







k-近邻算法(机器学习理论+python实战)
前言
- 对于其他分类算法:决策树归纳、贝叶斯分类、基于规则的分类、BP-神经网络分类、支持向量机、基于关联规则挖掘的分类,这些都是给定训练集,然后训练得到模型,再去预测新元组(测试集)。
- 而k-近邻分类不同,它先将训练元组存储,直到给定一个预测元组,它才基于类比学习,即通过给定预测元组与存储的训练元组的相似性,对该元组进行分类。(因此该算法也称为惰性学习法)
1. k-近邻算法
k-近邻算法(k-Nearest Neighbour algorithm),又称KNN算法,是数据挖掘技术中原理最简单的算法,可用于分类。
算法思想:
给定一个已知类标签的训练数据集,输入没有标签的新数据后,在训练集中找到与新数据最邻近的k个实例(比较两两元组的特征),如果k个实例的多数属于某个类别,则该新数据也属于该类别。
可简单理解为:由那些离元组x最近的k个点来投票决定x的类别。

我们知道k-近邻算法工作原理,根据元组特征比较,然后取样本集中特征最相似的数据(最近邻)的分类标签。那如何进行比较呢??
"近邻性"用距离进行度量,如欧几里得距离:
两个点或元组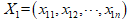 和
和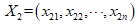 的欧式距离为:
的欧式距离为: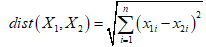
- 在度量距离之前,先对每个属性的值进行规范化。防止具有较大初始值域的属性在最终结果上权重过大造成影响。数据归一化使得每个属性的权重相同。
- 数据归一化处理方法有多种:0-1标准化,Z-score标准化,Sigmoid压缩法等等。0-1标准化把属性A的值v变换到[0,1]区间的v1,公式如下:
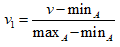
k-近邻算法的优缺点:
优点:精度高、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和离散型
关于k-近邻的几个问题:
2. 以上距离度量中讨论的是属性是数值型的。对于离散型属性应该如何度量距离?
答:一种简单的方法是比较元组X1和X2中对应属性的值。如果属性值相同则为0,不同则为1。该方法类似于皮尔逊相关系数的计算。
3. 如何确定k的值?
答:通过迭代实验来确定。从k=1开始,用测试数据集估计分类器的错误率。重复该过程k++,最后选取产生最小错误率的k值。
4. 对于噪声数据和不相关属性的影响?
答:k-近邻分类法是基于距离比较的,本质上赋予每个属性相等的权重。因此,当数据存在噪声和不相关属性时,分类器的准确率受到很大影响。可通过属性加权法和噪声数据元组的减枝来处理。
5. 对于计算量大,效率低的问题?
答:k-近邻分类法对预测元组分类时可能非常慢。如果训练集有D个元组,而k=1,对于一个给定的测试元组分类,需要|D|次比较,时间复杂度为O(|D|)。
解决方案:
(1.)通过预先排序并将排序后的元组安排在搜索树中,比较次数可以降低到O(log|D|)。
(2.)并行实现,可以把运行时间降低为常数,O(1)。
(3.)部分距离计算法: 基于n个属性的子集计算距离,如果该距离超过阈值,则停止给定存储元组的进一步计算。
(4.)编辑存储法: 可以删除被证明“无用的”元组。该方法也称为减枝或精简,因为它减少了存储元组的数量。
案例,用k-近邻算法分类一个电影是爱情片还是动作片

python实现
#导入包
import pandas as pd
#构建数据集
rowdata={'电影名称':['无问西东','后来的我们','前任3','红海行动','唐人街探案','战狼2'],
'打斗镜头':[1,5,12,108,112,115],
'接吻镜头':[101,89,97,5,9,8],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片']}
movie_data= pd.DataFrame(rowdata)
#添加待分类数据
new_data = [24,67]
#计算已知类别数据集中的点与当前点之间的距离
dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
#将距离升序排列,然后选取距离最小的k个点
k=4
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
dr = dist_l.sort_values(by = 'dist')[: k]
#确定前k个点所在类别的出现频率
re = dr.loc[:,'labels'].value_counts()
re.index[0]
#返回结果
result = []
result.append(re.index[0])
result
封装该函数
import pandas as pd
"""
函数功能:KNN分类器
参数说明:
inX:需要预测分类的数据集
dataSet:已知分类标签的数据集(训练集)
k:k-近邻算法参数,选择距离最小的k个点
返回:
result:分类结果
"""
def classify0(inX,dataSet,k):
dist = list((((movie_data.iloc[:6,1:3]-new_data)**2).sum(1))**0.5)
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:,'labels'].value_counts()
result.append(re.index[0])
return result
测试
inX = new_data
dataSet = movie_data
k= 4
classify0(inX,dataSet,k)
结果
['爱情片']
约会网站的判定
#1.导入数据集
datingTest = pd.read_table('datingTestSet.txt',header=None)
datingTest.head()
# 2. 分析数据
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
#把不同标签用颜色区分
Colors = []
for i in range(datingTest.shape[0]):
m = datingTest.iloc[i,-1]
if m=='didntLike':
Colors.append('black')
if m=='smallDoses':
Colors.append('orange')
if m=='largeDoses':
Colors.append('red')
#绘制两两特征之间的散点图
plt.rcParams['font.sans-serif']=['Simhei'] #图中字体设置为黑体
pl=plt.figure(figsize=(12,8))
fig1=pl.add_subplot(221)
plt.scatter(datingTest.iloc[:,1],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('玩游戏视频所占时间比')
plt.ylabel('每周消费冰淇淋公升数')
fig2=pl.add_subplot(222)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,1],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('玩游戏视频所占时间比')
fig3=pl.add_subplot(223)
plt.scatter(datingTest.iloc[:,0],datingTest.iloc[:,2],marker='.',c=Colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('每周消费冰淇淋公升数')
plt.show()

#数据归一化
def minmax(dataSet):
minDf = dataSet.min()
maxDf = dataSet.max()
normSet = (dataSet - minDf )/(maxDf - minDf)
return normSet
datingT = pd.concat([minmax(datingTest.iloc[:, :3]), datingTest.iloc[:,3]], axis=1)
datingT.head()
#划分数据集
def randSplit(dataSet,rate=0.9):
n = dataSet.shape[0]
m = int(n*rate)
train = dataSet.iloc[:m,:]
test = dataSet.iloc[m:,:]
test.index = range(test.shape[0])
return train,test
train,test = randSplit(datingT)
#定义分类器
def datingClass(train,test,k):
n = train.shape[1] - 1
m = test.shape[0]
result = []
for i in range(m):
dist = list((((train.iloc[:, :n] - test.iloc[i, :n]) ** 2).sum(1))**5)
dist_l = pd.DataFrame({'dist': dist, 'labels': (train.iloc[:, n])})
dr = dist_l.sort_values(by = 'dist')[: k]
re = dr.loc[:, 'labels'].value_counts()
result.append(re.index[0])
result = pd.Series(result)
test['predict'] = result
acc = (test.iloc[:,-1]==test.iloc[:,-2]).mean()
print(f'模型预测准确率为{acc}')
return test
datingClass(train,test,5)
输出结果
模型预测准确率为0.95
源码下载地址:
参考书目:《机器学习实战》王斌译——图灵程序设计丛书
学习网址:菊安酱的《机器学习实战》:有12期的免费课程。















 7073
7073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









