







自监督学习在语音和影像上的应用
语音
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VslSMqUE-1665925378411)(D:\Typora\images\image-20220920205541488.png)]](https://i-blog.csdnimg.cn/blog_migrate/a2b9541a24f11cc0c50ef5ffd46d55be.png)
语音版测试集SUPERB:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8wnsRB0K-1665925378414)(D:\Typora\images\image-20220920205701404.png)]](https://i-blog.csdnimg.cn/blog_migrate/c8faa284be191a83c5fa9e7364ddd50f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i2wfsFoW-1665925378415)(D:\Typora\images\image-20220920210045604.png)]](https://i-blog.csdnimg.cn/blog_migrate/8c2b25fa72f01484b4e50f4ff4cab812.png)
影像
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2jpkKhU7-1665925378415)(D:\Typora\images\image-20220920211026461.png)]](https://i-blog.csdnimg.cn/blog_migrate/2771baaea11fe2d6d662abbab3b0eebf.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cCGgftj3-1665925378416)(D:\Typora\images\image-20220920211512917.png)]](https://i-blog.csdnimg.cn/blog_migrate/46ea8c671a86d4d99381488c35f971a8.png)
横轴是各类模型,纵轴是各模型的效能。
怎么训练语音版、影像版的BERT?
-
Generative Approaches(BERT series、GPT series)
语音上:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hJbpCqPn-1665925378417)(D:\Typora\images\image-20220920213901683.png)]](https://i-blog.csdnimg.cn/blog_migrate/97c4d89c807b9069a9c807b49d696715.png)
BERT与文字处理的差别:
①对语音mask时,不要mask一个连续的向量,因为相邻的语音向量含义相近,当只mask掉一个连续的向量时,通过两侧向量做差往往易得到mask掉的向量。所以需要mask时,mask掉多个连续向量。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BuzVY8lP-1665925378418)(D:\Typora\images\image-20220920214518243.png)]](https://i-blog.csdnimg.cn/blog_migrate/a8ebcebd287ba261e2b883490be33ad3.png)
②对语音向量做mask时,可以不在时间的维度上mask,而是在向量的维数上进行mask。有利于学到更多语者的信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xHUo6MGM-1665925378418)(D:\Typora\images\image-20220920214917328.png)]](https://i-blog.csdnimg.cn/blog_migrate/ca7249420acfdd59a9fd535150b836db.png)
GPT系列:GPT在文本中是用来预测下一个文字token,在语音中亦可预测下一个语音向量,从上面可知相邻语音有相近性,易于预测,这太简单了使模型学不到有用的东西,因此我们往往会预测一段连续的语音。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zJZ7EXfk-1665925378419)(D:\Typora\images\image-20220920222033591.png)]](https://i-blog.csdnimg.cn/blog_migrate/e544e7516f212e4127fba44cb728ef99.png)
影像上:

综上,存在的问题:相较于文字,语音和影像包含了大量的细节,所以让模型将一段语音或一段影像完整的还原出来是非常困难的,相较于文字是用token来表示的,语音和影像里包含了更多的资讯,处理起来非常困难。
-
Predictive Approach
例①:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-01hWwakB-1665925378421)(D:\Typora\images\image-20220920224546682.png)]](https://i-blog.csdnimg.cn/blog_migrate/a441938f58897fe18843f6df2bb2a736.png)
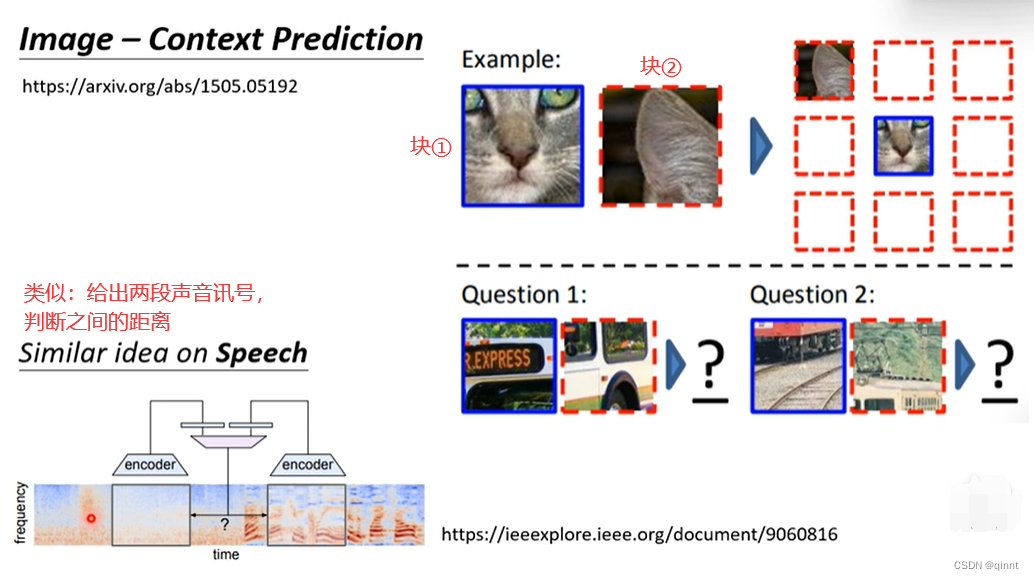
例②:将一张大的图片切成若干块,让机器预测块②在块①的哪个方向。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BOFhBWqG-1665925378422)(D:\Typora\images\image-20220920225926140.png)]](https://i-blog.csdnimg.cn/blog_migrate/3a6e1432c510f20cc7243b2aa7ebe988.png)
-
Contrastive Learning
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9kxA9Irb-1665925378423)(D:\Typora\images\image-20220921104623422.png)]](https://i-blog.csdnimg.cn/blog_migrate/d3ae456c95a353b6702f6cbbc0d27956.png)
通过数据增强,将图片进行切块、变色处理,因为他们属于同一张图片,二者向量会很接近。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U13VmtPO-1665925378424)(D:\Typora\images\image-20220921105832798.png)]](https://i-blog.csdnimg.cn/blog_migrate/92abe1e36d20d284f498aa780811052e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JJKIe1ii-1665925378425)(D:\Typora\images\image-20220921111209714.png)]](https://i-blog.csdnimg.cn/blog_migrate/2883816cd91bb54250d4650f0a6b249f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tn3VPUaF-1665925378426)(D:\Typora\images\image-20220921112129410.png)]](https://i-blog.csdnimg.cn/blog_migrate/740b762d2df7e9b46c27ab0094ec50e9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rzWBp7PT-1665925378427)(D:\Typora\images\image-20220921112202984.png)]](https://i-blog.csdnimg.cn/blog_migrate/884634dd02ecb32481c09bc158b36060.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s5vAPEDV-1665925378428)(D:\Typora\images\image-20220921112336371.png)]](https://i-blog.csdnimg.cn/blog_migrate/860b381b2a50e575cbce8360572ad9c1.png)
太神奇了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFri9qQh-1665925378430)(D:\Typora\images\image-20220921112805175.png)]](https://i-blog.csdnimg.cn/blog_migrate/89bed9c31b85f8125f482034ab5c6b6e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5JJIAkYA-1665925378430)(D:\Typora\images\image-20220921113141629.png)]](https://i-blog.csdnimg.cn/blog_migrate/49175c097391d8dfe3942db6442f8b5b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RqsGK8ox-1665925378431)(D:\Typora\images\image-20220921115733973.png)]](https://i-blog.csdnimg.cn/blog_migrate/1d0019002aae7cc90ffb1e5c51b69811.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w96twy6i-1665925378432)(D:\Typora\images\image-20220921120147721.png)]](https://i-blog.csdnimg.cn/blog_migrate/eaa882b30263b910c1efc95bb6304c09.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B5XeGHxU-1665925378433)(D:\Typora\images\image-20220921120953061.png)]](https://i-blog.csdnimg.cn/blog_migrate/78e5b171eeb75566b56655db83f27ae4.png)
有点迷糊了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aj7NuFxz-1665925378433)(D:\Typora\images\image-20220921121700211.png)]](https://i-blog.csdnimg.cn/blog_migrate/3161fab6efd9e94178f7478c04f55c3b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wv7Xxv2w-1665925378433)(D:\Typora\images\image-20220921122307029.png)]](https://i-blog.csdnimg.cn/blog_migrate/c557d5e9b7362dab6561395a07cf8b96.png)
选取一组合适的负例是非常困难的,不能选的太简单的,也不能选太难的,所以这个方法的执行也存在一定的难度,以下两种方法可避开选择Negative Examples这件事。
- Bootstrapping Approaches
只用positive训练,会导致不论什么图片都会输出和原图相近的向量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A0VIizKJ-1665925378434)(D:\Typora\images\image-20220921125846285.png)]](https://i-blog.csdnimg.cn/blog_migrate/3ebaf8a69136e987b53d65ebc881aef1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AiUxdIEs-1665925378434)(D:\Typora\images\image-20220921130711418.png)]](https://i-blog.csdnimg.cn/blog_migrate/11dac541b8865c91683d5dbbae15c5ff.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-meOnQqYb-1665925378435)(D:\Typora\images\image-20220921131521362.png)]](https://i-blog.csdnimg.cn/blog_migrate/514b66a2b431aed2063caf733ba8ff3a.png)
-
Simply Extra Regularization
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mYalr0Mg-1665925378435)(D:\Typora\images\image-20220921133151564.png)]](https://i-blog.csdnimg.cn/blog_migrate/9fba899212b6985d847f50ddcc8e3bd1.png)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











