







关注微信公众号:百万年薪运维工程师成长手札
【问题现象】
生产环境有一台服务器server在通过yum安装软件的过程中发生异常,操作系统似乎停止响应超过了30秒,系统内部署的秒级iostat监控的数据有30多秒没有写入磁盘,应用层面也有较多超时报错。
回头通过/var/log/messages进行日志查看,发现在执行yum install的命令时,日志中有如下记录。
Jul 11 23:10:59 server systemd: Reloading.
Jul 11 23:11:04 server systemd: Reloading.
Jul 11 23:11:09 server systemd: Reloading.
Jul 11 23:11:12 server kernel: sched: RT throttling activated
Jul 11 23:11:14 server systemd: Reloading.
Jul 11 23:11:19 server systemd: Reloading.
Jul 11 23:11:24 server systemd: Reloading.
Jul 11 23:11:29 server systemd: Reloading.
Jul 11 23:11:34 server systemd: Reloading.【问题分析】
yum install 会进行软件包安装,在一个软件包安装完以后,会通过daemon-reload对systemd服务进行配置刷新。接着在/var/log/messages中会出现对应的记录Reloading。生产环境的服务器不能乱动,幸运的是我们在测试环境找到了类似的服务器,发现部分节点上存在相同的问题。
还原系统表象,当进行daemon-reload时,vmstat数据显示CPU的sys调用使用率超过50%,对应的CPU队列中的等待进程数量达到2位数。
#vmstat 1

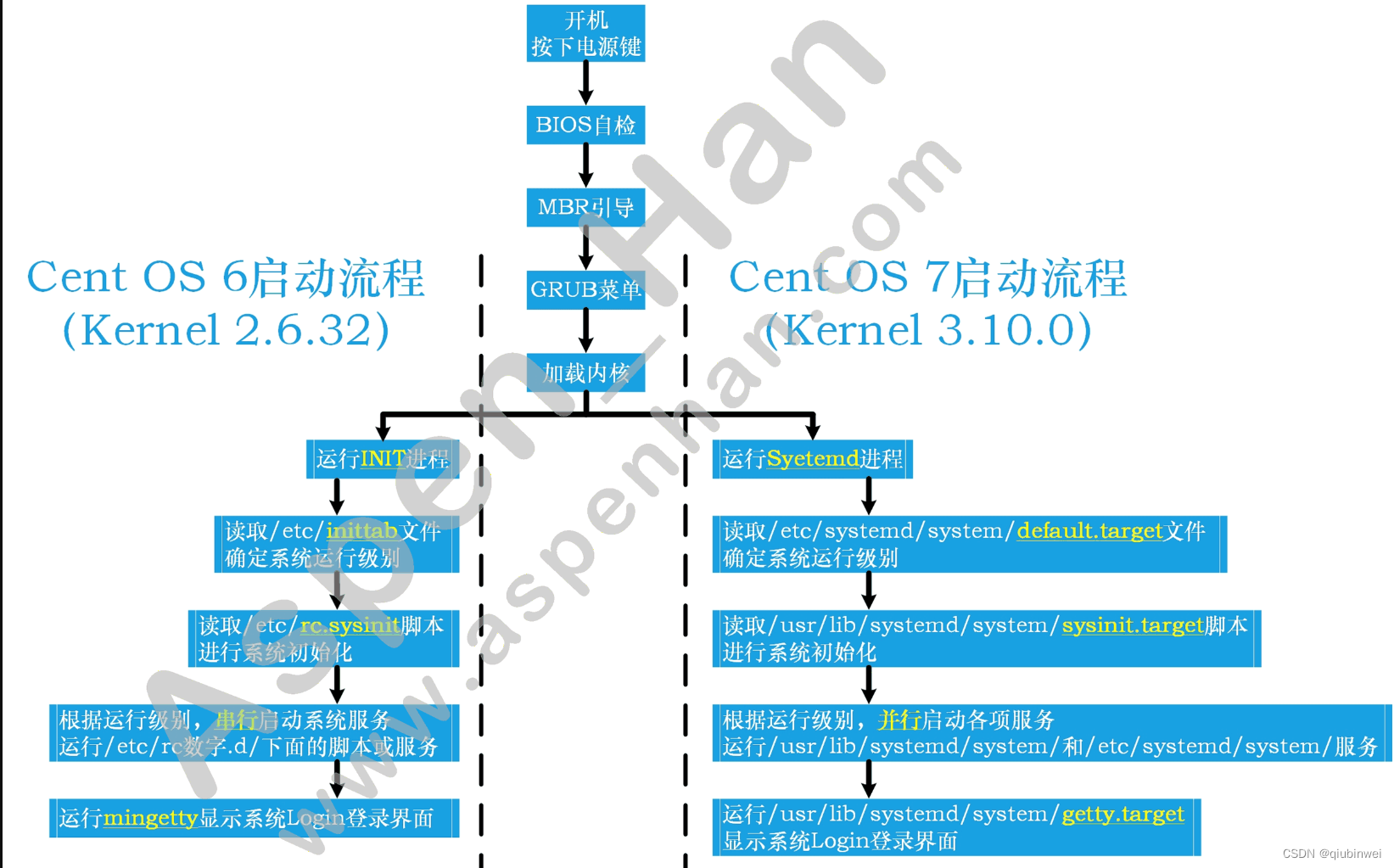
从这类表象分析,一般都是系统调用导致的问题。于是进一步需要对systemctl daemon-reload进行strace追踪,实际上就是要对Linux的systemd,也就是1号进程进行追踪。之前的笔记中提到过,Linux内核初始化函数start_kernel()在完成初始化所需要的数据结构之后,会创建另外一个内核线程,叫做1号进程或者init进程,pid为1。于是乎我去查了一下资料,1号进程在centos7以前的确叫init进程,但是在centos7以后,就叫systemd了。如下图(如有侵权,请通知删除),关于init与systemd的纠葛,可以参考[架构之路-31]:目标系统 - 系统软件 - Linux OS 什么是Linux 1号进程? init进程与systemD的比较?_linux1号进程_文火冰糖的硅基工坊的博客-CSDN博客
回到systemd进程,通过strace -c的方式对比不执行和执行systemctl daemon-reload的过程中去统计systemd的系统调用情况
首先是在不执行的情况下,抓取10秒,可以看到systemd进程当前系统调用响应比较快速,耗时最长的是epool_wait调用,单次耗时0.8ms。
#strace -f -c -p 1 抓取10秒以后ctrl+c 退出

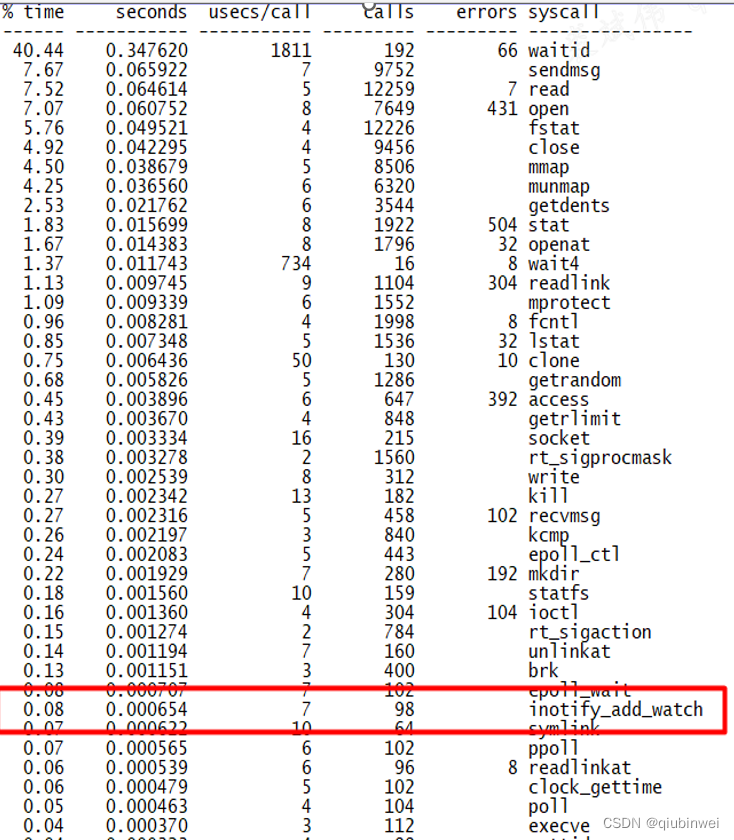
接着再去抓取10秒执行systemctl daemon-reload的系统调用数据,很明显可以看到,systemd有超过1秒多的时间消耗在了inotify_add_watch的系统调用上。
#strace -f -c -p 1 抓取10秒以后ctrl+c 退出

为了做进一步的对比验证,我们再找了另外一台服务器去执行同样命令并抓取systemd进程的系统调用,发现inotify_add_watch调用的耗时非常短
#strace -f -c -p 1 抓取10秒以后ctrl+c 退出
因此我们有理由推测daemon-reaload的卡顿是由于inotify_add_watch的函数调用耗时较长引起的。
接着后续我们在通过perf命令对操作系统全局以及systemd进程进行了抓取。
首先是针对系统全局。发现系统卡在native_queued_spin_lock_slowpath上,也就是说有自旋锁了,但是从全局上来看,暂时不清楚具体为什么
#perf top -g

结合代码进一步分析inotify_add_watch的耗时究竟在哪里
通过stace继续追踪systemd的inotify_add_watch函数,发现主要在访问根目录“/”,单次耗时比较长。有异常的inotify_add_watch如下:
#strace -T -f -tt -e trace=all -p 1 -o try.txt
#cat try.txt | grep -i inotif_add_watch | grep -v run

对比正常的inotify_add_watch耗时,如下:
#strace -T -f -tt -e trace=all -p 1 -o try.txt
#cat try.txt | grep -i inotif_add_watch | grep -v run

转而去perf systemd进程,接着根据perf得到的数据生成CPU火焰图。
#perf record -F 99 -p 1 -g -- sleep 30
//pid表示需要采样的进程id,如果是Java进程可以使用jps等命令获取进程id,perf record表示记录,-F 99表示每秒99次,-g表示记录调用栈,sleep 30则是持续30秒
使用perf script工具对perf.data进行解析
#perf script -i perf.data &> perf.unfold
需要用到一个国外大神bredangregg自己写的性能分析工具火焰图,项目地址:https://github.com/brendangregg/FlameGraph
#./stackcollapse-perf.pl perf.unfold > perf.folded //生成折叠后的调用栈
#./flamegraph.pl perf.folded > out.svg //生成火焰图
从火焰图上可以清晰地看出,CPU的主要耗时集中在__fsnotify_update_child_dentry_flags函数上。在最热点的函数里的调用链为inotify_add_watch->fsnotify_add_mark_locked->fsnotify-recalc_mast->__fsnotify_update_child_dentry_flags。 最终指向了函数__fsnotify_update_child_dentry_flags

追溯该函数的代码,可以看到它有一个自旋锁的机制。
/*
* Given an inode, first check if we care what happens to our children. Inotify
* and dnotify both tell their parents about events. If we care about any event
* on a child we run all of our children and set a dentry flag saying that the
* parent cares. Thus when an event happens on a child it can quickly tell if
* if there is a need to find a parent and send the event to the parent.
*/
void __fsnotify_update_child_dentry_flags(struct inode *inode)
{
struct dentry *alias;
int watched;
if (!S_ISDIR(inode->i_mode))
return;
/* determine if the children should tell inode about their events */
watched = fsnotify_inode_watches_children(inode);
spin_lock(&inode->i_lock);
/* run all of the dentries associated with this inode. Since this is a
* directory, there damn well better only be one item on this list */
hlist_for_each_entry(alias, &inode->i_dentry, d_u.d_alias) {
struct dentry *child;
/* run all of the children of the original inode and fix their
* d_flags to indicate parental interest (their parent is the
* original inode) */
spin_lock(&alias->d_lock);
list_for_each_entry(child, &alias->d_subdirs, d_child) {
if (!child->d_inode)
continue;
spin_lock_nested(&child->d_lock, DENTRY_D_LOCK_NESTED);
if (watched)
child->d_flags |= DCACHE_FSNOTIFY_PARENT_WATCHED;
else
child->d_flags &= ~DCACHE_FSNOTIFY_PARENT_WATCHED;
spin_unlock(&child->d_lock);
}
spin_unlock(&alias->d_lock);
}
spin_unlock(&inode->i_lock);
}通过源码分析这个函数的作用是遍历给定inode文件的所有子目录和子文件的dentry,并根据情况设置DCACHE_FSNOTIFY_PARENT_WATCHED标志。它拿了inode锁,这就把根目录锁住了。一旦有人执行stat调用就会等待根目录的inode锁,因为stat调用会追溯路径至根。如果有很多进程调用stat,load就跑高了。
但正常情况下,根目录下就那么几个文件,怎么会跑的这么久呢?这个函数跑的时间长,有这么几个地方可能出问题:
1、hlist_for_each_entry遍历的链表过长,说明给定inode对应许多dentry。
2、list_for_each_entry遍历的链表过长,说明根目录有大量子dentry。
3、spin_lock_nested拿不到锁导致等待。
此时作为一个运维狗,发挥百度大法。把__fsnotify_update_child_dentry_flags作为关键字进行搜索,马上一篇知乎的范文就跃然呈现。
systemctl daemon-reload和根目录下的大量negative dentry共同作用导致机器偶发负载突高 - 知乎 大神几乎把我们碰到的所有问题都讲明白了,剩下的就是一遍思考一遍抄作业了。
结合大神写的C代码的查询工具(使用child_cnt统计hlist_for_each_entry遍历的链表长度,使用subdirs统计所有子文件的数量,并在每个子文件的自旋锁解锁后打印时间戳,以排除锁问题。)。可以看到在根目录下里面有459万条数据。可是实际用ls -a去看,才几十个目录,剩下的459万个是怎么来的呢?

__fsnotify_update_child_dentry_flags函数中的这条语句
if (!child->d_inode) continue;
它是用来过滤negative dentry的。如果一个dentry没有对应的inode,那它就是negative的。说明root下有大量的negative dentry,CPU时间主要被耗费在遍历子dentry上了。
从大神的脚本上,也能看出产生的异常条目的文件头信息,结合文件头信息,我们在进行定向排查,最终定位为一个监控脚本存在bug,导致会在根目录下周期性删除一个以脚本内一段代码作为文件名的文件,这些信息会记录在dentry内,作为negative dentry。据说写出这个bug的程序员已经被祭天了~阿弥陀佛

【解决方案】
那怎么清理呢?大神并没有给出具体的清理代码,我们只能设想会有这么一段代码,会一点点释放在dentry内的cache,在不影响业务系统的情况下,清理干净。
当然如果要选择暴力的方式的话,如下:
#echo 2 > /proc/sys/vm/drop_caches释放slab中的dentry和inode cache
然后准备跑路吧!!!(业务估计会受到影响吧!)
知识点1:RT throttling
"Sched: RT throttling activated" 是 Linux 内核中实时调度策略(Real-time scheduling policy)中的一条消息。它通常在内核日志中被打印出来,表示实时进程(Real-time process)的执行时间超过了其预定的时间片(time slice),因此内核将会对该进程进行抑制(throttling)以保证系统的稳定性和可靠性。
当一个实时进程的执行时间超过了其预定的时间片时,内核会通过调整该进程的时间片或者暂停该进程的执行来防止它对系统造成不必要的负载。这就是所谓的“实时调度策略中的抑制(throttling)”。当内核对实时进程进行抑制时,它会打印出“Sched: RT throttling activated”的消息以表明该行为。
知识点2:systemctl daemon-reload机制
systemctl daemon-reload 命令用于重新加载 systemd 的配置文件,以使最新的更改生效。它的加载流程如下:
当执行 systemctl daemon-reload 命令时,systemctl 程序会解析系统中的所有 systemd 配置文件,包括服务单元文件(unit files)和其他相关配置文件。
systemctl 将检查这些配置文件的语法和有效性,确保它们符合 systemd 的规范。
如果配置文件没有语法错误或无效项,systemctl 将会将这些配置文件加载到 systemd 的运行时环境中。这意味着 systemd 程序将会使用这些新的配置文件来管理系统服务。
加载完配置文件之后,systemctl 将会更新系统管理数据库。这个数据库被称为 systemd 的实例,它用于跟踪系统中各个服务的状态、依赖关系和其他相关信息。
一旦完成数据库的更新,systemctl 就会通知 systemd 进程重新加载配置,以使新的配置生效。
需要注意的是,systemctl daemon-reload 只是重新加载配置文件,并不会启动或停止任何服务。要应用配置文件的更改,通常需要运行 systemctl restart 或 systemctl reload 命令来重启或重新加载相应的服务。
知识点3: nevagative dentry概念
Linux kernel里的dentry是一个目录项在内存中的表现形式。有了它,此前解析过的路径就不需要再逐个目录节点解析一次了,可以直接拿到目标文件或目录。这些dentry cache可以让文件路径lookup工作大大加速。尤其是那些频繁访问的目录(如/tmp, /dev/null, /usr/bin/tetris)都在dentry cache里,可以节省大量filesystem I/O操作。
而negative dentry则不太一样:这是指文件树lookup过程中失败的项目在memory中的记录。如果用户敲入“more cowbell”命令并且当前目录下没有cowbell这个文件,那么kernel就会相应创建一个negative dentry。如果我们这个假象用户很固执,一直重复键入这个命令,kernel就可以以更快的方式来告诉用户“这个文件不存在”,尽管用户更早看到这个消息其实也不会怎么开心。

















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









