







项目记录: 3DOF+实时渲染 之 虚拟视点合成
总结一下实现3DOF+渲染的一些细节。
- 虚拟视点合成
- 3DOF+实时渲染方案
0. 3DOF+概念
关于 3DOF+ 概念 可以参考我之前的博文。
3DOF+:头部运动+小范围的平移
6DOF :

笔者实现在VR头盔上实时地渲染3DOF+视频,实现了运动视差。
1. 虚拟视点合成(View synthesis)
所谓虚拟视点合成,是从给定观点的一些图片开始创建特定视点位置的新视图。
分类
- 基于模型的绘制技术(Model Based Rendering,MBR)
- 基于图像的绘制技术(Image Based Rendering,IBR)
基于模型的绘制技术需要对真实场景建立一个准确的三维模型,一旦模型建立成功后,可得到任意视点的图像。但这种技术明显的缺点就是需要很强的计算机图形学知识,且对现实场景建模计算量巨大。
基于图像的绘制技术通过参考多个视点的图像,利用3D-Warping投影,视图融合,插值等技术可直接生成虚拟视点处的图像。这种方法的绘制速度很快,且生成的虚拟图像很真实,因此基于图像的绘制技术应用更加广泛。
我们下面讨论的都是基于深度信息的图像绘制方法(Depth Image Based Rendring, DIBR) 。
2. DIBR
所谓的基于深度信息的图像绘制方法(Depth Image Based Rendring, DIBR),指的是只需要几个视点的纹理信息以及其对应的深度信息就能绘制出任意视点的图像。深度信息的数据量只有纹理信息的20%左右。
深度图
- 深度信息是指视频/照片中每个像素在具有色彩信息以外,还带有一个深度信息,即我们通常所说的RGBD,表示的是该像素距离相机成像平面的距离。
- 深度图通常是8bit编码的,即量化区间[0,255],越亮,越白,越近。在全景视频中,为16bit或10bit。
- 360度视频的深度信息则是周围360度空间中的所有像素点,都带有距离信息,即提供了丰富的360度场景结构信息。
如下所示为全景视频纹理图以及其对应的深度图

2.1 深度图的获得
Q:深度信息产生/生成的方式有哪些
A: 深度信息的捕获主要分为 主动 和 被动 两种:
- 主动方式包括激光雷达和结构光(Kinect一代)和ToF(Kinect One)等。HypeVR前段时间展示的六自由度视频则是采用激光雷达的方式获取场景深度,据其介绍数据量达到了3GB每帧。
- 被动方式则主要通过计算机视觉的方式(Multi View Stereo, MVS),利用多张照片来计算出场景深度,Lytro的Immerge,Facebook的x24,Google的Jump都属于这种方式。

准确的深度信息捕捉/生成的技术难点在哪里
不同的技术方案都存在各自的局限性,目前并没有一种各方面都明显优于其他方案的深度获取方式。
-
主动式深度获取设备根据其类型不同,存在成本高(LiDAR),室外不工作(红外结构光),多径干扰(ToF),多个设备之间互相干扰的问题。

-
被动式获取方式,这里主要讨论基于三角测量的多视立体匹配(Multi View Stereo,MVS)。MVS作为一个古老的计算机视觉领域,已经有了几十年的研究历史,这也是Facebook x24,Google Jump和Deepano所采用的深度获取方式。其技术难点主要包括计算量大、优秀的MVS算法很难实时处理、鲁棒性受环境影响大、暗光环境下不工作等。其中,鲁棒性是制约MVS算法的一大因素,也是近年来各界一直在努力提升的方面。
场景中的低纹理区域(一整面白墙),重复性纹理区域(比如一整面马赛克的墙),透明物体(玻璃),高反光物体(镜子)、前后景之间的遮挡(occlusion/disocclusion)等都对MVS算法的鲁棒性提出了挑战,另外,相机阵列之间的空间位置关系标定、不同相机之间的ISP(曝光,白平衡)一致性、镜头畸变校正、广角/鱼眼镜头的渐晕现象校正、相机帧同步等也都对MVS算法有着重要影响。

2.2 深度信息在360°视频中的应用
Q: 360°视频/VR视频如果有了深度信息,能够达到什么样的效果
A: 深度的应用有很多,对于全景视频,至少有如下几个方面:
- 【1】 拼接,基于深度进行拼接可以解决近距离物体穿缝的问题。
- 【2】 用户只能被局限在一个固定的视点旋转头部而无法进行移动,基于深度可以生成可自由移动的6自由度视频。
- 【3】 视频防抖,视频防抖的一种做法是利用跟踪摄像机路径后进行路径平滑,平滑过程中需要生成新的视点,基于深度可以更自然地做到新视点的生成。
- 【4 】提升后期特效的工作效率,基于深度可以方便区别前景、背景,以及添加光源和虚化等特效。
第一个问题
讲一个生活中很常见的现象,当我们坐车望向窗外时,远处的大楼缓慢的向后方移动,近处的树木飞驰而过,而天上的太阳则永远悬挂在固定的位置。这是一个蛮文艺的画面,但在这里我想说的则是360度视频中存在的一个问题:视差。

运动就会产生视差,前面提到的现象,
就是人眼的运动导致的视差投影在视网膜上形成的画面,物体距离越近,视差越大,则在画面中位移越大:近处的树木移动最快,远处的楼房移动缓慢,太阳则似乎纹丝不动。
全景相机采用多镜头(大于等于2)采集,再将采集到的画面通过算法进行拼接。由于全景相机的镜头光心在物理上无法做到完全重合,则相当于相机之间产生了“运动”,由于镜头之间存在“运动”,则会导致两个镜头拍到的画面会有微小的差异,即:近处的物体与远处物体之间存在视差。 算法若选择在接缝处将近处物体拼好,则远处物体会出现“重影”,反之,近处物体则会缺失。这就是全景视频中人穿缝的时候,人会出现“跳变”的原因了。
深度直接表示出了每个像素到摄像机的距离,通过这些距离,我们则可以直接计算出该像素在全景视频中的真实位置,深度准确时,同一个物体在所有摄像机中的成像都会投影到全景视频中的同一个点:拼缝自然而然的就消除了。这就是我的第一个结论:深度可以消除全景视频中的第一大痛点——视差导致的拼缝,从而生成一个完全无缝的全景视频。
第二个问题 :
全景视频的第二大痛点是,用户被固定在一个视点无法自由移动,即只有三个旋转自由度(roll/yaw/pitch,单纯的旋转不会产生视差,因此没有问题),丧失了另外三个移动自由度,这也是为什么全景视频一直被质疑不是真正的VR视频:不能移动怎么能叫VR呢?
运动就会产生视差,当我们移动眼睛时,身边的物体在视网膜上的成像会根据距离不同程度的移动,从而对人眼产生反馈,除了双目视觉外,这也是人眼感受深度的一个重要方式。
深度能为六自由度VR视频提供最重要的数据,使得六自由度VR视频成为可能。
3. DIBR算法基本框架
DIBR算法框架如下图所示:
虚拟视点绘制主要的三个步骤:
- 3D-Warping:对输入的参考纹理视图以及深度图进行变换,各自生成一个虚拟的目标视图
- Blending: 将每个参考视图生成的虚拟视图进行融合。
- Inpainting:对于融合后出现的空洞进行填补。

3D-Warping
3D-Warping的基本原理为通过深度图将参考视点彩色图的每一个像素点映射到三维空间,然后再将每一像素点重映射到对应的虚拟视点上,过程如下所示:
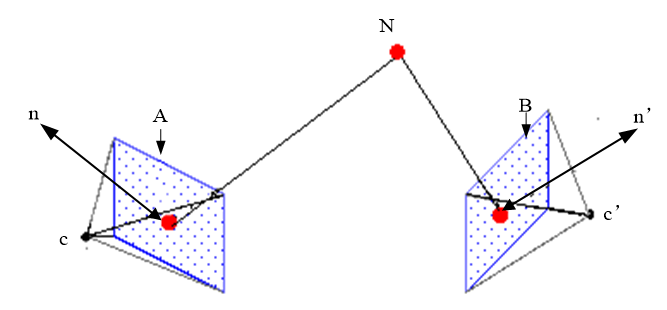
关于3D-Warping有几种方法:
【1】双向Warping
先将深度图 Forward Warping到虚拟视图,并进行中值滤波处理,可以对深度图中的裂纹进行填充,此时经过 Backward Warping后保证虚拟视点上的未遮挡点都有对应的像素值。

【2】基于三角形的Warping
在参考图像中相邻的三个像素,由于warping的拉伸而分离,因此使用一个小三角形来代替一个像素进行映射。在原始图像中选择一个三角形,先将三个点映射到虚拟图像中,再使用双线性插值填充其内部像素点,保证映射后的图像的连续性。

【3】基于区域的Warping

Blending
设左右两个参考图像映射到虚拟视点上的图片分别为TL和TR。对参考图像中所有位置的点进行遍历填充,若目标点在TL,TR中均不存在,则该点为空洞,在后面使用空洞填补算法;若目标点仅存在与TL,TR其中的一个图像中,则直接取这个值进行填充;若目标点在TL,TR中均有对应的值,则将这两个值按照一定的权重进行加权得到最终的填充值。目前的计算办法主要有以下两种:
第一种: 根据左右参考点光心与虚拟点光心的距离进行加权。
第二种: 指数加权。
Inpainting
空洞出现的三大原因
- 遮挡暴露(occlusion exposure)
- 深度图质量不高(a poor depth-map quality)
- 映射时的舍入误差(rounding errors during warping)
遮挡暴露问题
一句话:当前视点不可见的信息在另一视点将会变的可见

舍入误差问题

空洞填算法
Inpainting是虚拟视点合成的最难的模块。大部分的论文算法都十分酷炫。主要分为这么几种:
- 基于中值的Inpainting方法
- 基于背景的Inpainting方法
- 基于超分辨的Inpainting算法
- 基于公式的Inpainting算法
- Criminisi inpainting类算法
- 基于马尔科夫随机场(MRF)的Inpainting方法
具体的算法就不进行展开了,很多算法都比较复杂,不是一两句能够说明白的。
5. 参考源码
-
最新版本以及支持360视频的虚拟视点合成。















 4516
4516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









