






下面是学习了莫烦大佬 sklearn 教程的笔记,是供我自己查阅的,不是很详细,介意的勿看~ 莫烦大佬的教程链接在最后一点学习资料里面。
一、下载与安装
使用命令:pip install -U scikit-learn 或者 conda install scikit-learn
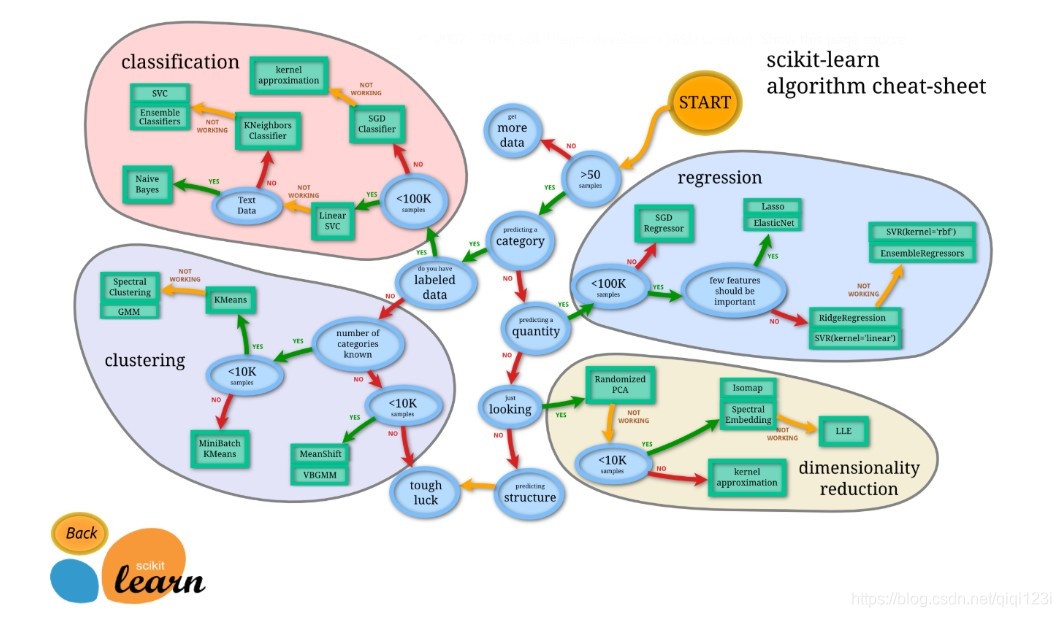
二、选择合适的机器学习方法
三、通用的学习模式
得到数据集,划分数据集,对训练集进行训练,对测试集进行预测;
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris() #加载数据集
iris_X = iris.data #得到数据集的数据部分
iris_y = iris.target #得到数据集的标签部分
print("数据集前2行:\n",iris_X[:2]) #打印前两行数据
print("标签前2行:\n",iris_y[:2]) #打印前两行数据
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3,random_state=2020) #划分数据集和标签为训练集和测试集,测试集比例为0.3,random_state表示固定划分结果
knn = KNeighborsClassifier() #KNN分类器
knn.fit(X_train,y_train) #进行训练
print("预测结果:\n",knn.predict(X_test)) #得到预测结果
print("实际结果:\n",y_test)
得到结果:

四、sklearn 的 datasets 数据库
使用 datasets 里面的函数都会返回一个字典一样的对象,里面至少包括两项:
- 第一项:key = data,value = 形状为n_samples * n_features 的数据集
- 第二项:key = target,value = 长度为n_samples的numpy数组,包含目标值
使用 datasets 库可以:
1、引入已有的数据集,包括玩具数据集、大的真实数据集
scikit-learn 内置有一些小型标准数据集(7 个),不需要从某个外部网址下载任何文件,比如常用的鸢尾花数据集 load_iris()、波士顿房价数据集 load_boston(),都是以 load 开头的函数。scikit-learn 提供加载较⼤数据集的⼯具,并在必要时下载这些数据集,这些函数都以fetch开头的函数。
from sklearn import datasets
loaded_data = datasets.load_boston()
data_X = loaded_data.data #如上解释,第一项得到数据集
data_y = loaded_data.target #如上解释,第二项得到目标值
print(data_X.shape) #(506,13)
2、利用 dataset 库自己创建数据集,可以按照自己的想法,去随机生成想要的数据集,比如可以用于回归的数据集,可以用于分类的数据集,可以用于聚类的数据集。
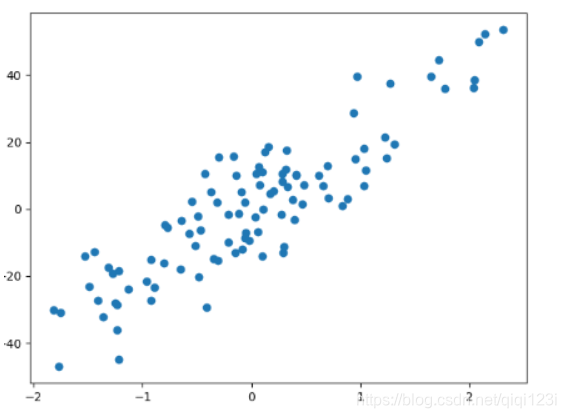
X,y = datasets.make_regression(n_samples=100,n_features=1,
n_targets=1,noise=10,random_state=2020) #n_samples表示样本数量,n_features表示特征数量,n_targets表示目标的数量,noise表示噪音大小
plt.scatter(X,y)#X和y
plt.show()
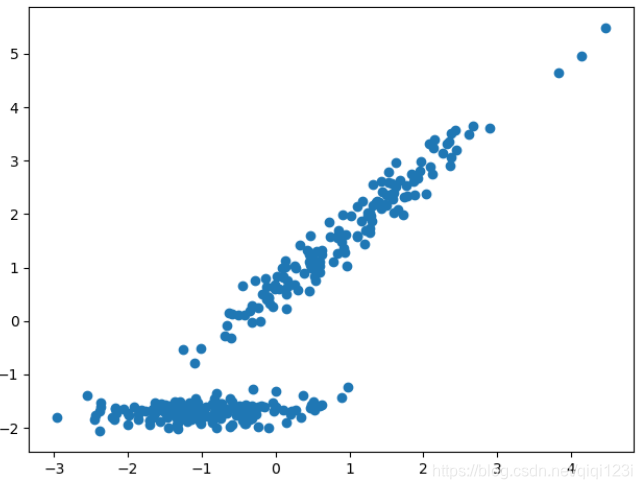
X,y = datasets.make_classification(n_samples=300,n_features=5,n_redundant=3,
n_informative=2,random_state=2020,n_classes =2,n_clusters_per_class = 1)#n_samples表示300行,n_features表示每行有2个特征列,n_redundant表示冗余的特征列数,n_informative表示有信息的特征列表(表示有用),并且n_redundant + n_informative < n_features。
# random_state固定随机种子,n_classes表示分为几类,n_clusters_per_class表示每个类有几个簇群,其中n_classes * n_clusters_per_class 需<=2**n_features
plt.scatter(X[:,0],X[:,1],marker='o')
plt.show()
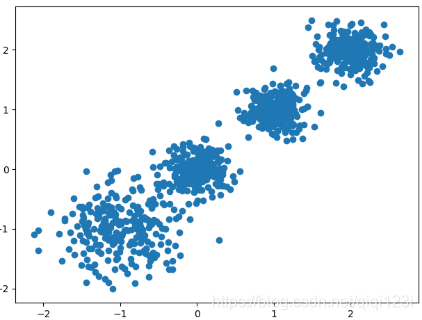
X, y = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
当然,还可以加载外部的数据集,scikit-learn可以接受任何转化为 numpy 数组的数据,如 pandas 的DataFrame。
五、常用属性和功能
from sklearn import datasets
from sklearn.linear_model import LinearRegression
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X,data_y)
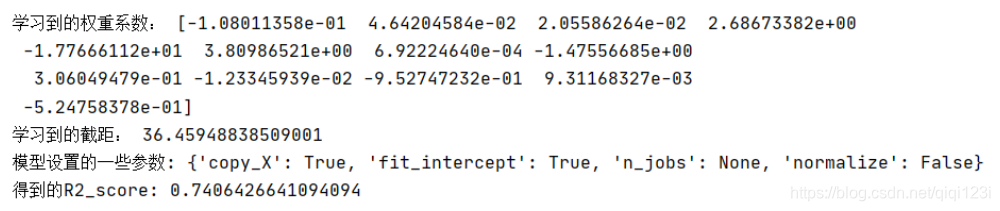
print("学习到的权重系数:",model.coef_)
print("学习到的截距:",model.intercept_)
print("模型设置的一些参数:",model.get_params())
print("得到的R2_score:",model.score(data_X,data_y))#这个函数首先会利用data_X进行预测data_y,然后与实际的data_y,计算R2_soore
六、预处理数据
sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。
- 一般来说,机器学习算法受益于数据集的标准化,标准化(归一化)可以让梯度下降更快。
- 如果数据集中存在一定离群值,那么稳定的缩放或转换更合适。
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
iris = datasets.load_iris() #加载数据集
iris_X = iris.data #得到数据集的数据部分
iris_y = iris.target #得到数据集的标签部分
X_train, X_test, y_train, y_test = train_test_split(iris_X,iris_y,test_size=0.3,random_state=2025)
X_train_Standard = StandardScaler().fit_transform(X_train)#标准化
X_test_Standard = StandardScaler().fit_transform(X_test)
X_train_MinMaxScaler = MinMaxScaler().fit_transform(X_train)#归一化
X_test_MinMaxScaler = MinMaxScaler().fit_transform(X_test)
注意:在真实使用时,不要将整个数据集进行标准化或者归一化,最好将训练集和测试集分开进行。
七、交叉验证
想要看调整不同参数最后的效果。
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
k_range = range(1,31) #调参看结果
k_score = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
# loss = -cross_val_score(knn,X,y,cv=10,scoring='neg_mean_squared_error') #for regression
scores = cross_val_score(knn,X,y,cv=10,scoring='accuracy') #for classification,scoring指的是使用的评价指标
k_score.append(scores.mean())
plt.plot(k_range,k_score)
plt.xlabel('Value of k with KNN')
plt.ylabel('Cross Validated Accuracy')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WowGT1Ez-1593707554541)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\1593706214527.png)]](https://img-blog.csdnimg.cn/20200703003453449.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FpcWkxMjNp,size_16,color_FFFFFF,t_70)
想要看训练集和测试集的预测效果
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
digits = load_digits()
X = digits.data
y = digits.target
train_sizes,train_loss,test_loss = learning_curve(
SVC(gamma=0.001),X,y,cv=10,scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1])
train_loss_mean = -np.mean(train_loss,axis=1)
test_loss_mean = -np.mean(test_loss,axis=1)
plt.plot(train_sizes,train_loss_mean,'o-',c='r',label="Training")
plt.plot(train_sizes,test_loss_mean,'o-',c='g',label="Cross-Validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t9PyPBuN-1593707554546)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\1593706453478.png)]](https://img-blog.csdnimg.cn/20200703003512369.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FpcWkxMjNp,size_16,color_FFFFFF,t_70)
通过validation_curve选择模型中的参数
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.model_selection import validation_curve
digits = load_digits()
X = digits.data
y = digits.target
param_range = np.logspace(-6,-2.3,5)
train_loss,test_loss = validation_curve(SVC(),X,y,param_name='gamma',param_range=param_range,cv=10,scoring='neg_mean_squared_error')
train_loss_mean = -np.mean(train_loss,axis=1)
test_loss_mean = -np.mean(test_loss,axis=1)
plt.plot(param_range,train_loss_mean,'o-',c='r',label="Training")
plt.plot(param_range,test_loss_mean,'o-',c='g',label="Cross-Validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TYjGv2Z4-1593707554548)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\1593706586471.png)]](https://img-blog.csdnimg.cn/20200703003531322.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FpcWkxMjNp,size_16,color_FFFFFF,t_70)
八、保存模型
from sklearn import svm
import pickle
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X,y = iris.data,iris.target
clf.fit(X,y)
with open('save/clf.pickle','wb') as f:#保存模型
pickle.dump(clf,f)














 2252
2252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









