







我们应该都用过迅雷这种下载工具吧,迅雷下载工具中运用了多线程下载。多线程文件拷贝是实现多线程下载的基础,下面给出了多线程文件拷贝的实现代码:
//copyfile.cc
#include <iostream>
#include <cstring>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <pthread.h>
using namespace std;
/************************************
*使用指定线程实现从文件的拷贝
*创建时间:2011.07.28
*修改时间:2011.07.29
*作者:hahaya
***********************************/
//最大使用的线程数
const int MAX_THREADS = 5;
typedef struct TAG_INFO
{
char *fromfile; //源地址
char *tofile; //目的地址
int num; //启动的第i-1个进程
}info;
//st_size的类型为__off_t
int get_size(const char *filename)
{
struct stat st;
memset(&st, 0, sizeof(st));
stat(filename, &st);
return st.st_size;
}
void* threadDL(void *param)
{
info info1 = *((info*)param);
FILE *fin = fopen(info1.fromfile, "r+");
FILE *fout = fopen(info1.tofile, "w+");
int size = get_size(info1.fromfile);
//将文件指针分别设置在每个线程要读和写的位置
fseek(fin, size*(info1.num)/MAX_THREADS, SEEK_SET);
fseek(fout, size*(info1.num)/MAX_THREADS, SEEK_SET);
char buff[1024] = {'\0'};
int len = 0;
int total = 0;
while((len = fread(buff, 1, sizeof(buff), fin)) > 0)
{
fwrite(buff, 1, len, fout);
total += len;
//如果读入的数据大于文件总大小除线程总数则停止读入,因为每个线程要读或写的数据就等于文件总大小除线程总数
//可能会多写入一些数据,下一次写入时会覆盖多写入的数据,所以不用担心
if(total > size/MAX_THREADS)
{
break;
}
}
fclose(fin);
fclose(fout);
}
int main(int argc, char *argv[])
{
//先创建一个与文件1同样大小的文件
creat(argv[2], 0777);
truncate(argv[2], get_size(argv[1]));
pthread_t pid[MAX_THREADS];
info info1;
//启动指定线程数的线程
for(int i = 0; i < MAX_THREADS; i++)
{
memset(&info1, 0, sizeof(info1));
info1.fromfile = argv[1];
info1.tofile = argv[2];
info1.num = i;
pthread_create(&pid[i], NULL, threadDL, (void*)&info1);
}
//等待线程结束
for(int j = 0; j < MAX_THREADS; j++)
{
//pthread_join不能用在创建进程的for循环中,否则创建第一个进程后会等待第一个进程结束后创建第二个进程
pthread_join(pid[j], NULL);
}
cout << "file copy success......" << endl;
return 0;
}
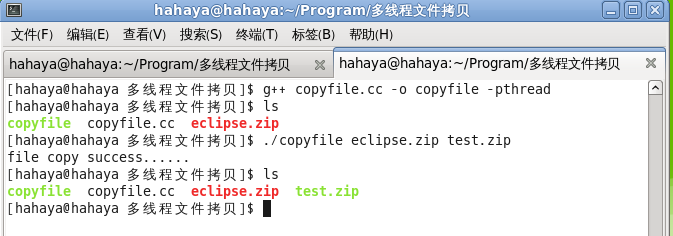
程序运行截图:
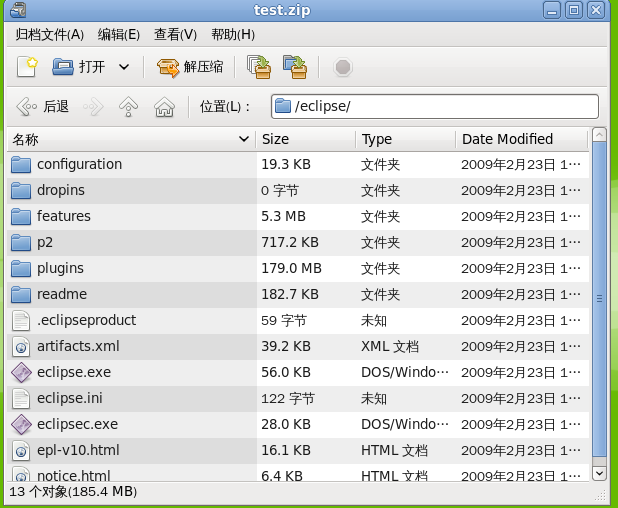
复制后的文件是完整的,可以解压,如下图:















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









