







目录
一. 本章使用的函数说明
reshape( x )
1.当原始数组A[4,6]为二维数组,代表4行6列。 A.reshape(-1,8):表示将数组转换成8列的数组,具体多少行我们不知道,所以参数设为-1。用我们的数学可以计算出是3行8列
2.当原始数组A[4,6]为二维数组,代表4行6列。 A.reshape(3,-1):表示将数组转换成3行的数组,具体多少列我们不知道,所以参数设为-1。用我们的数学可以计算出是3行8列
make_regression (n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
用于生成随机样本
n_samples:样本数
n_features:特征数(自变量个数)
n_informative:参与建模特征数
n_targets:因变量个数
noise:噪音
bias:偏差(截距)
coef:是否输出coef标识
random_state:随机状态若为固定值则每次产生的数据都一样
train_test_split( train_data , train_target , test_size=0.4 , random_state=0 , stratify=y_train )
用于将数据分割成样本集和测试集
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(... test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类。
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify。
将stratify=X就是按照X中的比例分配
将stratify=y就是按照y中的比例分配
LinearRegression().fit( x,y )
用线性模型LinearRegression来拟合fit(输入,输出)。同理,将模型名称变成别的模型也是拟合
LinearRegression().fit().predict()
LinearRegression().fit().coef_
计算线性的直线系数w(模型的斜率k)。一个NumPy数组,数据中有几个特征值就对应几个数。.coef_[i] 表示数组中的第i个特征系数
LinearRegression().fit().intercept_
计算线性的截距b。一个浮点数
二. 四种线性模型
1.最最基本线性模型
原理:直线会位于距离所有点距离最小的位置
利用生成的数字
#添加插件部分
import numpy as np
import matplotlib.pyplot as plt
#数据部分
x = np.linspace(-5,5,100) #在-5到5之间生成100个等差数字
y = 0.5*x+3
#画图部分
plt.plot(x,y,c='green')
plt.show()
再用给定两点的predict拟合
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression # 线性回归模型
#数据输入,x用[]括起来表示只有一个输入
x = [[1],[2]]
y = [5,3]
#创建一个线性模型LinearRegression,用这个线性模型拟合x,y fit(x,y)
lr = LinearRegression().fit(x,y)
#定制图表的x上下界,和跨度(形成网格)
z = np.linspace(0,5,20)
#画图
plt.scatter(x,y,s=80)
plt.plot(z,lr.predict(z.reshape(-1,1)),c = 'k') #
plt.show()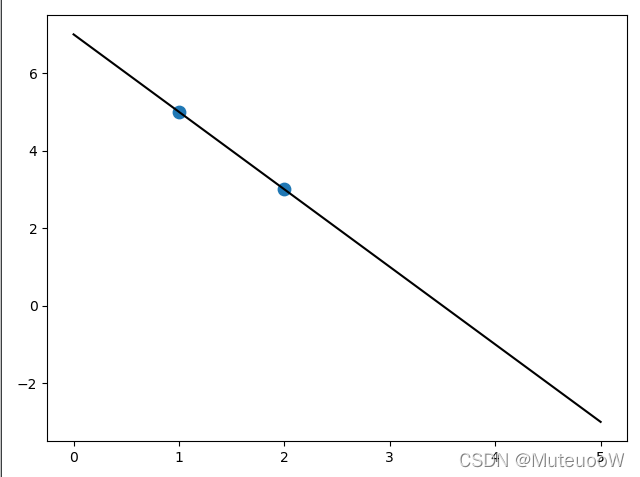
【注】在新版skelearn函数里,所有数据都应该是二维矩阵,哪怕它只是单独一行或一列,需要使用.reshape(1,-1)进行转换
求取该直线的一些信息
确定通过上述两点的直线方程:
print('y = {:.3f}'.format(lr.coef_[0]),'x','+{:.3f}'.format(lr.intercept_)) 求K和截距
print('直线的系数(k)值:{:.2f}'.format(lr.coef_[0]))
print('直线的截距:{:.2f}'.format(lr.intercept_))【注】.nf代表显示小数点后n位
2.线性回归模型
普通最小二乘法模型(OLS)
原理:找到训练集中y的预测值和其真实值的平方差最小的时候,所对应的w和b
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X,y = make_regression(n_samples = 100,n_features = 2,n_informative = 2,random_state = 39)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
lr = LinearRegression().fit(X_train,y_train)
print(lr.coef_)
print(lr.score(X_test,y_test))真实数据集再测试,导入糖尿病数据集:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_diabetes #导入糖尿病数据集
X,y = load_diabetes().data,load_diabetes().target #这里也不一样
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
lr = LinearRegression().fit(X_train,y_train)
print(lr.coef_)
print(lr.score(X_test,y_test))当出现训练数据集和测试数据集得分相差很多,或测试数据得分超过训练数据时,考虑出现了过拟合现象,应采用岭回归
3.岭回归
一种改良的最小二乘法,线性回归的进阶版,L2正则法在线性模型中的应用
L2正则法:保留全部变量,通过降低特征变量的系数来避免过拟合的方法
岭回归原理:保留所有的特征变量。但是会减小特征变量的系数值。使得特征变量对结果的影响变小。岭回归中是通过改变alpha参数来控制减小特征变量系数的程度。岭回归是一个在[模型的简单性]和[训练集上的性能]取得平衡的一个模型,通过alpha参数可以调节二者间的倾向。alpha参数默认为1。alpha参数越高,特征变量系数越低,在训练集上的性能越低,泛化程度越高,过拟合程度越低。alpha参数越接近于0(例如0.1),会导致模型越趋近于线性回归。
特殊作用:可以避免过拟合。如果我们希望模型的泛化能力更好,那么应该考虑岭回归模型,而非线性回归
泛化:
函数调用:
from sklearn.linear_model import Ridge用岭回归重新测试同一个糖尿病数据集:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.datasets import load_diabetes #导入糖尿病数据集
X,y = load_diabetes().data,load_diabetes().target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
lr = Ridge().fit(X_train,y_train) #换成岭回归函数
print(lr.coef_)
print(lr.score(X_test,y_test))这次相差的就很小了
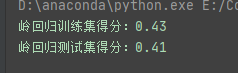
调节alpha参数(影响训练集和测试集得分)
#alpha参数设为5
lr = Ridge(alpha=5).fit(X_train,y_train)当数据量小于50时,线性回归几乎没有用;如果数据量足够多(>300),岭回归与线性回归的学习效果相差无几
4.套索回归
应用L1正则化进行回归的模型
套索回归原理:在使用套索回归的时候,会将某些特征参数等于0,彻底被模型忽略,从而凸显出模型中的重要特征。可以视为模型自主选择的结果。
用法:通过调节alpha参数和最大迭代次数max_iter参数,来提高纳入考虑的特征值数量,以及模型得分。其中,alpha参数默认为1,越接近0,模型越复杂,得分越高;但是如果alpha太小,太接近0,则会回到线性回归,出现过拟合现象。并非复杂程度越高,模型质量越好
函数调用:
from sklearn.linear_model import Lasso再使用套索回归一下糖尿病模型
import numpy as np #引入个np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso #导入Lasso套索回归
from sklearn.datasets import load_diabetes #导入糖尿病数据集
X,y = load_diabetes().data,load_diabetes().target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
lr = Lasso().fit(X_train,y_train) #应用Lasso
print("套索回归训练集得分:{:.2f}".format(lr.score(X_train,y_train)))
print("套索回归测试集得分:{:.2f}".format(lr.score(X_test,y_test)))
#用于检测套索回归使用了几个特征值
print("套索回归使用的特征数:{}".format(np.sum(lr.coef_ != 0)))拟合结果不理想,10个特征值只用了2个,说明发生欠拟合。
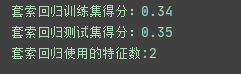
降低alpha的值,并且增加最大迭代次数,来降低欠拟合程度:
lr = Lasso(alpha=0.1 , max_iter=100000 ).fit(X_train,y_train)发现特征数变多了,并且得分明显提高,nice。

但是注意此处出现了过拟合现象
三. 模型的选择
岭回归(L2正则化)的应用场景:
1. 数据的特征向量不多,而且每一个都比较重要
2. 往往是优选
套索回归(L1正则化)的应用场景:
1.有很多种特征,并且有一些特征很不必要
2. 需要对模型进行解释(更少的特征会方便解释,容易理解)

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









