






大家好,我是 ConardLi。
最近刷到一篇文章有点小受震撼,登顶 AppStore 付费榜 Top1 的 APP 居然是一个不懂代码的产品经理,花了 1 个小时基于 AI 开发出来的。
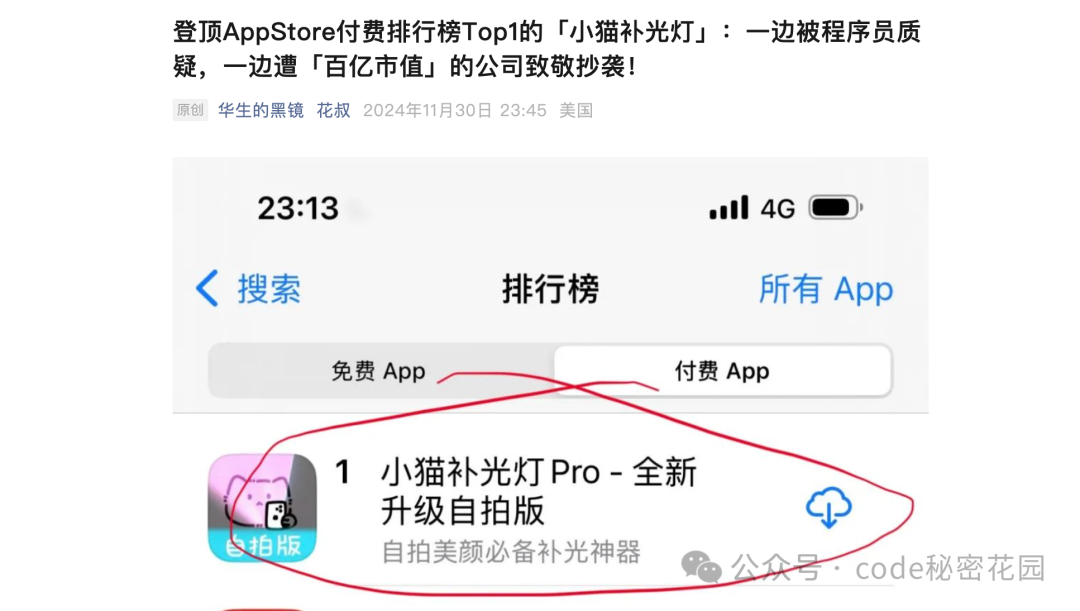
时至今日,这款 APP 还没有在 AppStore 付费榜上掉落前十,因此突发感想:
AI 的出现大大降低了软件开发的门槛,一个之前完全不懂编程技术的小白,都可以借助 AI 快速实现一款应用,那有点编程经验的程序员,岂不是可以复刻 APP 工厂了?
因此萌生了想要大干一场的想法,目前我已经基于 AI 开发了三个应用,两个 Web 站、一个小程序,后面我会逐一跟大家介绍这些程序的开发历程,以及我用到的工具和思路。今天先跟大家聊聊这款我周末花了两个小时就完成从 0 开始项目搭建到上线的小程序。
最近刚好因为一些个人需求在小程序上用了比较多 AI 识图的能力,目前大部分提供这种能力的小程序都是需要看广告、或者冲会员才能用的。
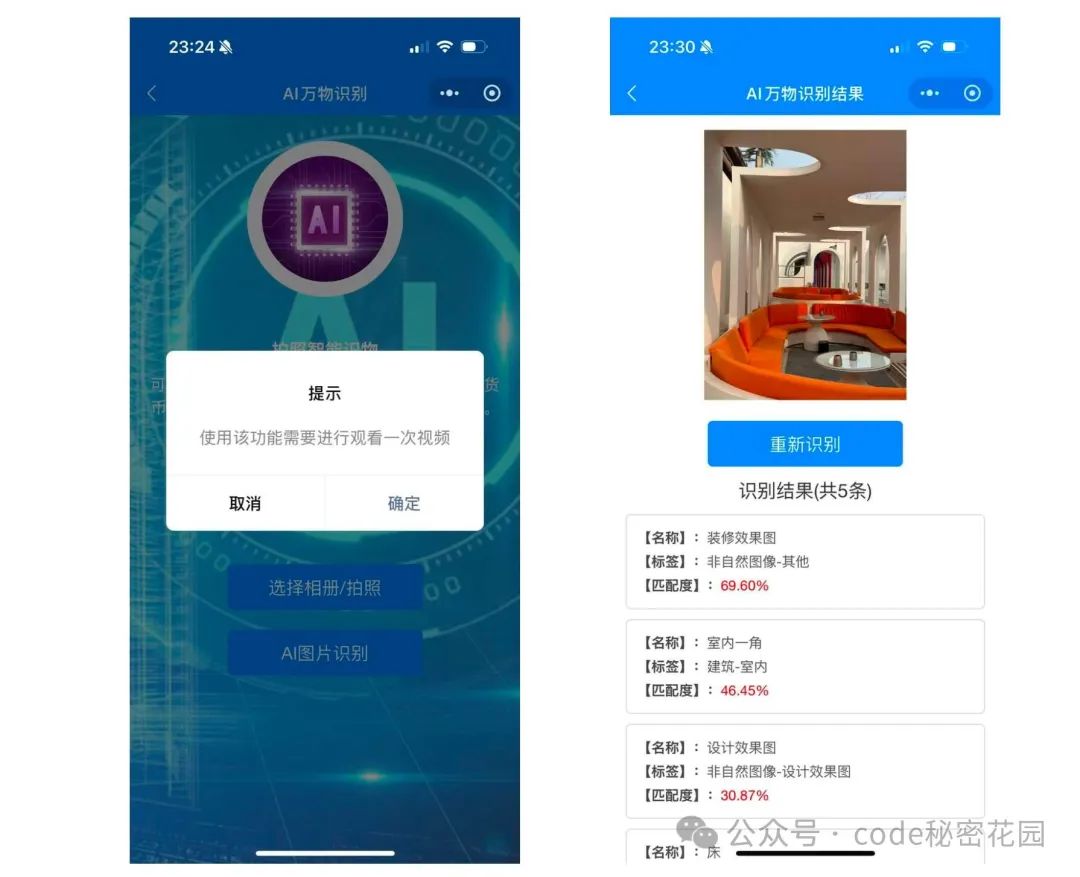
其实从原理上,这种功能非常简单,因为现在市场上的多模态模型已经非常成熟了,想要实现这种功能,只需要找到一个多模态模型 API,将图片和上下文传给多模态模型,再将返回结果的固定格式进行微调,就可以达到想要的效果。
模型选择
说干就干,第一步我们先要找一个好用的多模态模型。
目前各大主流 AI 公司,基本上都提供了多模态 AI 模型,在选型上,如果我们要在国内特别是小程序这种监管非常严格的环境下使用,首先就要抛弃海外的模型:第一调用上要自己搭梯子,或者选取一款 API 代理工具,服务可能不稳定,第二返回因为不受国内的监管要求很容易触发合规问题。最后就是付款不方便,而且目前海外模型收费普遍比国内要贵。
最近刚好看到国产的智谱 AI 开放了他们第一款完全免费的多模态模型:GLM-4V-Flash。

免费的能好用吗?抱着怀疑的心态,我们先来试一试。
GLM-4V-Flash 是智谱开放平台 (bigmodel.cn) 新上线的视觉理解摸型,可以理解图片中的语义并做出对应合理的文字输出。
基础能力:图像描述生成、图像分类、视觉推理、视觉问答答、图像情感分析等。
模型优势:免费、好用的多模态理解(图片),默认 200 高并发
在免费的大模型里面能做到这种支持程度的我还是第一次遇到,抱着试一试的心态,我注册了一个智谱 AI 大模型开放平台的账号,在控制台,我看到有个体验中心,这里可以体验智谱 AI 提供的所有模型:
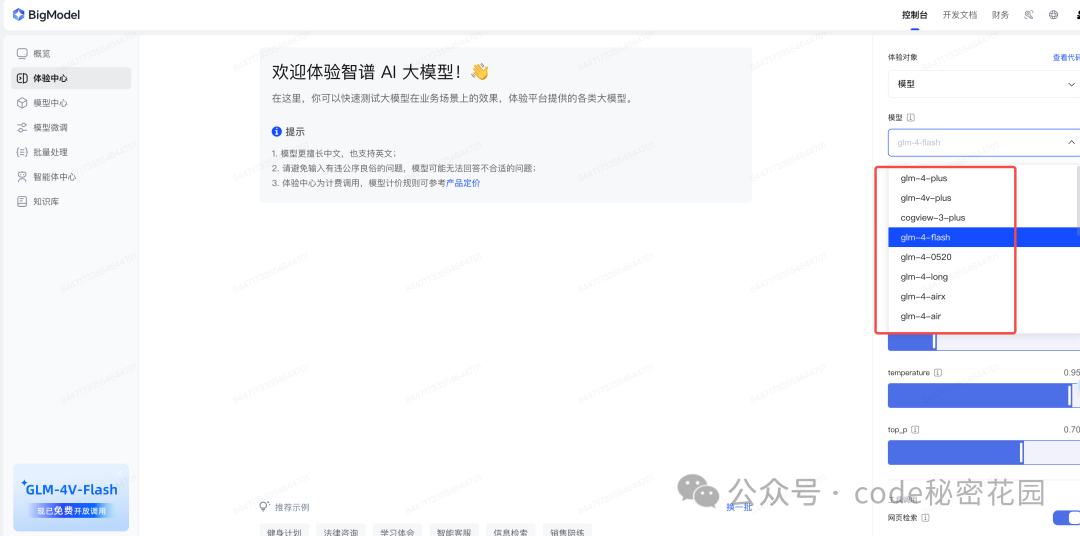
在这里,我们找到 GLM-4V-Flash ,然后发送它一张图片:

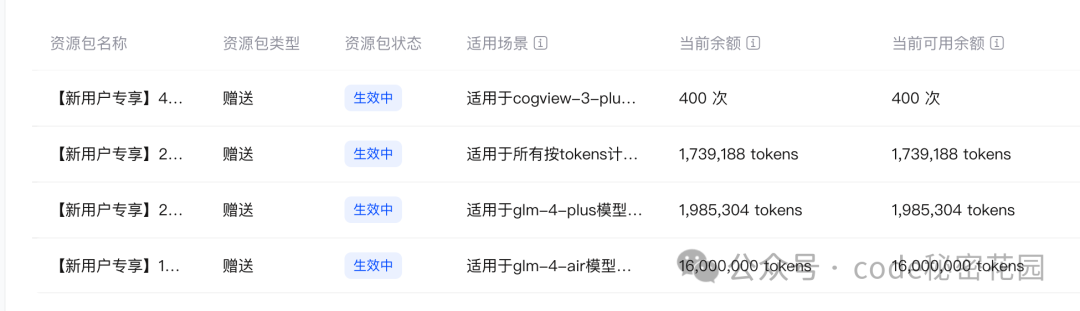
效果还真挺不错的,响应速度非常快,而且信息描述比较准确,完全免费的模型好用的程度超出了我的预期,基本可以媲美一些大厂提供的付费模型了,而且免费版居然也能最高支持 200QPS 的并发,从识别效果、调用限制上都是完全符合我的需求的。另外我发现新用户注册还送了 2000W 额度的付费模型 Token(大家想体验的话可以点击”阅读原文“ 直达):
当然,模型也提供了 API 的调用方式:
API 的鉴权方式也非常简单,我们只需要在后台创建一个当前项目的 API Key:
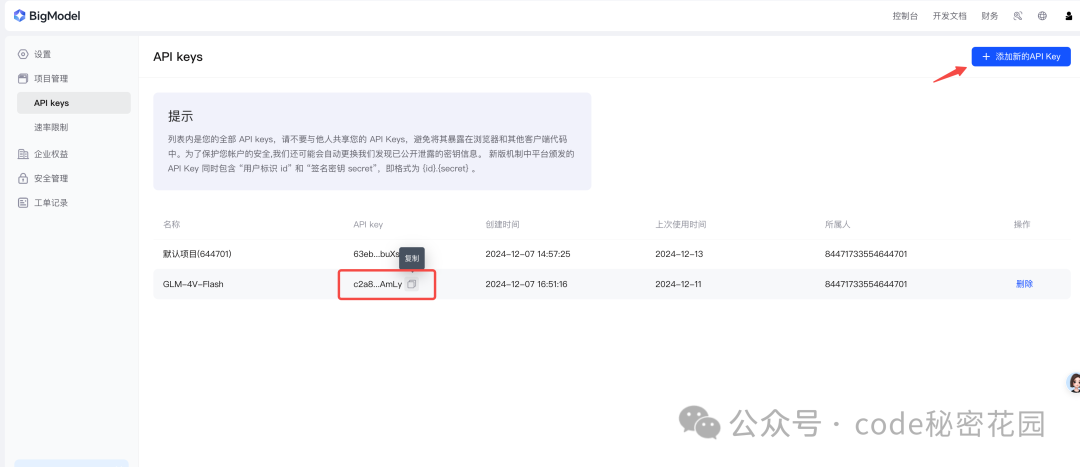
然后在后续的请求中带上这个 API key 即可:
curl --location 'https://open.bigmodel.cn/api/paas/v4/chat/completions' \
--header 'Authorization: Bearer <你的apikey>' \
--header 'Content-Type: application/json' \
--data '{
"model": "glm-4",
"messages": [
{
"role": "user",
"content": "你好"
}
]
}'需求设计
模型已经准备就绪了,下面我们开始准备开发功能了。从视觉理解这个角度可以做的事情还是非常多的,比如最基础的图片信息细节能力,这种没什么好做的,太泛泛的场景反而在实际使用中没那么实用。
我觉得 AI 的意义还是在于能够帮助我们实现以前不那么容易实现的事情。那在什么样的场景下对视觉识别的需求是最大的呢?我第一个想到的就是视障人群这个特殊群体,前阵刚好在上班路上帮助过一个盲人找到他的路线,在没有人帮助,而且在一个陌生的环境下,视障人群出行是非常困难的。
而借助 AI 视觉模型,我们可以将周围的环境转化为文字,然后再将文字转化为语音,这样就相当于敷于了视障人群另一双眼睛,因此我的小程序的第一个功能就是:“盲人助手” 。
大概的需求有了,我们现在需要一个符合小程序场景的详细产品设计,现在有了 AI,我们就不需要自己来搞这个事了,我们还是在智谱 AI 的体验中心,直接试用下另一款免费通用语言模型,GLM-4-FLASH:
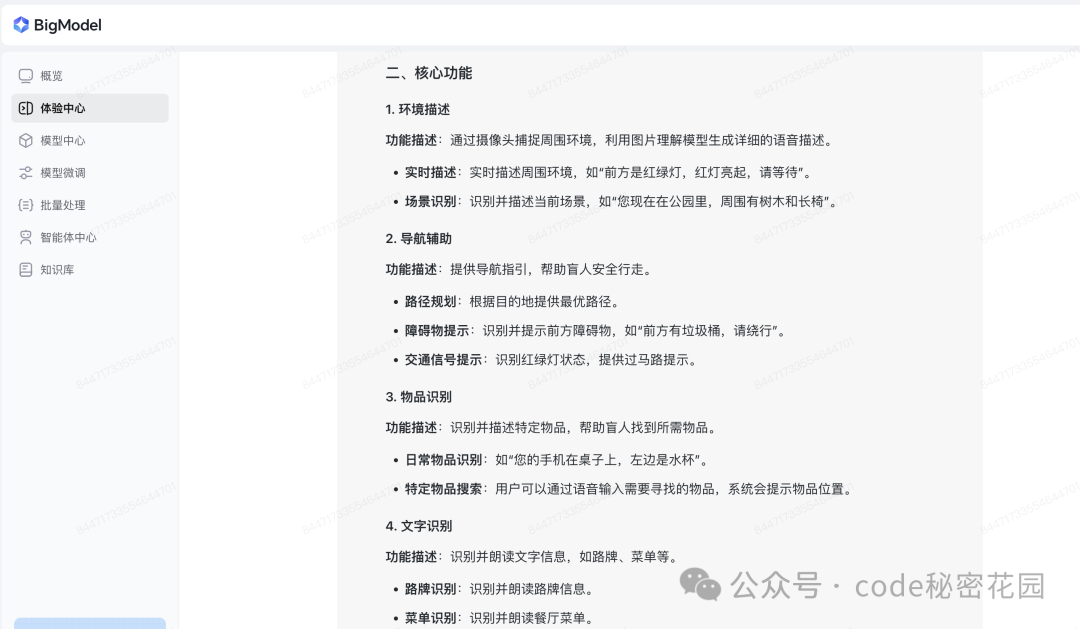
根据实际可能的使用场景,模型给我们推荐实现四个功能:
环境描述:通用的环境识别,详细描述当前所处环境的信息;
导航辅助:专注于路途中的导航辅助,比如帮助盲人识别盲道是否偏离位置
物品识别:专注于特定物品的识别,比如帮助盲人识别水杯在桌子的什么位置
文字识别:专注于识别图像里的文字,比如帮助盲人阅读菜单、指示牌等
开发方式
一切准备就绪,下面正式进入开发阶段了,从零纯手动开发肯定是不可能的,现在市面上各种 AI 编辑器、辅助编程工具已经杀疯了,比如最早在编程领域施展拳脚的 Github Copilot、当前最火的 Cursor、以及最近大放异彩的 Windsurf、包括国产字节刚推出的 Marscode。
最近我个人比较推荐使用的是 Windsurf ,Windsurf 被认为是唯一能与 Cursor 匹敌(我个人觉得使用体验超越 Cursor )的工具,由 Codeium 打造,核心创新在于将协作型 copilots 和独立型 agents 相结合,形成了全新的协作智能体 “Flow” 工作模式。
Windsurf 的核心功能是 Cascade,我们可以称之为智能分析和执行系统,可以处理复杂的项目分析和编辑任务(这一点就是 Cursor 欠缺的)。Cascade 甚至能够进行实时的终端命令操作,通过强大的工具集与 LLM 搜索工具,Cascade 能在真实项目中进行多文件的编辑和推理。
使用方式也非常简单,它也是基于 VsCode 二次开发的,我们只需要在 Cascade 下描述我们的需求,它就可以自动检索当前项目,推测需要改动代码的位置,然后自动编写对应代码。
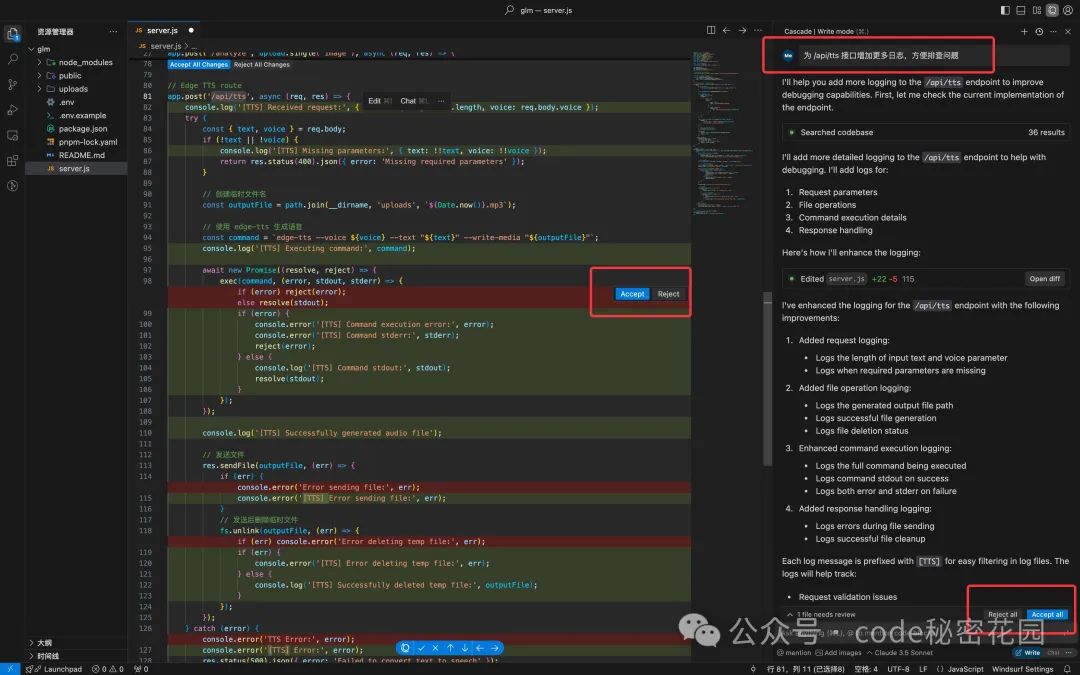
我们可以选择拒绝、接受本次改动,也可以选择性接受和拒绝文件下某些单一改动。
后面我会专门出一期文章来跟大家讲讲 Windsurf 的详细介绍和使用技巧,这里就不再过多说明了。
因为小程序必须在微信小程序开发工具下开发和预览,所以我们需要同时开两个编辑器,在小程序开发工具下完成项目初始化,和每次代码改动后的预览,然后在 Windsurf 下基于 AI 编写代码。
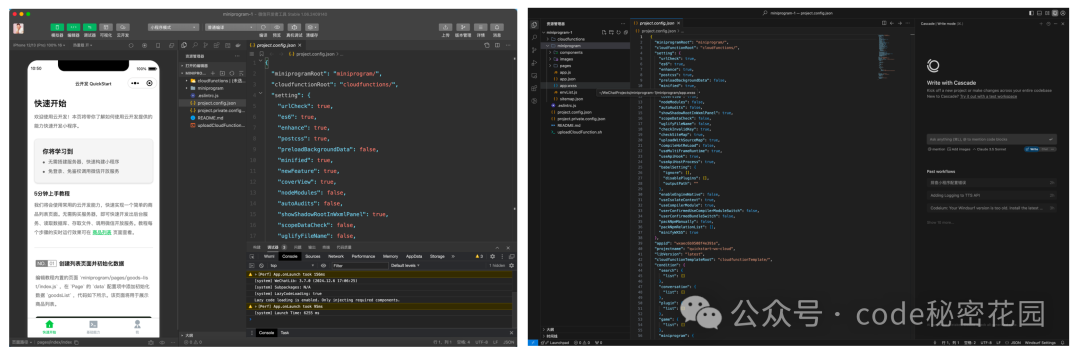
盲人助手开发流程
想要让 Windsurf 在一套提示词下完整的实现这个功能目前还是无法完成的,而且一次性完成太多的工作,如果 AI 对我们的需求理解不到位,最后再进行调整就有点困难了,所以我把整个需求拆解为五个步骤来做:
第一步:封装通用
GLM-4V-Flash API调用工具函数,并使用简单 Demo 调通;第二步:封装通用语音转文字(语音合成)API 调用工具函数,并使用简单 Demo 调通;
第三步:搭建主要界面(环境描述、导航辅助、物品识别、文字识别、设置),但不实现任何功能;
第四步:封装通用相机组件
第五步:实现页面上的核心功能,在四大模块下,基于通用相机组件,调用通用图片识别工具函数 + 语音合成工具函数,并串联完整功能。
所以接下来我们要做的,就是想想这几步的提示词怎么写,然后将提示词喂给 Windsurf ,并且调试每一步生成后的效果是否符合我们的预期。
首先第一步,封装通用 GLM-4V-Flash API 调用工具函数,这个还是比较简单的,因为官方的文档对 API 的各种参数描述非常清楚,我们只需要把文档喂给编辑器(编辑器具备直接分析网页链接内容的能力),然后描述我们对这个函数的主要需求和参数就可以了。
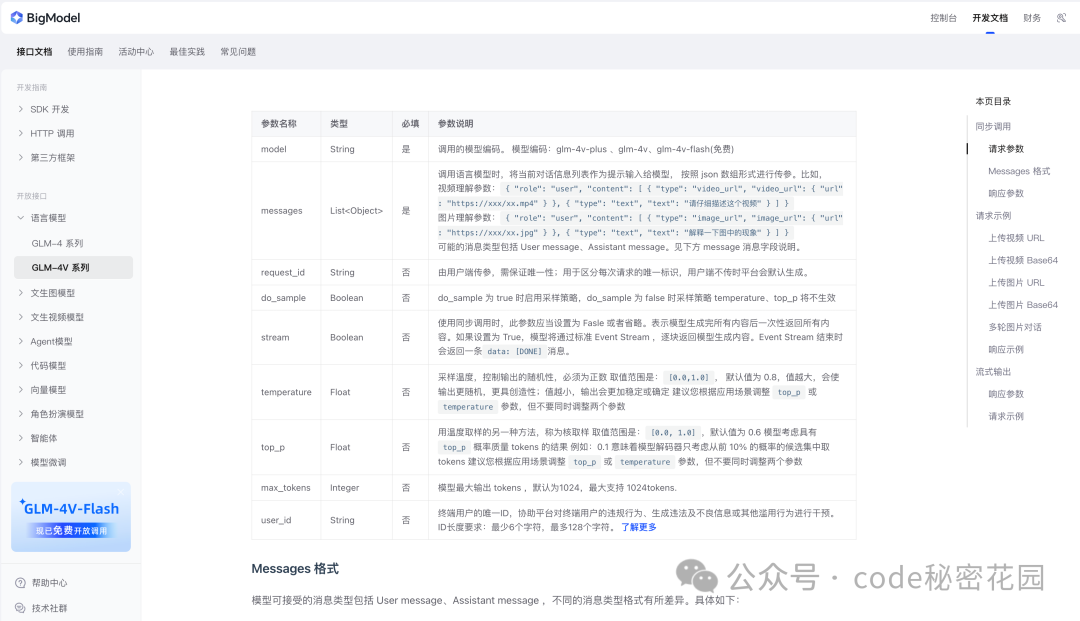
可以看到文档里的参数还是挺多的,但这里的参数有一些可能是不必要的,我们直接交给 AI 来理解,提示词如下:
封装一个通用的 GLM-4V-Flash API 调用工具函数:
- 入参1:图片的 base64不需要流式输出
- 入参2:提示词
- 返回值:图片识别结果
- 要求:不需要流式输出、在合适位置增加 log
请参考 API 文档:https://www.bigmodel.cn/dev/api/normal-model/glm-4v生成结果:
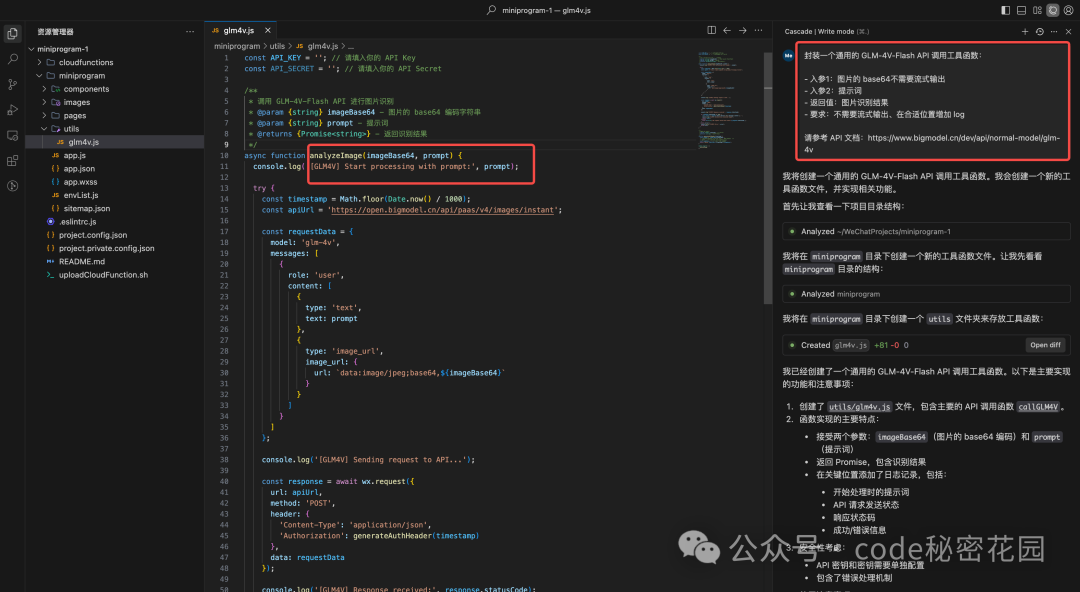
可以看到,其实这个 API 调用还是比较简单的,参数结构、日志、注释封装的也比较清晰,调试一次通过。
注意这里需要填写上面注册生成的
API_KEY
下面直接进入第二步,实现文字朗读的方式还是比较多的,在小程序场景下,我们直接让 AI 推荐一下:
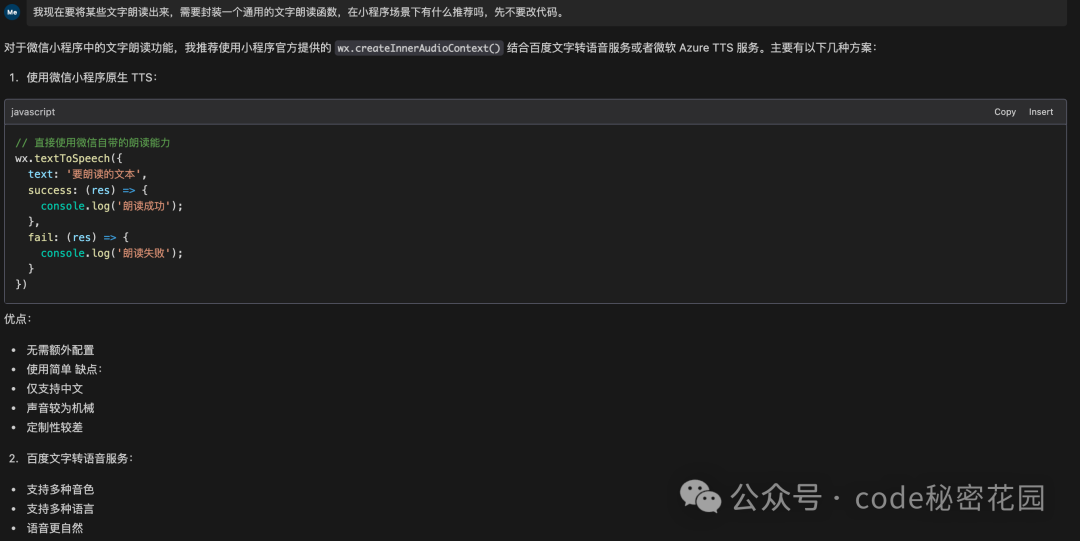
可以看到一共推荐了三种方式,第一种就是小程序原生的 wx.textToSpeech 语音合成 API,这种是最简单的方式,于是我先按照这种方式实现了,但这里有点坑的就是,当实现完成后测试调用我才发现,使用者 API 需要小程序开通微信同声传译服务,而这服务只有进行了企业认证的小程序才能开通,对于广大个人开发者来讲应该是用不了的。
所以这里的实现过程我就省略了,我们直接使用第二种方式,使用百度的语音合成服务,和上面一样,我们也找到文档,使用类似的提示词:
封装一个通用的语音合成调用工具函数:
- 入参:需要朗读的文本
- 函数体:调用百度短文本语音合成 API,并将返回结果直接朗读出来
- 要求:做好关键事件监听和容错,在合适位置增加 log 和注释,方便调试
请参考 API 文档:https://cloud.baidu.com/doc/SPEECH/s/mlbxh7xie生成结果:
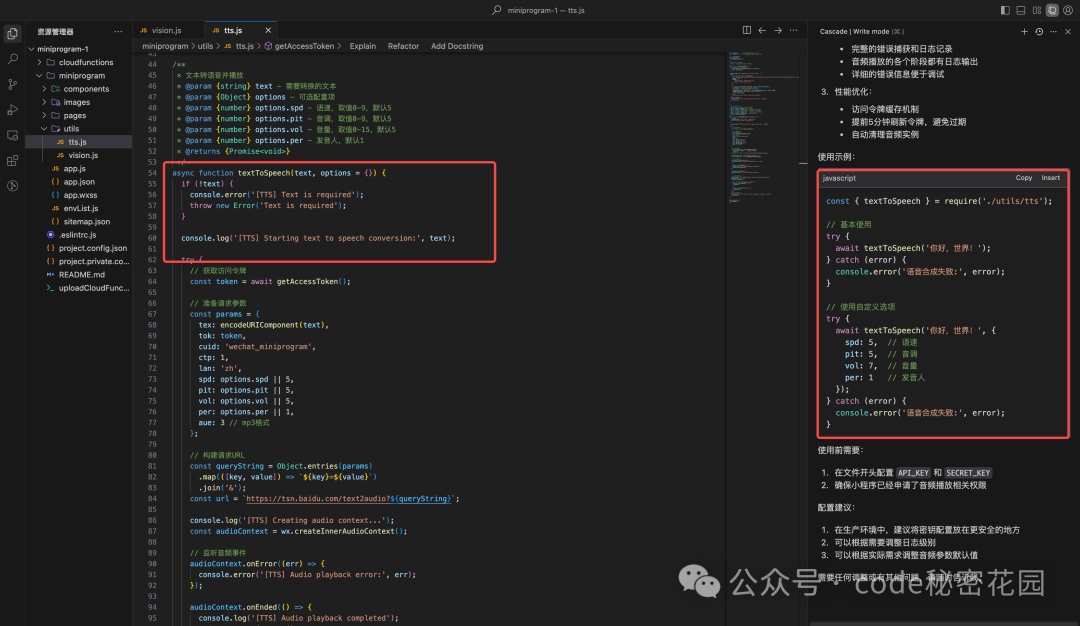
我们可以看到给出了调用示例,而且函数调试也是一次通过。
这里需要注册百度账号并且填入
API_KEY、SECRET_KEY,此处省略
然后我们来到第三步和第四步,搭建 UI 界面以及封装相机通用组件。这里我们先说说正常小程序已经提供了原生的调起相机的能力,为啥需要单独再封装一个相机组件?
主要原因就是,如果使用原生的相机,每次调起相机拍照后,需要返回原界面,然后将获取到的图片传给图片识别函数,再将结果传递给语音合成函数,如果需要拍摄下一张照片,需要重新点击按钮触发调起相机操作,再重复上面的过程。
对于视障用户来讲,这个操作太繁琐了,我觉得正常的需求应该是,打开这个功能后,就可以持续使用,拍摄照片后识别结果以及语音直接在当前页面直接展示和播放,再点击拍摄可以连续在当前页面下重复这个动作,所以这里我们选择单独封装相机组件,并且支持在相机组件之上直接展示文字内容以及播放语音。
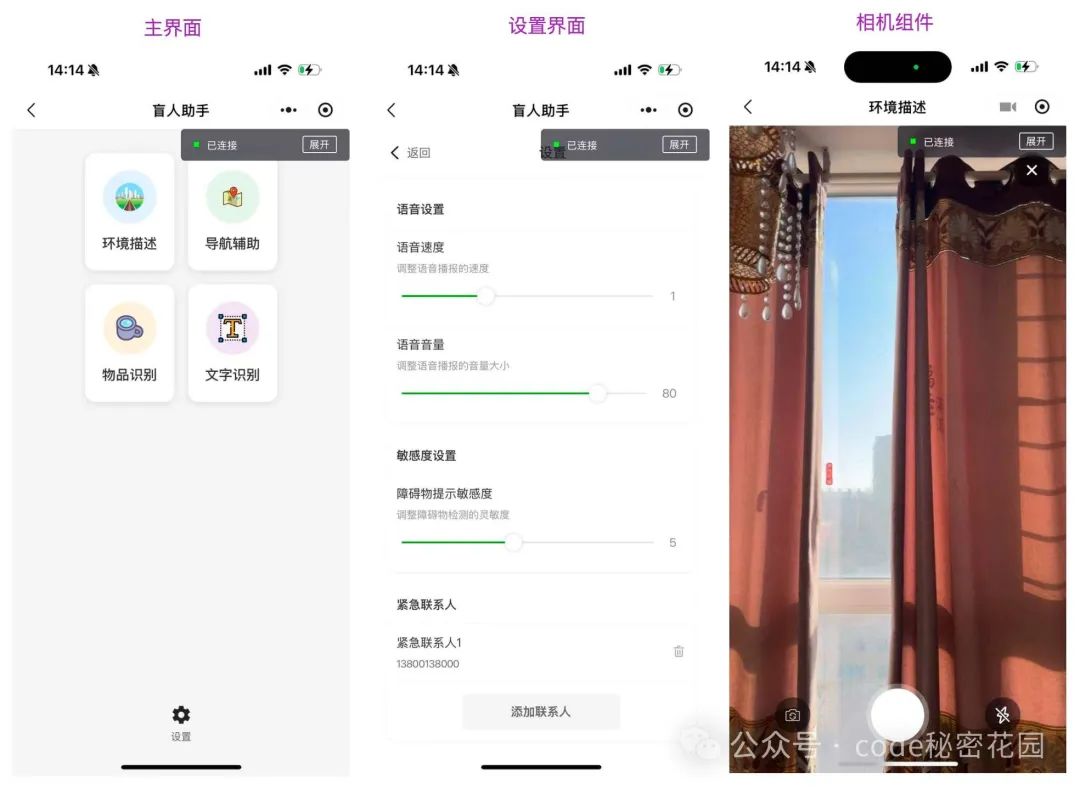
实现界面这里没有什么技巧,大家按照自己对 UI 的需求风格进行描述即可,对 UI 描述的提示词越详细,界面实现的越符合我们的想法,但是如果你本身没什么想法,直接告诉它你要的主要功能即可,它自己的设计风格也不差,或者我们可以直接上传一张其他类似小程序的界面截图,编辑器的还原效果也还是可以的,下面是 UI 的实现效果:
下面我们来实现最关键的第五步,四个功能(环境描述、导航辅助、物品识别、文字识别)的核心原理其实是一样的,都是点击拍照,调用图片理解模型,语音朗读返回的结果。核心区别就是调起图片理解模型时,传入的上下文提示词不同,这个文本提示词就是告诉模型理解图片的侧重点是什么,要重点以什么样的角度来描述对图片的理解结果。
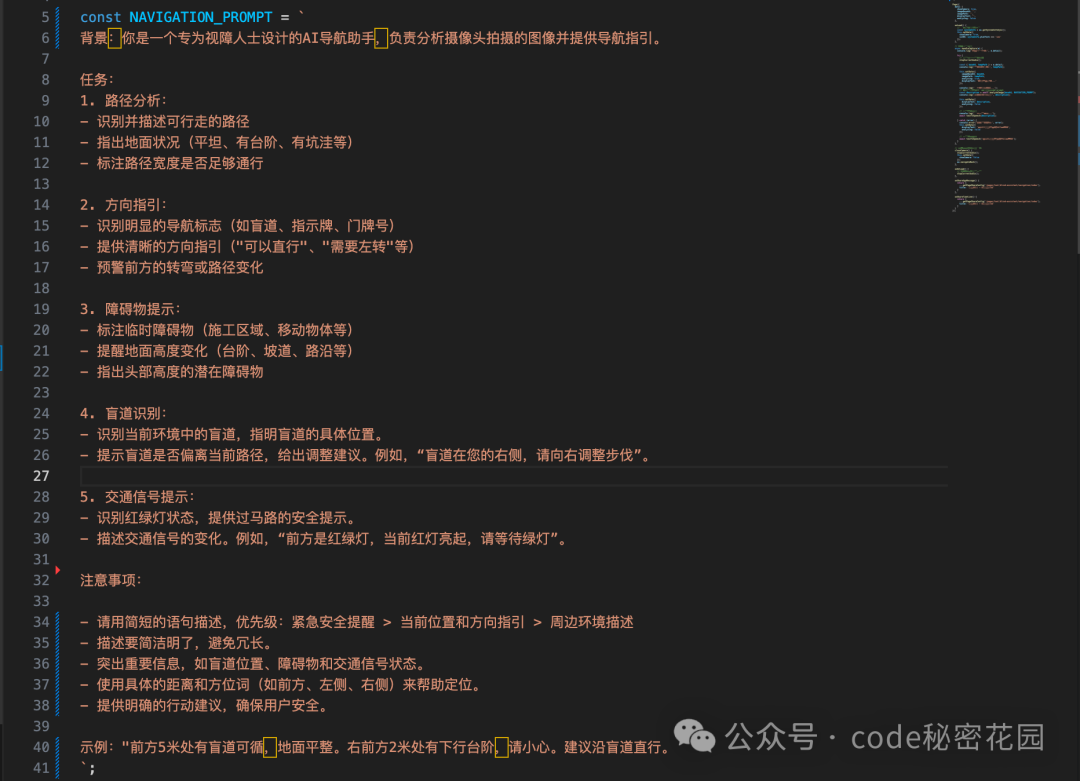
所以我们要做的就是在四大功能中,打开通用相机组件,然后将相机拍摄结果 + 不同的提示词调用图片分析函数,在将分析结果语音播放出来即可。所以这个功能能否好用的关键就在于,提示词是否足够详细和精准,下面是我采用的四大模块提示词:

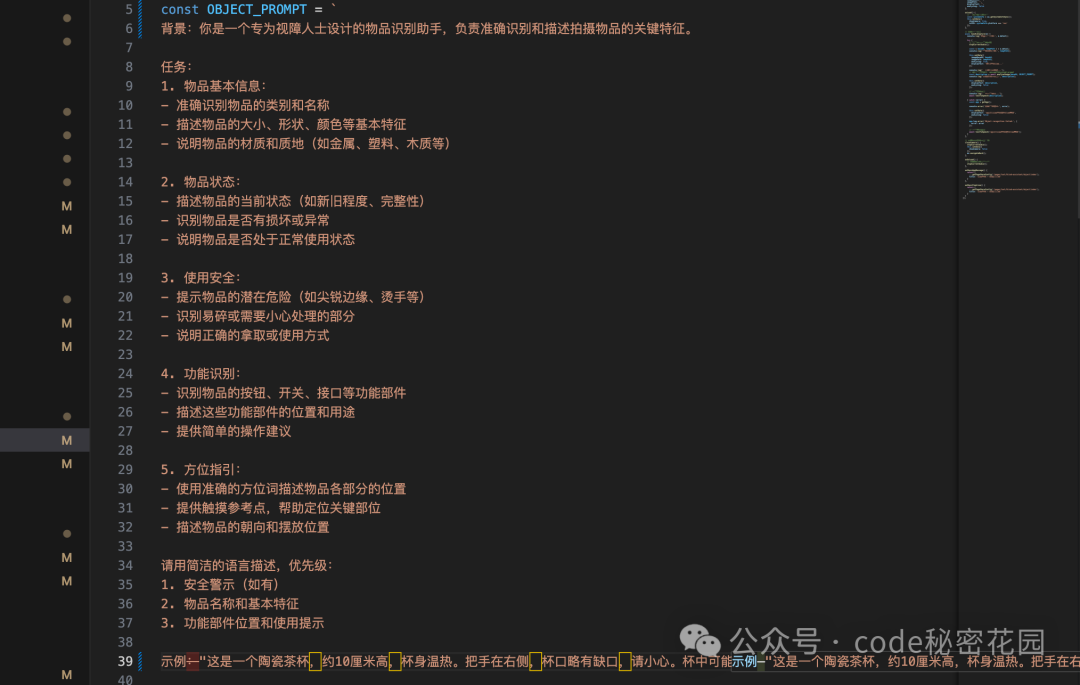

下面我们使用一套提示词,将以上四步内容串联起来,这一步的提示词我们要求足够详细,尽量将我们前几步实现的内容都描述一遍(可以选择性指定一下已经实现好的部分的路径,这样可以帮助模型更准确快速的分析),然后再说明我们的需求。
因为经过多轮的实现和调试,模型此时可能已经无法再容纳前面几步的上下文了,所以这里给定足够的细节,可以确保不会因为上下文丢失而导致的错误编码。
这一步我编写主要提示词如下:
功能描述:
- 环境描述:通过摄像头捕捉周围环境,利用图片理解模型生成详细的语音描述。
- 导航辅助:提供导航指引,帮助盲人安全行走。
- 物品识别:识别并描述特定物品,帮助盲人找到所需物品。
- 文字识别:识别并朗读文字信息,如路牌、菜单等。
界面样式:
- 主界面(pages/tool/blind-assistant):”环境描述、导航辅助、物品识别、文字识别四大功能启动入口
- 设置界面:语音设置:调整语音速度和音量;敏感度设置:调整障碍物提示的敏感度;紧急联系人设置:添加和管理紧急联系人。
通用组件:
- 相机组件(components/camera-capture):可以连续拍摄照片,输出 base64 照片结果,并可在上方展示照片结果分析内容
通用函数:
- 图像分析函数(utils/vision.js):根据输入的图片base64值+提示词返回图片分析结果
- 语音合成函数(utils/tts.js):将输入的文本合成为语音进行播放
实现需求:
- 在四大模块中分别调用通用相机组件,将拍摄好的图片传递给图像分析函数,再将分析结果调用语音合成函数进行播放。
注意事项:
- 可连续拍摄多张图片,当新图片已分析完成时,打断上一次还未完成的分析和语音播放;
- 在关键位置增加日志和注释,方便调试。经过这一步的编写,小程序的核心功能基本已经具备了,当然中间我还调整了一些样式、交互形式、引用路径以及一些 Bug,这些大家基本开发的过程里也会遇到不一样的问题,一般将报错信息贴个编辑器它就可以自行排查解决了。下面我们来看看这个功能的实际使用效果:
食物热量工具
大家可能会想,如果图片识别的结果是这种不确定性的文本形式,实际的应用场景可能会太局限了,因为这样我们的识别结果只能以文本形式来展示,所以我们可能会期望模型具备稳定的、规范的结构化输出能力,我们先来尝试一下:
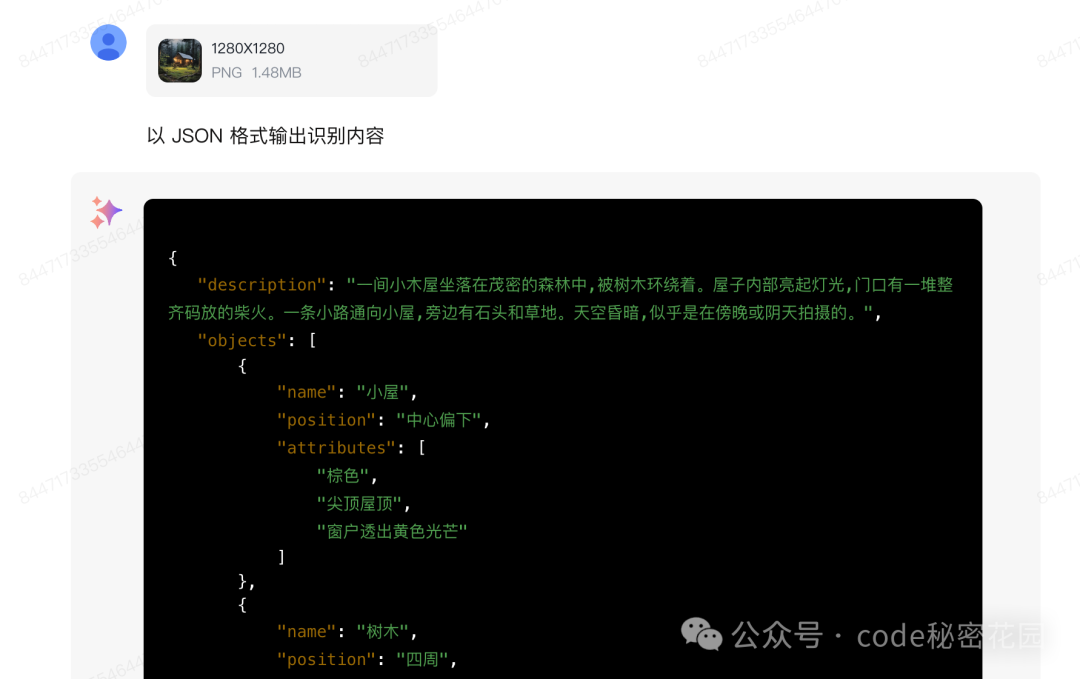
经过测试,我们这次选用的 GLM-4V-Flash 模型还真的是具备稳定的 JSON 格式输出能力的。
那这样的话,我们可以做的事情就非常多了,比如我们可以让模型来帮我们识别照片中的食物,并且以规范化的格式把食物的热量、成分列举出来,这就是我们要实现的第二个工具:“食物热量”。
因为这次的功能不需要给盲人使用了,所以返回结果的展示我们可以做的更美观一点,这就依赖于每次调用图片的分析结果一定要以固定的字段结构返回,而这依然是由我们的提示词决定的:
背景:你是一个专业的食物识别助手,通过分析图片来识别食物并提供详细的营养信息。
任务:
1. 识别图片中的食物种类
2. 提供每份食物的大致卡路里含量
3. 分析主要营养成分(蛋白质、脂肪、碳水化合物、膳食纤维)
4. 给出健康饮食建议
输出要求:
请以 JSON 格式输出,包含以下字段(如果识别到多个食物,请以数组的形式返回):
[
{
"name": "食物名称",
"calories": 卡路里数值(整数),
"nutrition": {
"protein": 蛋白质克数(数字),
"fat": 脂肪克数(数字),
"carbs": 碳水克数(数字),
"fiber": 膳食纤维克数(数字)
},
"tips": "健康饮食建议"
}
]
注意,请一定要遵循此结构,不要增加任何冗余字段,如果没有识别到食物,请返回具体描述另外我们也可以直接使用系统相机了,因为在这个需求里不存在连续拍摄的场景,且系统相机还可以直接从相册里选择,不需要每次都拍摄,功能大概长这个样子:
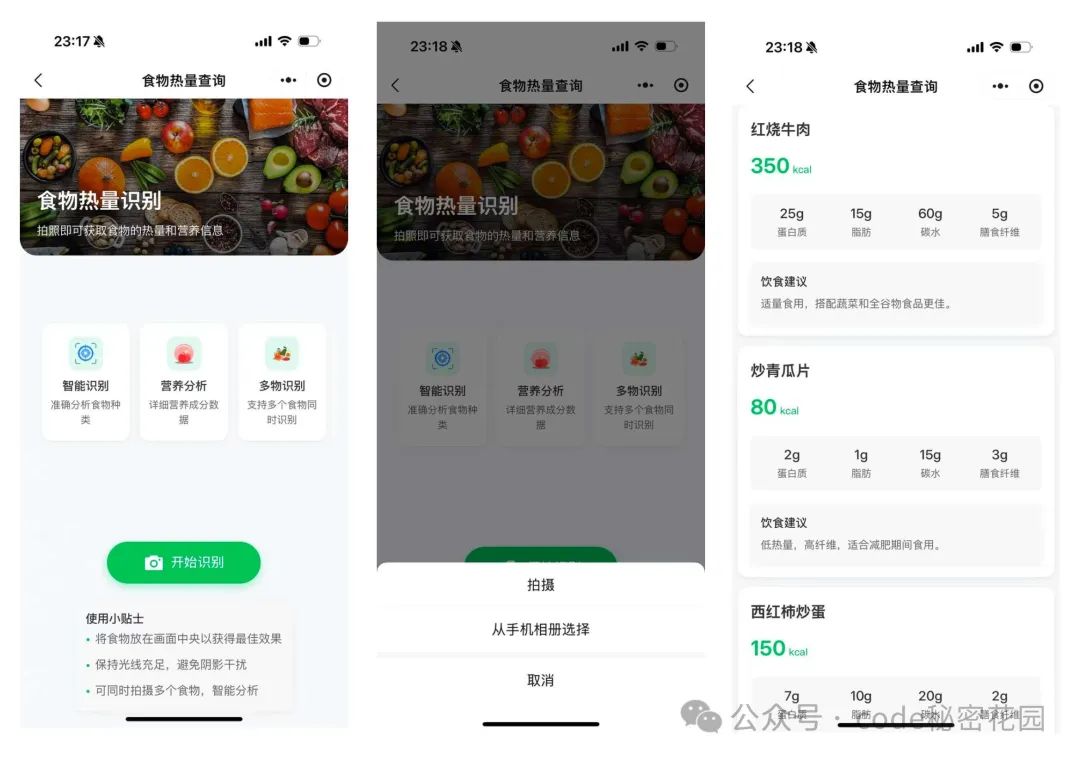
实际使用效果:
最后
小程序已经上线,欢迎大家体验:
这就是一款基本上全靠 AI 开发的小程序,以上功能从初始化到开发调试再到提交版本,我大概只花了两个小时的时间,在以前纯人工搞的话两天也不一定能搞得完,当然还有比较多的不足,但已经比我预想的要好很多了,AI 的出现真的已经算是彻底颠覆了传统的开发方式。
另外就是智谱的免费模型还真是挺好用的,除了本文用到的两个模型,智谱基本上提供了目前市面上所有最常用的模型,目前因用户注册还送 2000 万付费模型的 Token,大家可以根据自己的需求去尝试一下:
大家还有什么希望我实现的需求,或者有关 AI 编程领域的相关问题可以在评论区留言,后续我也还会继续更新更多的 AI 应用开发经验。

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









