import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
import skfuzzy as fuzz
import skfuzzy.control as ctrl
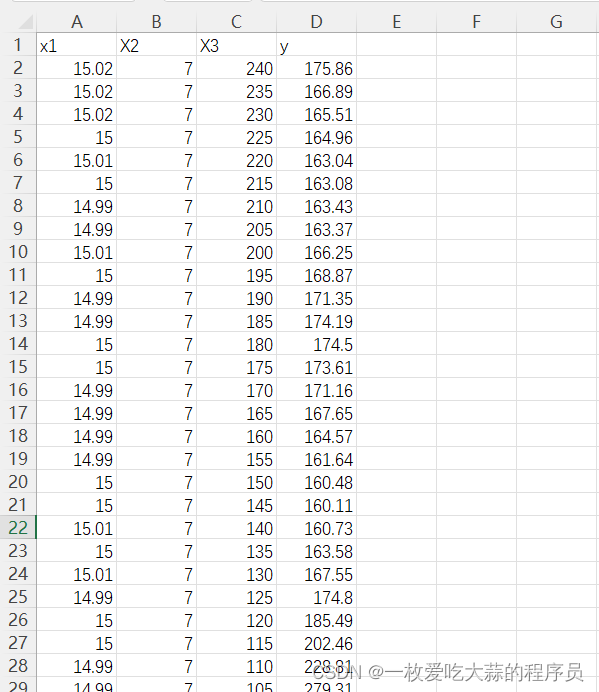
data = pd.read_excel("ReBCO01.xlsx")
print(data.columns) # ['x1', 'X2', 'X3', 'y']
df = data.fillna(0)
# Split the data into features and target
X = df[['x1', 'X2', 'X3']].values[1000:]
y = df['y'].values[1000:]
# 标准化数据
scaler_X = MinMaxScaler()
scale








 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











