







ZooKeeper是一个高可用、高性能的分布式协调服务,可用于命名服务、配置管理、分布式同步等实现。并且现在越来越多的分布式应用开始依赖ZooKeeper,如HBase、Storm等。可以把ZooKeeper看做类似文件系统的目录树,和文件系统不同的是没有目录和文件的概念,而是由一个一个节点组成的树,每个节点都称为Znode,可以包含一些数据,还可以包含一些子节点。
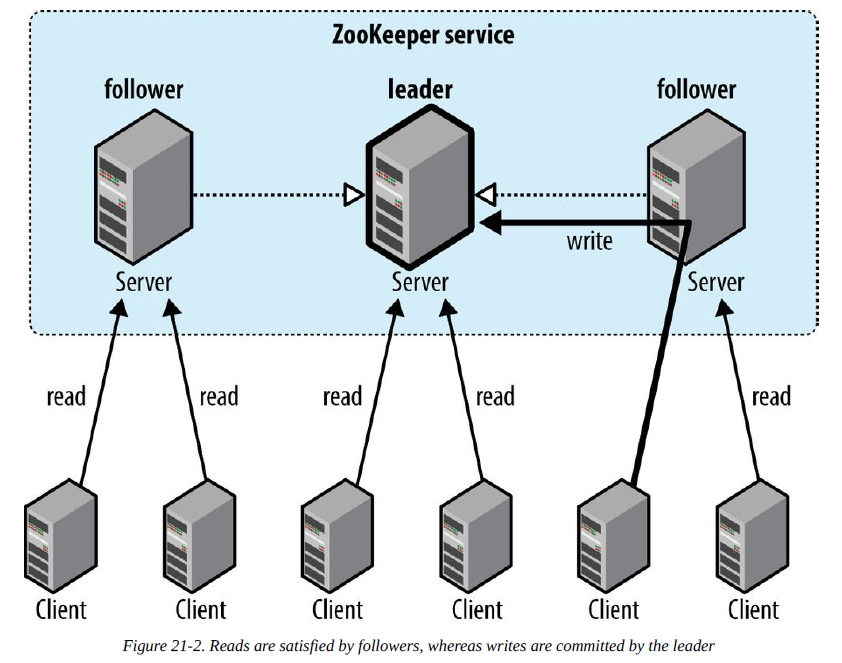
说它高可用是指它leader/follower模式,如果leader失败了,就会通过选举从follower中选出一个leader,来接替老leader的职责,选举leader的过程是比较快的,不会出现明显的中断情况;当老leader恢复后,就作为follower加入集群中。
高性能:ZooKeeper是一个高吞吐量的系统,为提高系统的读取性能,要求所有的读操作都从内存中读取,而不是从磁盘上的文件中读取。换句话说,ZooKeeper的每个server内存中都保存了全量的数据,通常ZooKeeper的数据量是比较小的。
主要使用场景:
命名服务:类似于Java的JNDI,可以集中管理一些共享信息。
配置管理:对于较大的集群,修改某个配置项,就会造成与其它机器的配置不一致,如果要一个一个的去修改,是一个重复、耗时的工作,通过ZooKeeper就可以在一处修改,其它的服务器就会自动修改,达到一致状态。
分布式同步:也称为分布式锁,能够防止同时多台机器修改同一台机器的某个文件。详见:http://blog.csdn.net/qiruiduni/article/details/50475056
实现
ZooKeeper有两种运行模式,一种是单机模式(standalone mode),这种模式一般适用于测试和单元调试。另一种是复制模式(replicated mode),这种模式可以通过复制实现集群的高可用,并且只要集群中的大多数(超过一半)znode节点在运行,仍然可以提供服务。通常集群的节点数为奇数。
概念上,ZooKeeper实现非常简单,就是只要对znode树的任何操作都必须要被复制到集群中大多数的节点上。如果大多数节点都失败了,只要有一个节点仍在提供服务,则其它剩余的副本最终将和这个节点达到一致的状态。
ZooKeeper的实现的关键是它的原子广播(atomic broadcast)特性,这个特性是ZooKeeper各个server之间的一致性的保证。它分为两个阶段:
- 选举leader阶段(leader election)
集群中的节点都要经过一个选举的过程,选出一个杰出的节点作为leader,则其他节点作为followers.(随从者),一旦选出leader后,其它的follower都要和leader保持一致的状态。 - 原子广播(atomic broadcast)
所有的写请求都要发送给leader,然后由leader将update广播(broadcast)给follower,当所有的follower对update持久化了,那么leader将提交update,并返回给客户端一个成功修改的响应。这个过程是原子性,所以一个更改操作要么成功要么失败。
在将update操作写到磁盘之前,需要先更新内存中的znode 树。Read请求可以被任何节点(leader、followers)接收,并且是从内存中查找的,速度会很快。
一致性
经过若干更新后,可能存在follower的状态可能滞后于leader的状态,造成两者的状态的不一致。理想的情况是所有客户端的请求都连接到leader,但是连接并不是有客户端控制的,如下图:
为保证事务顺序一致性,ZooKeeper为每一个update操作加了一个全局的唯一标识:zxid(可以把它理解为一个事务ID)。update操作是有序的,如果zxid z1小于z2,那么z1将在z2之前发生。
ZooKeeper提供了以下措施来保证数据的一致性:
- 顺序一致性(Sequentail consistency)
来自任何客户端的update都是按他们发送的顺序来执行的。 - 原子性(atomicity)
update操作要么成功要么失败。 - 单一系统镜像(Single system image)
无论客户端连接到哪一个server,都会看到同样的系统视图。就是说,在同一个会话中,客户端连接到一个新的server,它不会看到比上一个server的老的系统状态。 - 持久性(Durability)
如果一个update成功了,那么它将会被持久化并且不能够被撤销。 - 及时性(Timeliness)
客户端不会看到陈旧的数据。
当客户端和server端建立连接后,Server端会为客户端创建一个session,该session具有超时时间,如果超时,将不能被再次打开,并且与之相关的临时znode将会丢失。由客户端发送ping请求给server端来保持session存活状态的(也可称作“心跳”),发送ping请求的过程不需要用户维护,是由ZooKeeper的客户端库自动发送的。超时时间应设置的小些,这样能够较早的检测出server端失败了和重新连接到其它的server端。
切换到其它的server,是由客户端自动完成的,并且当前的session仍然是可用的。
时间(Time)
ZooKeeper中有几种类型的time参数:
- tick time:用于server之间的交互间隔时间
- session timeout:客户端和server的session超时时间,通常是tick time的2倍到20倍之间。即如果tick time设置为2秒,那么session timeout时间应为4秒到40秒之间。
在设置session timeout时需要注意的是,对于网络比较繁忙,设置的超时时间太小,可能会造成数据包的丢失或延迟,引起session的关闭。而对于由应用创建的一些复杂的临时对象的情况,就应该设置的大些,因为重建这些对象需要较高的代价。
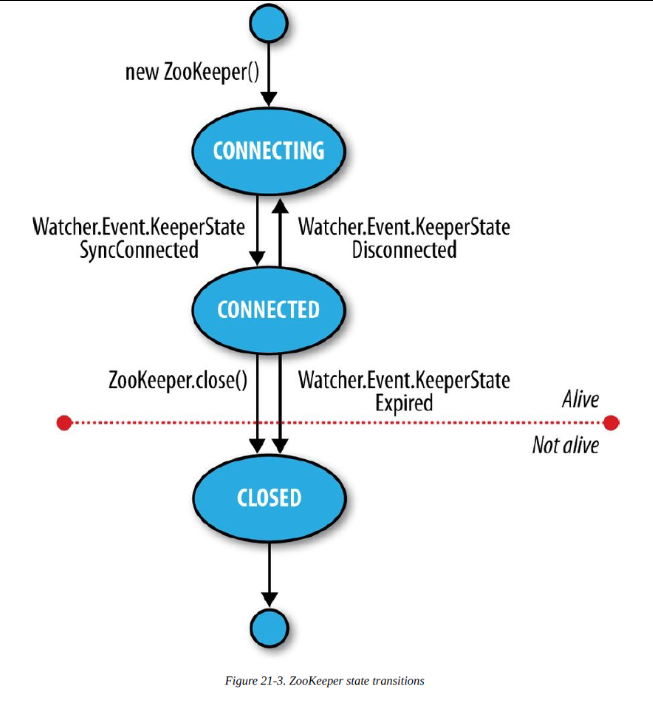
一个ZooKeeper实例,在其生命周期内会有不同的状态变化,如下图:
一个客户端使用ZooKeeper对象可以通过注册一个Watcher对象来监听并接受ZooKeeper对象状态变化的信息。
ZooKeeper的Watcher对象有两种职责:一种是监控ZooKeeper对象的状态变化,另一种是监控znode节点的状态变化。默认,Watcher对象在创建ZooKeeper实例时指定的,对于Znode的可以使用专用的Watcher来监控其状态变化,也可以使用默认的Watcher。















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









