






什么是LCA(最近公共祖先)?
最近公共祖先(LCA,Lowest Common Ancestor)是树形数据结构中的一个经典问题。给定一棵树和树中的两个节点,LCA是这两个节点在树中最近的公共祖先。
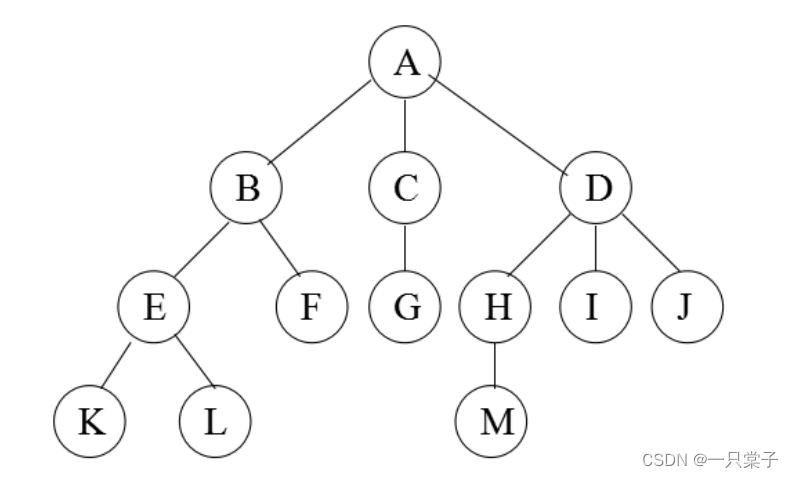
就比如上图中的K和F的最近公共祖先是B,L和C的最近公共祖先是A,M和I的最近公共祖先是D。
LCA的原理
LCA问题可以通过多种方法解决,常见的方法包括:
- Tarjan算法:基于并查集(Union-Find)数据结构,适用于离线查询。
- 倍增法:预处理树结构,然后利用倍增法快速查找LCA。
- 朴素法:通过不断向上追溯节点的父节点直到找到公共祖先。
本文将介绍倍增法实现LCA的具体步骤和代码实现。
倍增法
倍增法是一种高效的预处理和查询LCA的方法,特别适用于处理多个查询的场景。其基本思想是通过预处理树的每个节点的祖先信息,使得在查询时O(nlogn)能够快速找到LCA。
实现步骤和思路
- 树的表示:使用邻接表(Adjacency List)表示树。
- DFS遍历:记录每个节点的深度和父节点信息。
- 预处理:倍增预处理父节点信息。
- 查询LCA:利用倍增预处理的信息快速查询LCA。
1.树的表示和DFS遍历
#import sys
#sys.setrecursionlimit(100000) #设置递归深度,以避免递归深度过深导致的错误
def preprocess_lca(n, adj):
LOG = 0
while (1 << LOG) <= n:
LOG += 1
depth = [0] * n #初始化深度数组
parent = [[-1] * LOG for _ in range(n)] #初始化父节点数组
def dfs(v, p, d):
parent[v][0] = p #设置节点v的父节点为p
depth[v] = d #设置节点v的深度为d
for i in range(1, LOG): #预处理每个节点的2^i祖先节点(倍增法的关键)
if parent[v][i-1] != -1:
parent[v][i] = parent[parent[v][i-1]][i-1]
for u in adj[v]: #遍历所有相邻节点u
if u != p: #如果u不是父节点p
dfs(u, v, d + 1) #递归处理节点u
dfs(0, -1, 0) #从根节点0开始进行DFS遍历
return depth, parent, LOG #返回预处理结果
- 在DFS过程中,为每个节点预处理其祖先节点信息。
- 使用一个二维数组
parent[v][i]来存储节点v的第2^i个祖先节点,其中i从 0 开始,表示2^i次方。 - 如果
parent[v][i-1]已知,那么parent[v][i] = parent[parent[v][i-1]][i-1],这样可以通过对数级别的查找找到任何节点的祖先。
为什么是2^i?
在LCA的倍增法中,使用 2^i 的原因是为了利用二进制的特性来有效地跳跃到节点的更高层级。这种选择主要基于以下几点考虑:
-
效率和简便性:使用 2^i 可以简化跳跃的计算过程。通过使用指数增长的跨度,可以快速地在倍增表中跳到足够高的节点,从而快速逼近目标节点的深度。
-
复杂度分析:在建表阶段,构建 parent的时间复杂度为 O(nlogn)。在查询阶段,找到最近公共祖先的时间复杂度为 O(logn),这主要得益于 2^i 的快速跳跃特性。
2.查询LCA(与其他方法求LCA一样)
def lca(u, v, depth, parent, LOG):
if depth[u] < depth[v]:
u, v = v, u #保证u是较深的节点
diff = depth[u] - depth[v] #深度差
for i in range(LOG): #将u提升到和v相同的深度
if (diff >> i) & 1:
u = parent[u][i]
if u == v:
return u #如果u和v相同,返回u
for i in range(LOG-1, -1, -1): #同时提升u和v直到找到LCA
if parent[u][i] != parent[v][i]:
u = parent[u][i]
v = parent[v][i]
return parent[u][0]
lca函数用于查询节点u和v的最近公共祖先。LOG是树的最大深度的对数值。
完整代码
import sys
sys.setrecursionlimit(100000) # 设置递归深度,以避免递归深度过深导致的错误
def prepare_lca(n, adj):#预处理
LOG = 0
while (1 << LOG) <= n:
LOG += 1
depth = [0] * n # 初始化深度数组
parent = [[-1] * LOG for _ in range(n)] # 初始化父节点数组
def dfs(v, p, d):
parent[v][0] = p # 设置节点v的父节点为p
depth[v] = d # 设置节点v的深度为d
for i in range(1, LOG): # 预处理每个节点的2^i祖先节点
if parent[v][i-1] != -1:
parent[v][i] = parent[parent[v][i-1]][i-1]
for u in adj[v]: # 遍历所有相邻节点u
if u != p: # 如果u不是父节点p
dfs(u, v, d + 1) # 递归处理节点u
dfs(0, -1, 0) # 从根节点0开始进行DFS遍历
return depth, parent, LOG # 返回预处理结果
def lca(u, v, depth, parent, LOG):
if depth[u] < depth[v]:
u, v = v, u # 保证u是较深的节点
diff = depth[u] - depth[v] # 计算深度差
for i in range(LOG): # 将u提升到和v相同的深度
if (diff >> i) & 1:
u = parent[u][i]
if u == v:
return u # 如果u和v相同,返回u
for i in range(LOG-1, -1, -1): # 同时提升u和v直到找到LCA
if parent[u][i] != parent[v][i]:
u = parent[u][i]
v = parent[v][i]
return parent[u][0] # 返回LCA
n = int(input())
adj = [[] for _ in range(n)]
for _ in range(n-1):
u, v = map(int, input().split()) # 读取每条边
adj[u].append(v)
adj[v].append(u)
depth, parent, LOG = prepare_lca(n, adj)
#假设edges = [
# (0, 1),
# (0, 2),
# (1, 3),
# (1, 4),
# (2, 5),
# (2, 6)
#]
print(lca(3, 4, depth, parent, LOG)) # 输出1
print(lca(3, 5, depth, parent, LOG)) # 输出0
print(lca(2, 6, depth, parent, LOG)) # 输出2
















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











