







Python 可以说是最容易入门的编程语言,在numpy,scipy等基础包的帮助下,对于数据的处理和机器学习来说Python可以说是目前最好的语言,在各位大佬和热心贡献者的帮助下Python拥有一个庞大的社区支持技术发展,开发两个各种 Python 包来帮助数据人员的工作。
1、Knockknock
Knockknock是一个简单的Python包,它会在机器学习模型训练结束或崩溃时通知您。我们可以通过多种渠道获得通知,如电子邮件、Slack、Microsoft Teams等。
为了安装该包,我们使用以下代码。
pip install knockknock
例如,我们可以使用以下代码将机器学习建模训练状态通知到指定的电子邮件地址。
from knockknock import email_sender
from sklearn.linear_model import LinearRegression
import numpy as np
@email_sender(recipient_emails=["<your_email@address.com>", "<your_second_email@address.com>"], sender_email="<sender_email@gmail.com>")
def train_linear_model(your_nicest_parameters):
x = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(x, np.array([1, 2])) + 3
regression = LinearRegression().fit(x, y)
return regression.score(x, y)
这样就可以在该函数出现问题或者完成时获得通知。
2、tqdm
当需要进行迭代或循环时,如果你需要显示进度条?那么tqdm就是你需要的。这个包将在你的笔记本或命令提示符中提供一个简单的进度计。
让我们从安装包开始。
pip install tqdm
然后可以使用以下代码来显示循环过程中的进度条。
from tqdm import tqdm
q = 0
for i in tqdm(range(10000000)):
q = i +1
就像上面的gifg,它可以在notebook上显示一个很好的进度条。当有一个复杂的迭代并且想要跟踪进度时,它会非常有用。
3、Pandas-log
Panda -log可以对Panda的基本操作提供反馈,如.query、.drop、.merge等。它基于R的Tidyverse,可以使用它了解所有数据分析步骤。
安装包
pip install pandas-log
安装包之后,看看下面的示例。
import pandas as pd
import numpy as np
import pandas_log
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})
然后让我们尝试用下面的代码做一个简单的 pandas 操作记录。
with pandas_log.enable():
res = (df.drop("born", axis = 1)
.groupby('name')
)
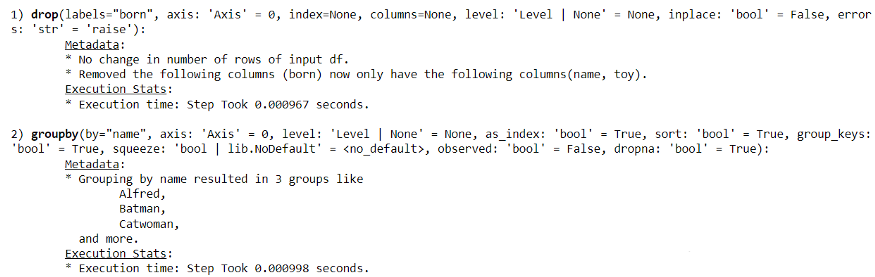
通过 pandas-log,我们可以获取所有的执行信息。
4、Emoji
顾名思义,Emoji 是一个支持 emoji 文本解析的 Python 包。通常,我们很难用 Python 处理表情符号,但 Emoji 包可以帮助我们进行转换。
使用以下代码安装 Emoji 包。
pip install emoji
看看下面代码:
import emoji
print(emoji.emojize('Python is :thumbs_up:'))
Python is 👍
有了这个包,可以轻易的输出表情符号。
5、TheFuzz
TheFuzz 使用 Levenshtein 距离来匹配文本以计算相似度。
pip install thefuzz
下面代码介绍如何使用 TheFuzz 进行相似性文本匹配。
from thefuzz import fuzz, process
#Testing the score between two sentences
fuzz.ratio("Test the word", "test the Word!")
81
TheFuzz 还可以同时从多个单词中提取相似度分数。
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
process.extract("new york jets", choices, limit=2)
[('new york jets', 100),
('new york Giants', 79)]
TheFuzz 适用于任何文本数据相似性检测,这个工作在nlp中非常重要。
6、Numerizer
Numerizer 可将写入的数字文本转换为对应的整数或浮点数。
pip install numerizer
然后 让我们尝试几个输入来进行转换。
from numerizer import numerize
numerize('forty two')
'42'
如果使用另一种书写风格,它也可以工作的。
numerize('forty-two')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









