







 该项目通过对学生饭卡消费数据的分析,采用随机森林算法实现“隐私”扶贫、“精准”扶贫,准确率达到86%。
该项目通过对学生饭卡消费数据的分析,采用随机森林算法实现“隐私”扶贫、“精准”扶贫,准确率达到86%。
qiuzitao机器学习(五)
寒假在做之前省级立项的大创项目,准备结题了,导师也说拿给师姐做毕业设计,所以先提上日程。
一、项目介绍
先介绍一下我的项目《智能贫困认定系统》,是通过对学生的饭卡消费数据进行提取筛选,对这些数据进行综合分析和预处理,再计算贫困生的一些行为特征的信息增益。最后,采用随机森林算法对处理后的数据进行精准分类,达到了“隐私”扶贫,“精准”扶贫的效果。
二、项目实施
1.这是拿到的原始数据,可以看到非常不规范,而且我打开时格式出错,这给数据处理带来麻烦。
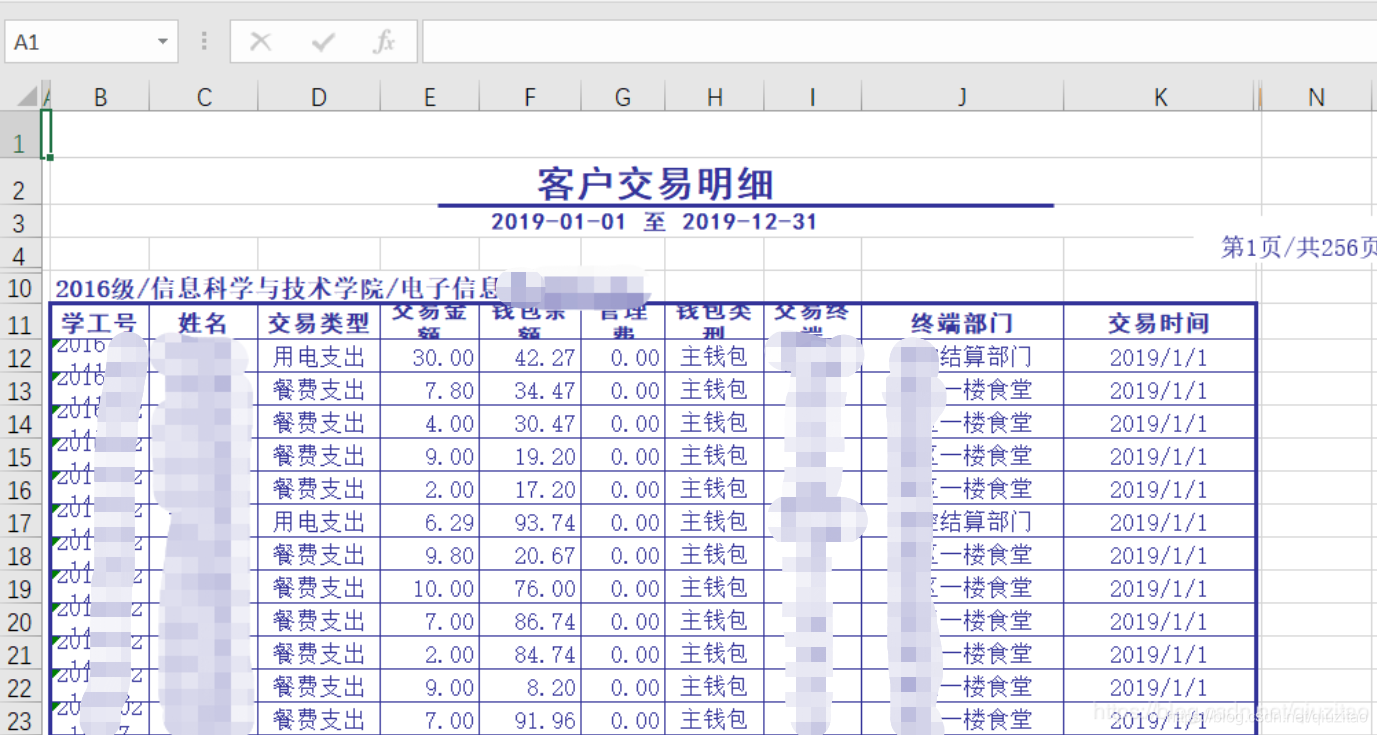
2.我把数据保存成代码可以读,然后进行合并成一个Excel。
import os
import pandas as pd
#此方法用将xls转化为xlsx
def transformat():
global path #定义为全局变量
path = os.getcwd()#获取当前工作路径
file = os.listdir(path)#获取当前路径下的所有文件
for f in file:
file_name_be,suff = os.path.splitext(f)#对路径进行分割,分别为文件路径和文件后缀
if suff == '.XLS':
print('将对{}文件进行转换...'.format(f))
data = pd.DataFrame(pd.read_excel(path + '\\' + f))#读取xls文件
data.to_excel(path + '\\' + file_name_be + '.xlsx',index = False)#格式转换
print(' {} 文件已转化为 {} 保存在 {} 目录下\n'.format(f,file_name_be + '.xlsx',path))
if __name__ == '__main__':
transformat()
import openpyxl
from openpyxl import *
def exportDataFromExcel(workbook):
#从excel导出数据,转换为列表形式
wb = load_workbook(workbook)
ws = wb.active
rows = ws.max_row
col = ws.max_column
listitem = []
resultlist = []
for i in range(12,rows-5):#筛选除去前边几行和后边几行的数据
for j in range(2,col+1):
listitem.append(ws.cell(row =i,column=j).value)
resultlist.append(listitem)
listitem = []
return resultlist
def importDataToExcel(newsheet,workbook):
#将整理好的列表数据添加到新的表后边
currentrow = newsheet.max_row
resultlist = exportDataFromExcel(workbook)
numrows = len(resultlist)
for k in range(currentrow+1,currentrow+numrows):
newsheet['A' + str(k)] = resultlist[k-currentrow-1][0]
newsheet['B' + str(k)] = resultlist[k-currentrow-1][1]
newsheet['C' + str(k)] = resultlist[k-currentrow-1][2]
newsheet['D' + str(k)] = resultlist[k-currentrow-1][3]
newsheet['E' + str(k)] = resultlist[k-currentrow-1][4]
newsheet['F' + str(k)] = resultlist[k-currentrow-1][5]
newsheet['G' + str(k)] = resultlist[k-currentrow-1][6]
newsheet['H' + str(k)] = resultlist[k-currentrow-1][7]
newsheet['I' + str(k)] = resultlist[k-currentrow-1][8]
newsheet['J' + str(k)] = resultlist[k-currentrow-1][9]
if __name__ =='__main__':
#创建新表
wb = openpyxl.Workbook()
ws =wb.active
newsheet = wb.create_sheet(index=0, title="汇总")
newsheet['A1'].value = "学工号"
newsheet['B1'].value = "姓名"
newsheet['C1'].value = "交易类型"
newsheet['D1'].value = "交易金额"
newsheet['E1'].value = "钱包余额"
newsheet['F1'].value = "管理费"
newsheet['G1'].value = "钱包类型"
newsheet['H1'].value = "交易终端"
newsheet['I1'].value = "终端部门"
newsheet['J1'].value = "交易时间"
importDataToExcel(newsheet,'DIANXIN.xlsx')
importDataToExcel(newsheet,'DIANXIN171.xlsx')
importDataToExcel(newsheet,'DIANXIN172.xlsx')
importDataToExcel(newsheet,'DIANXIN173.xlsx')
importDataToExcel(newsheet,'DIANXIN174.xlsx')
importDataToExcel(newsheet,'JISUANJI178.xlsx')
importDataToExcel(newsheet,'JISUANJI179.xlsx')
importDataToExcel(newsheet,'JISUANJI1710.xlsx')
importDataToExcel(newsheet,'XINGUAN.xlsx')
wb.save('ALL.xlsx') #保存
3.最后合成一个10多万条数据的Excel,然后进行数据处理筛选,去掉重复值,计算一些有用的特征可以用于训练,补充一些缺失值,加上Y标签(贫困)。
import openpyxl
import xlwt,xlrd
import xlutils
from xlutils.copy import copy
popResult = {}
resultList = []
listItem = []
data = 'ALL.xlsx'
wb = openpyxl.load_workbook(data)
# 只有一张表,用这种方式直接获取
ws = wb.active
wb_all = xlrd.open_workbook("信科院本科生名单.xlsx") #打开待粘贴的表
sheet2 = wb_all.sheet_by_index(0)
k=sheet2.nrows
wb_pks = xlrd.open_workbook('2019信科院贫困生名单.xlsx')
sheet3 = wb_pks.sheet_by_index(0)
k1=sheet3.nrows
# range()计算边界不含右边界,所以加1
for row in range(2, ws.max_row + 1):#从第二行开始遍历
if ws['C' + str(row)].value == '餐费支出': #只取餐费支出的值
number = ws['A' + str(row)].value
name = ws["B" + str(row)].value
money = ws["D" + str(row)].value
a = money
popResult.setdefault(number, {})
popResult[number].setdefault(name, {"sum_time":0,"times":0,"sum_money":0,"money":0,"sum_maxm":0,"maxm":0,"mean":0,"medians":0,"medians":[]})
#sun_money是全部消费,money是剔除高于30后总消费,sum_time除小于等于5元的消费次数,times是除小于等于5元或大于30的消费次数
popResult[number][name]["sum_time"] += 1 # 统计交易次数
popResult[number][name]["sum_money"] += money
if 4 < money < 30: #剔除单次消费高于30的数据
popResult[number][name]["money"] += money #统计交易总和
popResult[number][name]["times"] += 1
popResult[number][name]["medians"].append(a)
if (money > popResult[number][name]["maxm"]): #取最大值
popResult[number][name]["maxm"] = money
# for循环将得到的字典popResult转化为列表形式resultList,便于遍历写入countSheet表中
i = 1
for number, name_info in popResult.items():
for name, info in name_info.items():
n = len(info["medians"])
for i in range(n - 1):
for j in range(n - i - 1):
if info["medians"][j] > info["medians"][j + 1]:
temp = info["medians"][j]
info["medians"][j] = info["medians"][j + 1]
info["medians"][j + 1] = temp
mid = int(n / 2)
listItem.append(number)
listItem.append(name)
listItem.append(info['sum_time'])
listItem.append(info["sum_money"])
listItem.append(info["maxm"])
mean = info["money"] / info['times']
listItem.append(mean)
listItem.append(info["medians"][mid])
resultList.append(listItem)
listItem = [] # 置空便于下次循环
numberRow = 0 # 获得写入表countSheet的行数
for key, value in popResult.items():
# numberRow += len(value)
numberRow += 1
print(numberRow)
# 然后将popResult写入另一个表中
countSheet = wb.create_sheet(index=0, title="统计结果")
# 直接将表头写入工作表
countSheet['A1'].value = "学号"
countSheet['B1'].value = "姓名"
countSheet['C1'].value = "性别"
countSheet['D1'].value = "贫困" #pktrain
countSheet['E1'].value = "交易次数"
countSheet['F1'].value = "交易金额" #(剔除大于30)
countSheet['G1'].value = "最大值" #(剔除大于30,小于4)
countSheet['H1'].value = "交易均值"
countSheet['I1'].value = "中位数"
for row in range(2, numberRow + 1): # 得到result_list
# 表格从第二行开始插入,而列表从index=0开始循环
countSheet['A' + str(row)] = resultList[row-2][0]
countSheet['B' + str(row)] = resultList[row-2][1]
countSheet['E' + str(row)] = resultList[row-2][2]
countSheet['F' + str(row)] = resultList[row-2][3]
countSheet['G' + str(row)] = resultList[row-2][4]
countSheet['H' + str(row)] = resultList[row-2][5]
countSheet['I' + str(row)] = resultList[row-2][6]
for j in range(1,k):
val2 = sheet2.cell(j,5).value
# val3=float(val2)
if countSheet['A' + str(row)].value == val2:
countSheet['C'+str(row)].value = sheet2.cell(j,7).value
for j1 in range(1,k1):
val22 = sheet3.cell(j1,1).value
# val33=float(val22)
if float(countSheet['A' + str(row)].value) == val22:
countSheet['D'+str(row)].value = sheet3.cell(j1,2).value
# 保存修改,没有这一步countSheet表没有保存
# wr = wb['汇总']
# wb.remove(wr)
wb.save("ALL.xlsx")
4.这样就得到我们的训练数据data_train啦。接下来我们到训练前的数据处理:①换成utf-8的csv格式方便训练,打开csv和xlsx看到不一样是因为中文编码的原因,所以做这些建议英文特征名字等等。
②查看数据,数据分析,分析哪些数据缺失要补充,哪些要进行归一化等等,引入matplotlib画图分析。
。
import pandas as pd
# data = '计机181a.xlsx'
data_xls = pd.read_excel('贫困训练数据_copy1.xlsx', index_col=0)
data_xls.to_csv('pktrain.csv',encoding='utf-8')
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFrame
# 支持matplotlib画图中文处理
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 以上代码为实现在jupyter环境下实现matplotlib画图时中文不乱码的操作
# 加载数据,查看数据
data_train = pd.read_csv('pktrain1.csv')
data_test = pd.read_csv('pktest.csv')
data_train['贫困'].fillna(0, inplace=True)#缺失值补充
data_train.head(4)
# data_test.head(4)
# LabelEncoder编码模式
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 添加一个新的列
data_train["Sex"] = le.fit_transform(data_train["性别"])
data_test["Sex"]=le.fit_transform(data_test["性别"])
data_train = data_train.drop(["性别"],axis=1)
data_test = data_test.drop(["性别"],axis=1)
data_train.head(9)
# data_test.head(9)
5.特征选择。数据拆分。选择模型测试准确率。引入F1进行评价。
X = data_train[['交易次数', '交易金额', '最大值', '交易均值','中位数','上四分位','下四分位','下八分位','Sex','月均消费']]
y = data_train[['贫困']]
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=37, random_state =33)#一个班大概37人所以我用37人来test
# 使用随机森林分类器进行集成模型的训练以及预测分析。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
rfc = RandomForestClassifier(random_state=1,n_estimators=100, min_samples_split=4, min_samples_leaf=2)
rfc.fit(X_train, y_train)
rfc_y_pred = rfc.predict(X_test)
# 输出随机森林分类器在测试集上的分类准确性,以及更加详细的精确率、召回率、F1指标。
print('The accuracy of random forest classifier is', rfc.score(X_test, y_test))
print(classification_report(rfc_y_pred, y_test))
### xgboost的方法
import os
mingw_path = 'C:\\Program Files\\mingw-w64\\x86_64-7.3.0-win32-seh-rt_v5-rev0\\mingw64\\bin'
os.environ['PATH'] = mingw_path + ';' + os.environ['PATH']
import numpy as np
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.utils.class_weight import compute_class_weight
from sklearn.metrics import classification_report
weight = compute_class_weight('balanced', classes = np.unique(y_train), y = np.ravel(y_train))
xgb = xgb.XGBClassifier(learning_rate =0.002,n_estimators=50,max_depth=9,min_child_weight=2,gamma=0,subsample=0.6,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=(weight[1]/weight[0]),seed=76,reg_alpha=1, reg_lambda=2)
xgb.fit(X_train, y_train)
y_pred = xgb.predict(X_test)
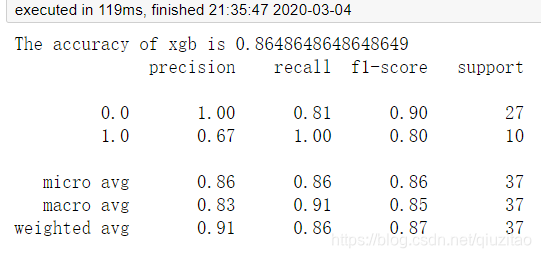
print('The accuracy of xgb is', xgb.score(X_test, y_test))
print(classification_report(y_pred, y_test))
6.引入很多模型后最后发现随机森林和xgboost的效果最好,难怪知乎上说他们是kaggle,天池等比赛的大杀器。这两个模型的准确率都达到86%左右,但是对于贫困的认定不是很理想,我估计只有70%左右,所以我后面进行十折交叉验证和学习曲线,发现了问题。
7.交叉验证。学习曲线。
from sklearn import cross_validation
import xgboost as xgb1
kf = cross_validation.KFold(X.shape[0], 50, random_state=2,shuffle=False)
from sklearn.cross_validation import cross_val_score
k_range = list(range(29, 60)) # K的范围[1, 30]
k_scores = [] # 存放每个K的评价结果
for k in k_range:
rf = RandomForestClassifier(random_state=1, n_estimators=k, min_samples_split=4, min_samples_leaf=2)
scores = cross_val_score(rf, X, y, cv=kf, scoring='accuracy')
k_scores.append(scores.mean())
print(k_scores)
dtc = xgb1.XGBClassifier(learning_rate =0.002,n_estimators=50,max_depth=9,min_child_weight=2,gamma=0,subsample=0.6,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=(weight[1]/weight[0]),seed=76,reg_alpha=1, reg_lambda=2)
rfc = RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=4, min_samples_leaf=2)
scores1 = cross_validation.cross_val_score(rfc, X, y, cv=kf)
scores2 = cross_validation.cross_val_score(dtc, X, y, cv=kf)
# Take the mean of the scores (because we have one for each fold)
print("RandomForest",scores1.mean())
print("XGBClassifier",scores2.mean())
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
# from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import KFold
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.show()
# plt.gca().invert_yaxis()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
# cv = KFold().split()
X= X.as_matrix()
y= y.as_matrix()
plot_learning_curve(rfc, u"rfc学习曲线", X, y,ylim=(0.7, 1.01))
plot_learning_curve(xgb, u"xgb学习曲线", X, y,ylim=(0.7, 1.01))
8.我看到结果后发现真实运用到准确率可能只有80%,然后我看到他们两个模型的学习,随机森林的不收敛,然后我就怀疑随机森林会不会过拟合,但我一查,网上很多都说随机森林一般来说树设置足够多(我这里100棵),就不会过拟合。当然我也知道几乎所有模型都存在过拟合现象,但一般来说随机森林比较难出现。所以后面我继续对学习曲线还有过拟合部分进行更深入的了解。以下是结果保存的代码。
# coding=UTF-8
# 利用现有模型训练
feature = ['交易次数', '交易金额', '最大值', '交易均值','中位数','上四分位','下四分位','下八分位','Sex','月均消费']
data_X_test = data_test[feature]
# data_X_test.head()
test_preds = rfc.predict(data_X_test)
np.savetxt('pkresult.csv',np.c_[data_test["学号"].values,data_test["姓名"].values,test_preds],delimiter=',',header='学号,姓名,贫困',comments='',fmt='%s')
三、总结
通过这次项目,我提高了实践动手能力,从一个什么都没有的或者说在大数据和人工智能时代还没到来之前这是一堆没有什么价值的数据,到现在的数据就是金钱的时代,数据真的很重要,有时候数据的处理比模型的调优调整你的准确率提高的更多。然后我也可以自己熟练去处理整个项目,熟悉流程。当然我也认识到了自己存在的不足的地方,所以接下来会有方向去解决那些发现的问题。



















 3911
3911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











