







目录
1. 深度学习基础
1.1 本质1——特征自动学习
传统的机器学习方法:
- 良好的特征表达,对最终算法的准确性起了非常关键的作用;
- 识别系统主要的计算和测试工作耗时主要集中在特征提取部分;
- 特征的样式目前一般都是人工设计的,靠人工提取特征。
机器学习中,获得好的特征是识别成功的关键
➢一般而言,特征越多,给出信息就越多,识别准确性会得到提升;
➢但特征多,计算复杂度增加,探索的空间大,可以用来训练的数据在每个特征_上就会稀疏。
目前存在大量人工设计的特征,不同研究对象特征不同,特征具有多样性,如: SIFT, HOG, LBP等,手工选取特征费时费力,需要启发式专业知识,很大程度上靠经验和运气,是否能自动地学习特征?
1.2 本质2——层次网络结构
人脑视觉机理
1981年的诺贝尔医学奖获得者David Hubel和TorstenWiesel发现了视觉系统的信息处理机,发现了一种被称为“方向选择性细胞的神经元细胞,当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃

视觉的层次性
- 人的视觉系统的信息处理是分级的
- 高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图
- 抽象层面越高,存在的可能猜测就越少,就越利于分类

高层特征或图像,往往是由一-些基本结构( 浅层特征)组成的


1.3 本质3——深层网络结构
浅层学习的局限性:有限样本和计算单元情况下对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受限。
深层学习的好处:可通过学习-种深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式表示。

1.4 深度学习 vs. 神经网络
神经网络: 深度学习:


1.5 深度学习的本质
✧本质:通过构建多隐层的模型和海量训练数据( 可为无标签数据),来学习更有用的特征,从而最终提升分类或预测的准确性。“ 深度模型”是手段,“特征学习”是目的。
✧与浅层学习区别:
1 )强调了模型结构的深度,通常有5-10多层的隐层节点;
2)明确突出了特征学习的重要性,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
1.6 深度学习的训练方法
神经网络:采用BP算法调整参数,即采用迭代算法来训练整个网络。随机设定初值,计算当前网络的输出,然后根据当前输出和样本真实标签之间的差去改变前面各层的参数,直到收敛;
深度学习:采用逐层训练机制。采用该机制的原因在于如果采用BP机制,对于一个deep network (7层以上),残差传播到最前面的层将变得很小,出现所谓的gradient diffusion ( 梯度消散)。
不采用BP算法的原因
(1)反馈调整时,梯度越来越稀疏,从顶层越往下,误差校正信号越来越小;
(2)收敛易至局部最小,由于是采用随机值初始化,当初值是远离最优区域时易导致这一情况;
(3) BP算法需要有标签数据来训练,但大部分特征学习是无标签的;
2. 自动编码器
2.1 自动编码器与特征提取
自动编码器就是一种尽可能复现输入信号的神经网络。
■为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分

✧学习过程
■无标签数据,用非监督学习学习特征

在之前的神经网络中,如左图,输入的样本是有标签的,即(input, target),这样根据当前输出和target ( label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
2.2 无监督的特征学习过程
- 将input输入个encoder编码器,就会得到一个code,这个code也就是输入的一个表示
那么我们怎么知道这个code表示的就是input呢?
- 增加一个decoder解码器
decoder输出的信息vs开始的输入信号input
- 通过调整encoder和decoder的参数,使得重构误差最小,这样就得到输入input信号的一个表示了,也就是编码code。
- 因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。

2.3 深度学习的特征学习过程
第一步:采用自下而上的无监督学习一wake-sleep算法:
1) wake阶段:
认知过程,通过下层的输入特征( Input)和向.上的认知( Encoder)权重产生每一层的抽象表示(Code) ,再通过当前的生成(Decoder) 权重产生一个重建信息(Reconstruction) ,计算输入特征和重建信息残差,使用梯度下降修改层间的下行生成(Decoder)权重。也就是“如果现实跟我想象的不一样,改变我的生成权重使得我想象的东西变得与现实-样”
2) sleep阶段:
生成过程,通过.上层概念( Code)和向下的生成(Decoder) 权重,生成下层的状态,再利用认知(Encoder) 权重产生一个抽象景象。利用初始.上层概念和新建抽象景象的残差,利用梯度下降修改层间向.上的认知( Encoder)权重。也就是“如果梦中的景象不是我脑中的相应概念,改变我的认知权重使得这种景象在我看来就是这个概念。
2.4 自动编码机
第二步:自顶向下的监督学习
这一步是在第一步学习获得各层参数进的基础.上,在最顶的编码层添加一一个分类器(例如罗杰斯特回归、SVM等),而后通过带标签数据的监督学习,利用梯度下降法去微调整个网络参数。
深度学习的第一步实质上是一个网络参数初始化过程。区别于传统神经网络初值随机初始化,深度学习模型是通过无监督学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果。

●自动编码机( AutoEncoder )

● 稀疏自动编码机(Sparse AutoEncoder)
为了让输出的维度更低一点,有时需要让其稀疏化


3. 卷积神经网络
3.1 本质
卷积神经网络(CNN) :
卷积+池化+全连接
卷积:
●局部特征提取
●训练中进行参数学习
●每个卷积核提取特定模式的特征
池化(下采样):
●降低数据维度,避免过拟合
●增强局部感受野
●提高平移不变性
全连接:
●特征提取到分类的桥梁
3.2 卷积
RGB三通道二维数组


下图展示了卷积的过程,和信号处理的卷积有所区别,卷积降低了网络模型的复杂度( 对于很难
学习的深层结构来说,这是非常重要的),减少了权值的数量


在上面两个公式中, W2是卷积后Feature Map的宽度; Wi是卷积前图像的宽度; F是filter的宽度; P是Zero Padding数量, Zero Padding是指在原始图像周围补几圈0 ,如果P的值是1 ,那么就补1圈0 ; S是步幅; H2是卷积后Feature Map的高度; H1是卷积前图像的宽度。式2和式3本质上是一样的。
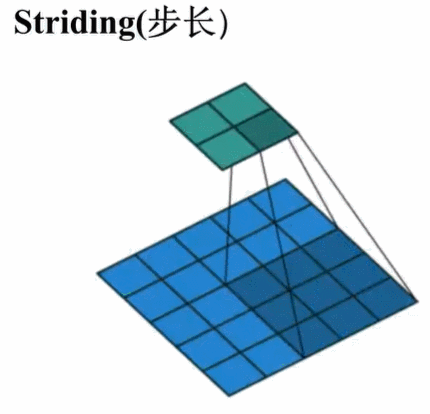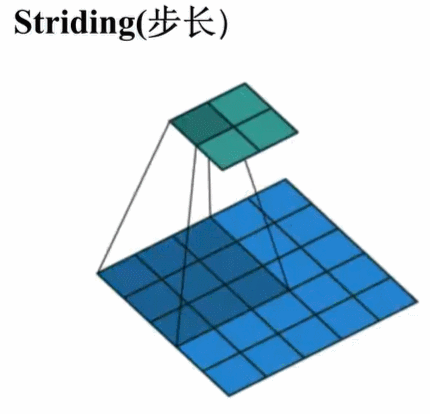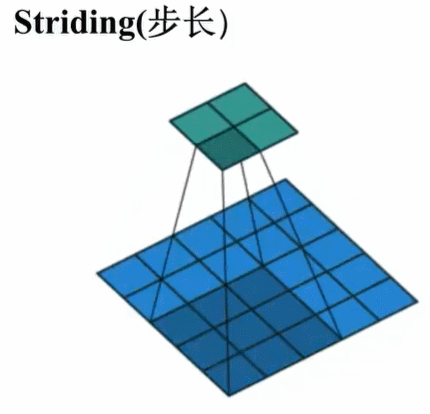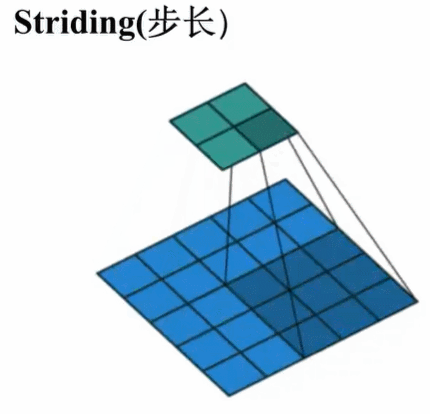

步长即在核的滑动过程中进行“跳步”。步长为1意味着每次滑动跳过一个像素即最前面的标准卷积操作。步长为2意味着每次滑动跳过两个像素,缩小大约2倍,步长为3意味着每次滑动跳过3三个像素,大致缩小3倍,等等。

Padding:用额外的“假”像素(通常值为0,因此称为“零填充”)填充边缘。这样,滑动时的核可以延伸到边缘之外的假像素,允许原始边缘像素位于核中心,从而产生与输入相同大小的输出。
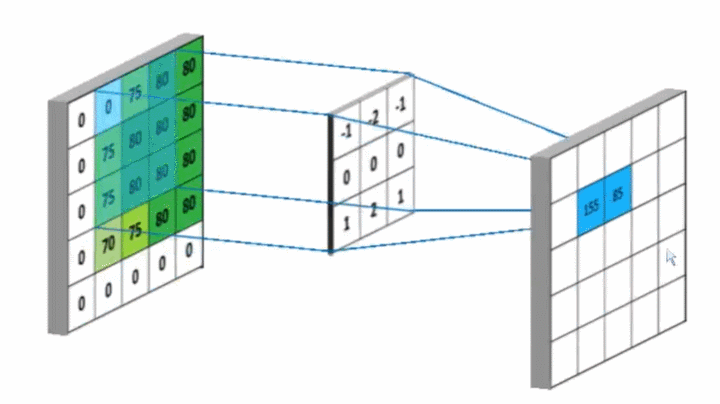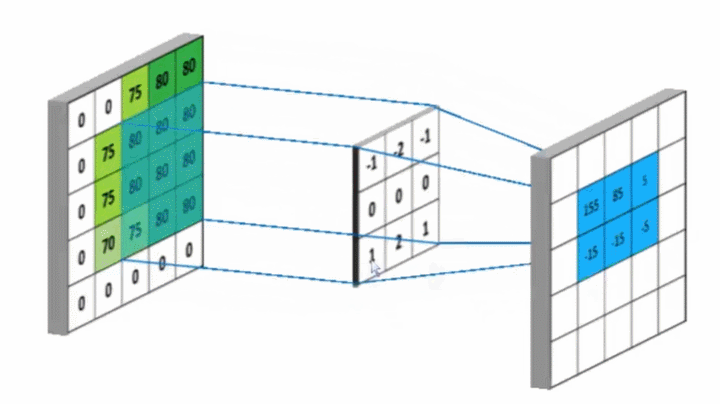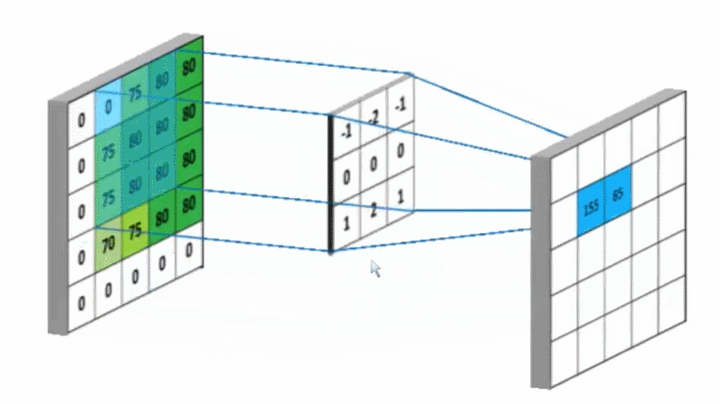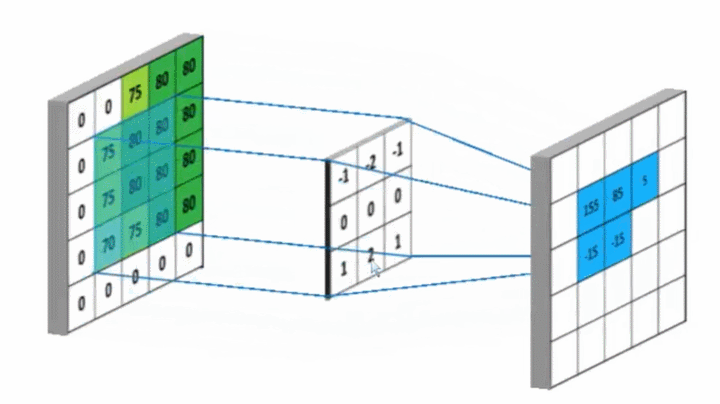

卷积核Kernel也叫滤波器filter, 代表图像的某种特征;也称为神经元。比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。

相似则输出一个明显变大的值,否则输出极小值。
卷积神经网络训练的是什么?卷积核的参数

3.3 池化
什么是池化?
池化层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。
池化的方法很多,最常用的是Max Pooling。Max Pooling实际上就是;在n*n的样本中取最大值,作为采样后的样本值。右图是2*2 max

3.4 卷积神经网络识别图像的过程














 1267
1267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









