







现在,大数据这么火,笔者也忍不住想学了。21世纪是数据的竞争,那么大数据必然是一种趋势,提前了解hadoop也为自己今后的发展奠基一席一路。虽然说移动互联开发也非常火,但也离不开数据,因此,大家还等什么呢。
目前,hadoop已经到了2.x,并且1.x与2.x的差别还是挺大,感觉自己都快跟不上节奏了。学习任何技术,都得有始有终,最好了解它的前世今生。所以笔者打算从1.x开始学起,并选择1.2.1这个比较稳定的版本进行学习。
学习任务框架技术,感觉第一步比较重要的就是搭环境,因为没有环境,一切都是纸上谈兵。对于原理不太理解,这个可以在之后的学习中慢慢进行领悟。所以,笔者作为一个大数据的菜鸟,来搭建一个自己的hadoop环境。
下面,直入正题,关于NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTracker以及hdfs、mapreduce等相关的概念以及hadoop运行原理机制在之后的博文中再进行介绍,大家可以先去查下资料,了解一下基本的概念和原理就够了。
一、linux服务器准备工作
由于没有可用的服务器,这里笔者使用虚拟机创建了三台centos服务器:
由于第一台服务器既是NameNode,又是DataNode,这里给它分2G内存,其它的都是1G。然后,编辑三台服务器的/etc/hosts文件,全部都改为:
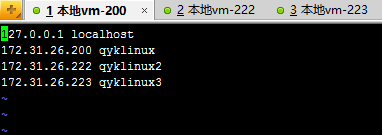
都是ip和对应的主机名。
然后,为了减少麻烦,关闭三台服务器的防火墙:
service iptables stop
相关ip和主机名设置有不清楚的大家可以去百度下,注意主机名不要有特殊符号,否则到时会出问题的。
二、jdk环境变量设置
关于jdk环境变量的设置在之前的博文中也讲过,这里就直接贴出配置:
export JRE_HOME=/usr/local/jdk1.8.0_60/jre
export JAVA_HOME=/usr/local/jdk1.8.0_60
export HADOOP_HOME=/usr/local/hadoop-1.2.1
export CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH这里提前把hadoop的环境变量也配了。注意,三台服务器都要配。
三、hadoop安装及相关配置
大家可以到官网下载:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
然后解压,笔者是放在/usr/local/hadoop-1.2.1这个目录下,其中bin目录放的都是些命令,conf目录放的是些配置文件。
然后,再来配置。
conf/hadoop-env.sh文件:
加入java的安装路径export JAVA_HOME=/usr/local/jdk1.8.0_60,如下图:
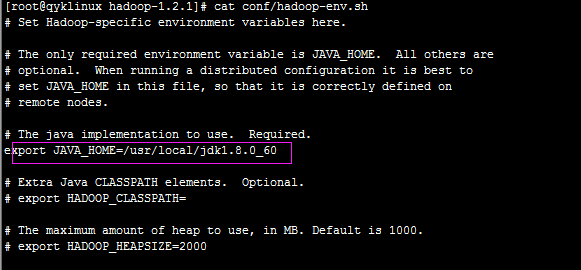
这个三台服务器都要配。
conf/core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://qyklinux:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
</configuration>这个,另外两台服务器只需将fs.default.name对应的值改为hdfs://qyklinux2:9000和hdfs://qyklinux3:9000,这是URI标识。
conf/ hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
</configuration>这个,三台服务器都配置一样。
conf/ mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>qyklinux:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/hadoop/mapred_system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/hadoop/mapred_local</value>
</property>
</configuration>这个三台服务器都一样,mapred.job.tracker是NameNode所在主机上,也就是master,因此三台配置一样。
conf/ masters:
qyklinuxconf/ slaves:
qyklinux
qyklinux2
qyklinux3这里主从节点的配置,三台服务器都是一样的,这个应该就是形成集群的关键配置。
四、无密码的ssh登录配置
建立Master到每一台Slave的SSH受信证书。由于Master将会通过SSH启动所有Slave的Hadoop,所以需要建立单向或者双向证书保证命令执行时不需要再输入密码。在Master和所有的Slave机器上执行:ssh-keygen -t rsa。执行此命令的时候,看到提示只需要回车。然后就会在/root/.ssh/下面产生id_rsa.pub的证书文件,通过scp将Master机器上的这个文件拷贝到Slave上(记得修改名称),例如:scp root@masterIP:/root/.ssh/id_rsa.pub /root/.ssh/46_rsa.pub,然后执行cat /root/.ssh/46_rsa.pub >>/root/.ssh/authorized_keys,建立authorized_keys文件即可,可以打开这个文件看看,也就是rsa的公钥作为key,user@IP作为value。此时可以试验一下,从master ssh到slave已经不需要密码了。由slave反向建立也是同样。为什么要反向呢?其实如果一直都是Master启动和关闭的话那么没有必要建立反向,只是如果想在Slave也可以关闭Hadoop就需要建立反向。
然后每台服务器上都修改ssh的配置文件:/etc/ssh/sshd_config 把GSSAPIAuthentication的值设置为no
五、hadoop集群服务启动
首先,格式化分布式文件系统hadoop namenode -format,然后进入hadoop根目录,运行:./start-all.sh启动hadoop,可以看到:
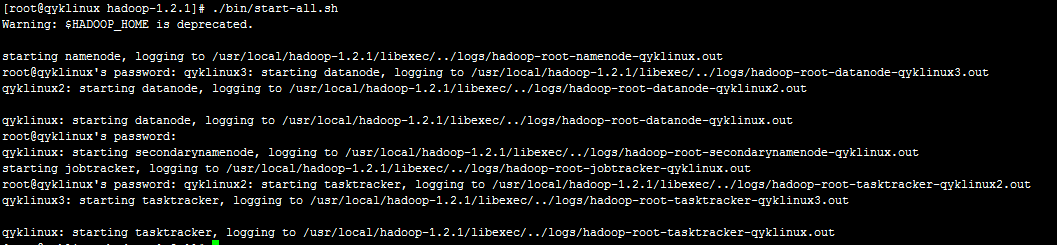
这里,我们可以看到启动顺序:NameNode、DataNode、secondarynamenode、JobTracker、TaskTracker。
然后在第一台服务器上,也就是master,执行jps可以看到:
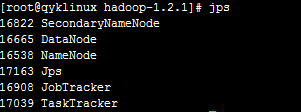
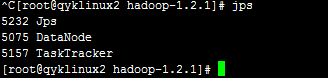
少任何一个都有问题。另外两台slave的截图如下:
然后,在浏览器访问:http://172.31.26.200:50070/:
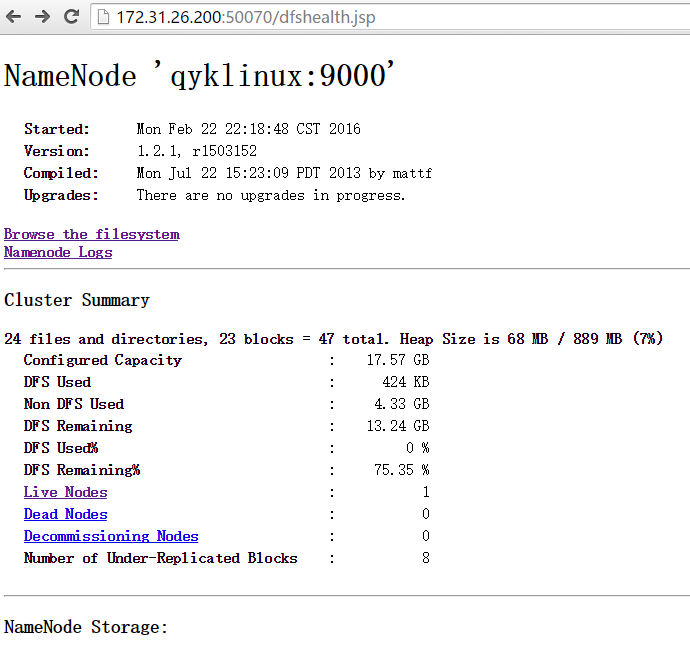
说明,环境搭建成功!
六、运行一个单词计数的hadoop任务
首先,准备两个.txt文件,在hadoop根目录下创建input目录,放在里面:


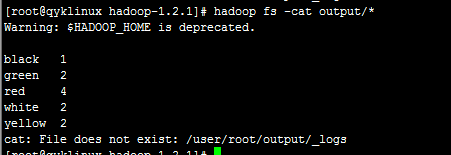
然后,执行hadoop fs -copyFromLocal /opt/hadoop/.txt input/,将本地文件放入到hdfs中。再执行hadoop jar hadoop-examples-1.2.1.jar wordcount input output便可进行单词计数,这是一个hadoop自带的任务程序例子。执行成功后,查看结果hadoop fs -cat output/:
七、总结
这个集群环境的搭建过程中,笔者也遇到了两个比较麻烦的问题,也是由于自己的疏忽造成的,只要按照步骤来,应该是没啥问题。如果出现像什么有一个namenode启动不了,可以检查下hosts配置、防火墙等,大家还可以查看hadoop的日志。像什么namespaceid不一致问题,大家可以百度下,都有相应的解决措施。
好了,hadoop的集群搭建就介绍到了,笔者也是小试牛刀,接下来要真枪实弹的干了。















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









