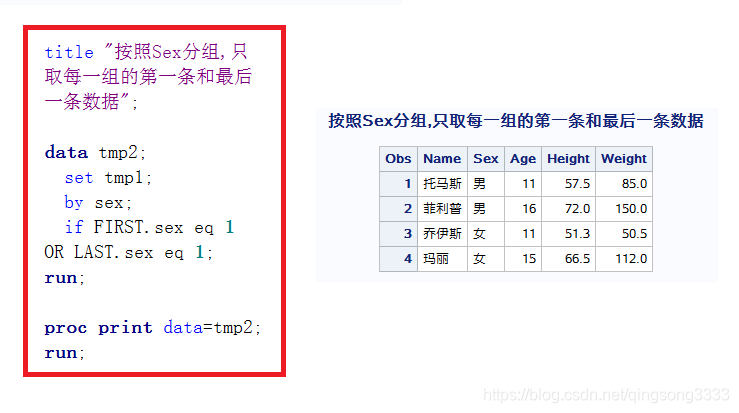
这里的 if FIRST.sex eq 1 OR LAST.sex eq 1就表示如果是一组的第1条观测或者最后1条观测,就继续。
事实上,如果在if前面加上put _all_语句,可以在SAS LOG中看到每个变量的值,包括了FIRST.variable和LAST.variable,如下:
666
667 data tmp2;
668 set tmp1;
669 by sex;
670 put _all_;
671 if FIRST.sex eq 1 OR LAST.sex eq 1;
672 run;
Name=托马斯 Sex=男 Age=11 Height=57.5 Weight=85 FIRST.Sex=1 LAST.Sex=0 _ERROR_=0 _N_=1
Name=詹姆斯 Sex=男 Age=12 Height=57.3 Weight=83 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=2
Name=约翰 Sex=男 Age=12 Height=59 Weight=99.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=3
Name=罗伯特 Sex=男 Age=12 Height=64.8 Weight=128 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=4
Name=杰弗瑞 Sex=男 Age=13 Height=62.5 Weight=84 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=5
Name=阿尔弗雷德 Sex=男 Age=14 Height=69 Weight=112.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=6
Name=亨利 Sex=男 Age=14 Height=63.5 Weight=102.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=7
Name=罗纳德 Sex=男 Age=15 Height=67 Weight=133 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=8
Name=威廉 Sex=男 Age=15 Height=66.5 Weight=112 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=9
Name=菲利普 Sex=男 Age=16 Height=72 Weight=150 FIRST.Sex=0 LAST.Sex=1 _ERROR_=0 _N_=10
Name=乔伊斯 Sex=女 Age=11 Height=51.3 Weight=50.5 FIRST.Sex=1 LAST.Sex=0 _ERROR_=0 _N_=11
Name=简 Sex=女 Age=12 Height=59.8 Weight=84.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=12
Name=罗伊斯 Sex=女 Age=12 Height=56.3 Weight=77 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=13
Name=爱丽丝 Sex=女 Age=13 Height=56.5 Weight=84 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=14
Name=芭芭拉 Sex=女 Age=13 Height=65.3 Weight=98 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=15
Name=凯露 Sex=女 Age=14 Height=62.8 Weight=102.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=16
Name=茱迪 Sex=女 Age=14 Height=64.3 Weight=90 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=17
Name=雅妮特 Sex=女 Age=15 Height=62.5 Weight=112.5 FIRST.Sex=0 LAST.Sex=0 _ERROR_=0 _N_=18
Name=玛丽 Sex=女 Age=15 Height=66.5 Weight=112 FIRST.Sex=0 LAST.Sex=1 _ERROR_=0 _N_=19
NOTE: 从数据集 WORK.TMP1. 读取了 19 个观测
NOTE: 数据集 WORK.TMP2 有 4 个观测和 5 个变量。
NOTE: “DATA 语句”所用时间(总处理时间):
实际时间 0.01 秒
CPU 时间 0.01 秒

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









