









文章目录
前言
本文记录笔者对堆的学习和相关心路历程
一、堆数据结构概念复习
在整理堆相关算法题前,我们先对堆相关知识点进行复习整理,
关于数据结构中的堆,我们可以对其作如下理解
堆 (Heap) 通常以二叉堆的形式出现,是一个可以被看做一棵完全二叉树的数组对象。
完全二叉树的相关概念笔者在这里就不进行赘述了,如果这方面还不清楚的读者可以搜索资料进行阅读
相关二叉堆图示如下
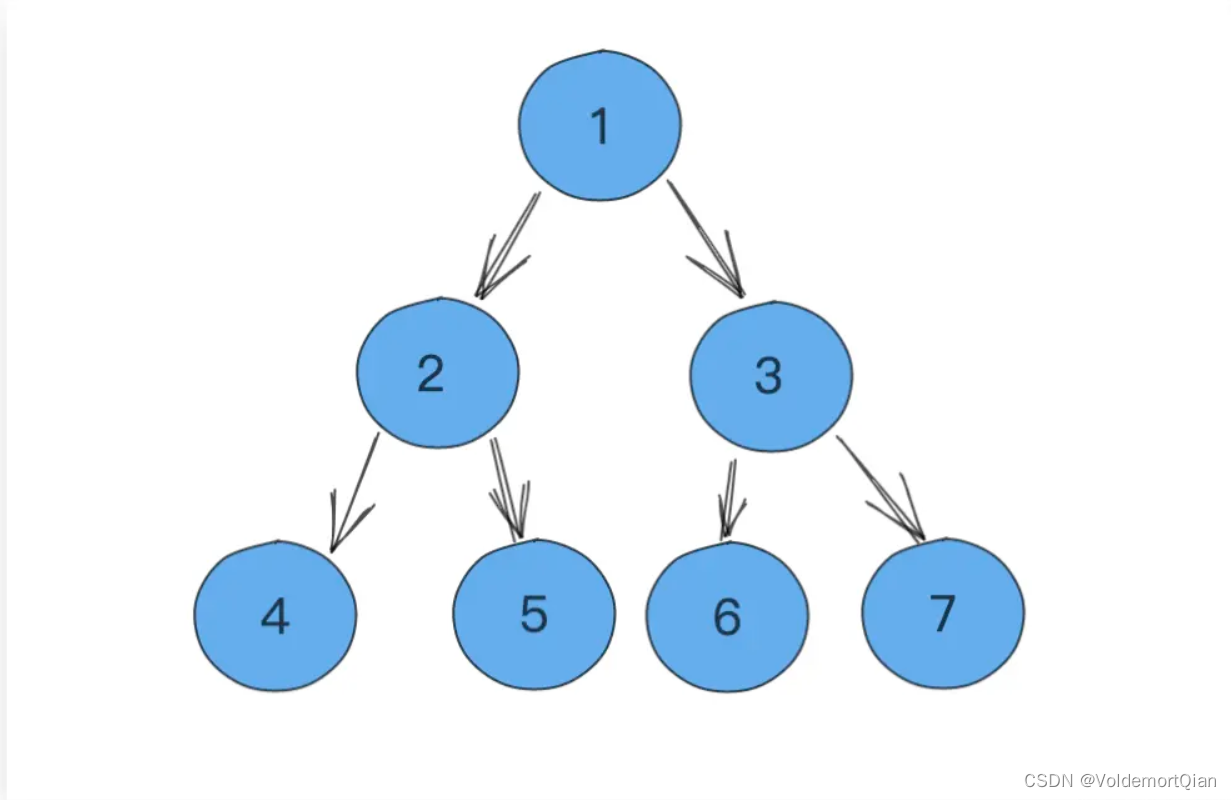
堆与二叉树相似的地方在于他们的结构,但不同之处在于,二叉树的大小关系更在于其父节点和子节点的大小关系比较,但是堆的大小关系比较更在于其上层节点与下层的节点的比较,即下一层任意节点永远比上一层节点更大,同时以整体节点大小从上往下为递增或是递减关系分为小顶堆和大顶堆
- 小顶堆,从上往下每层节点递增,堆顶最小
- 大顶堆,从上往下每层节点递减,堆顶最大
二、堆数据结构
堆的push与pop
push
堆的push并不是直接将节点加入到堆的对应位置上,而是先将插入节点放在堆底,通过动态调整让其上浮,最终将节点放在它该对应的位置上
堆的push过程具体可参考下方图片
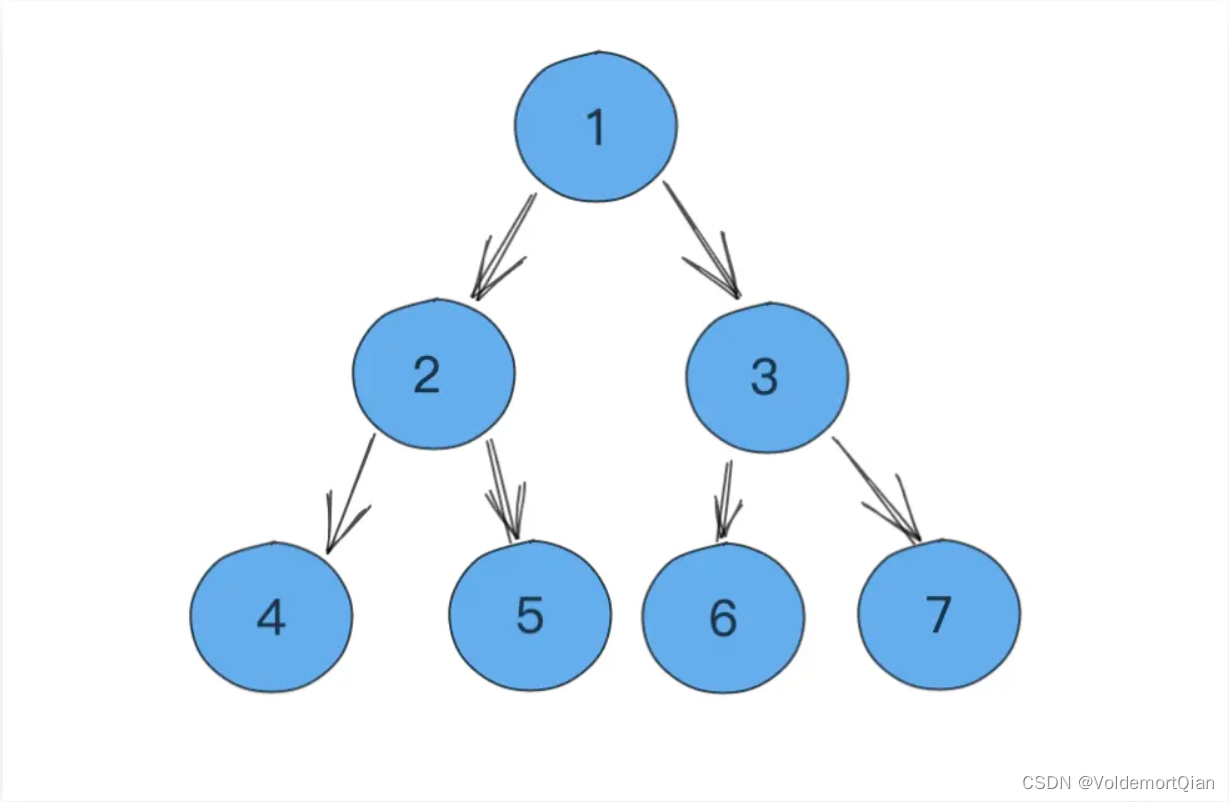
原二叉树图
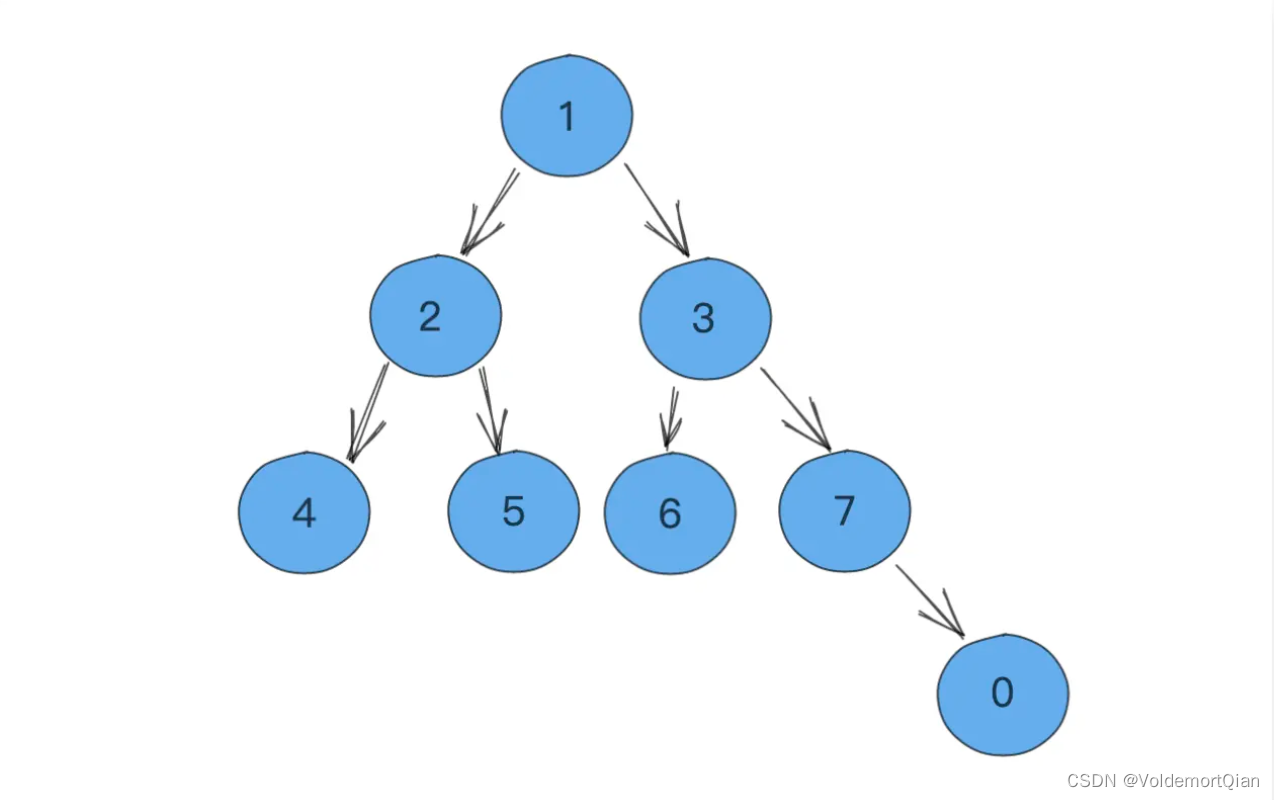
插入了新元素后,新元素后从堆底开始上浮(每次与其上一层的节点进行比较,若小于,则进行上浮)
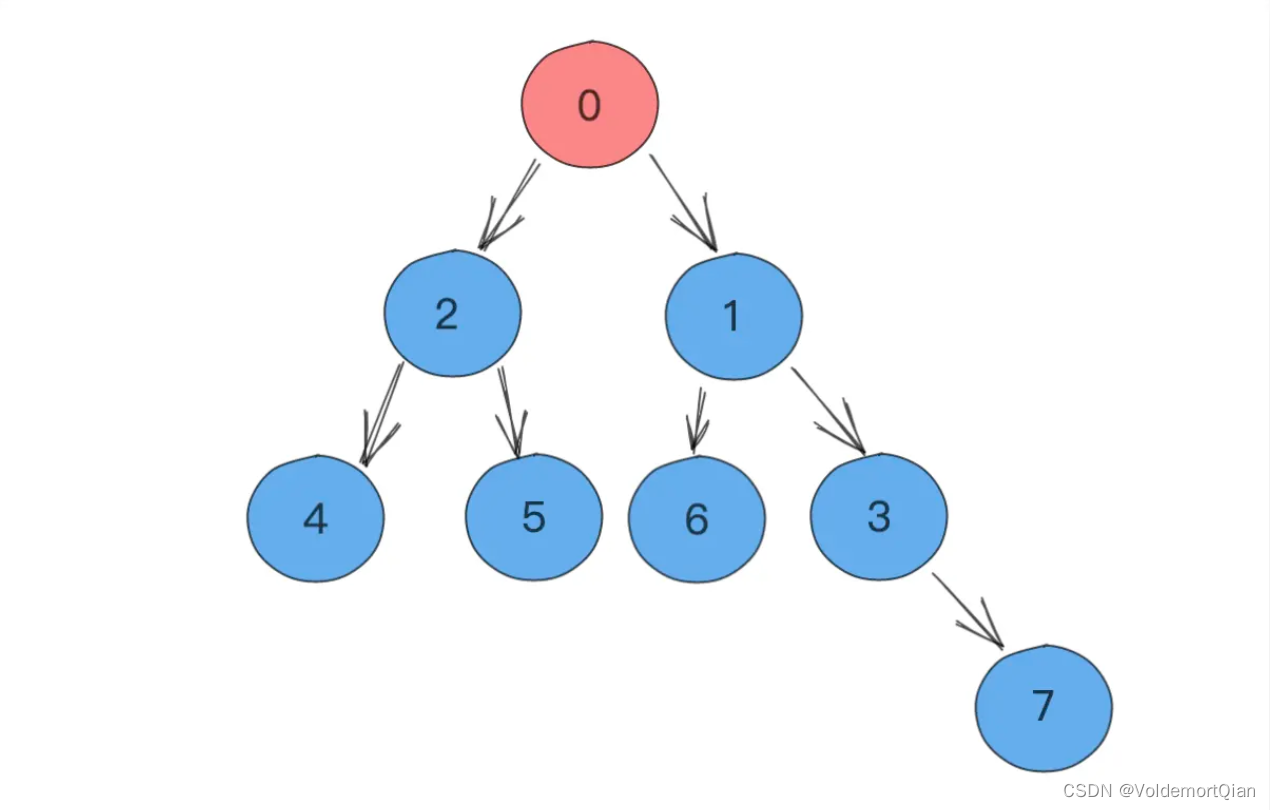
一直上移,直到其位于堆顶或不能再上移为止
pop
堆的pop会将堆顶元素进行弹出,而后从堆底元素挑出一个放在堆顶,再通过动态调整让其下浮,最终该节点会放在它该存放的位置上
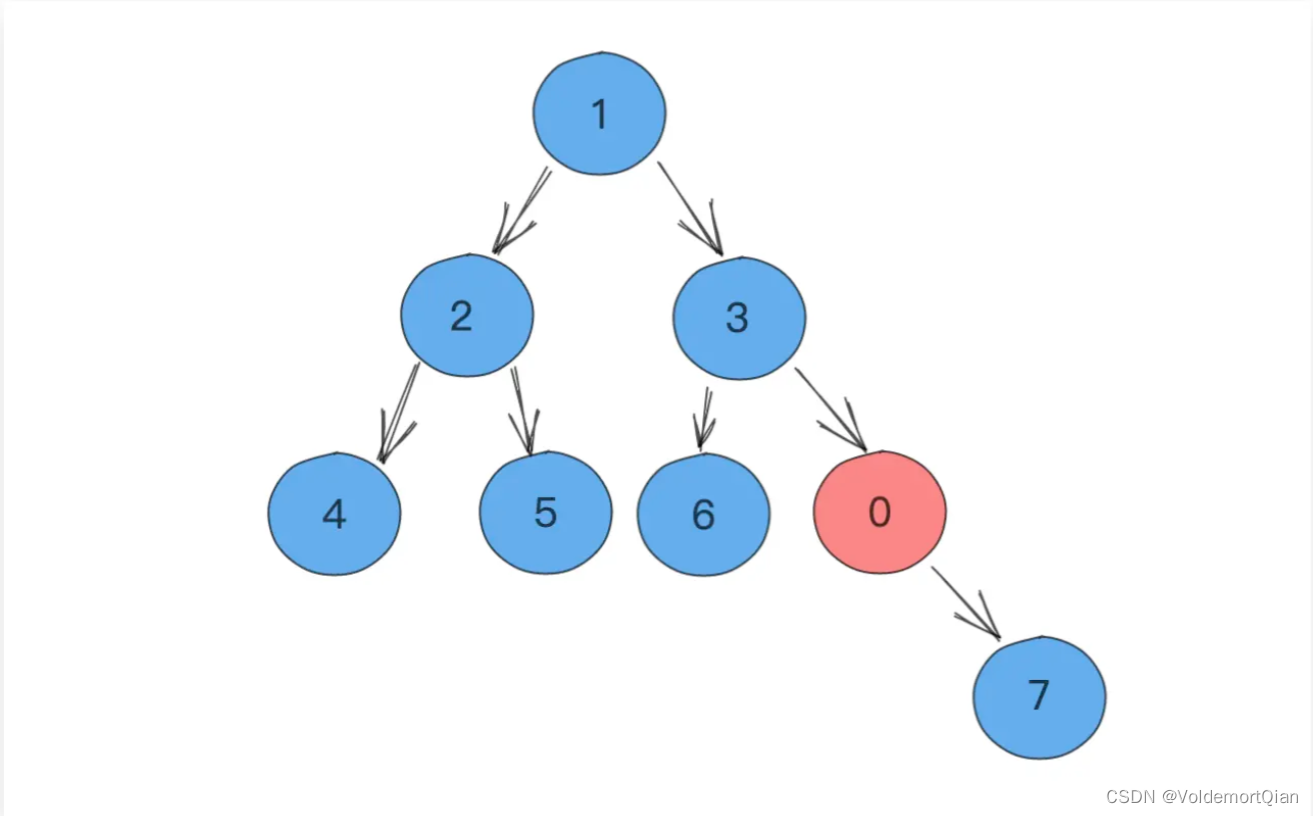
具体形象过程可查看以下图片
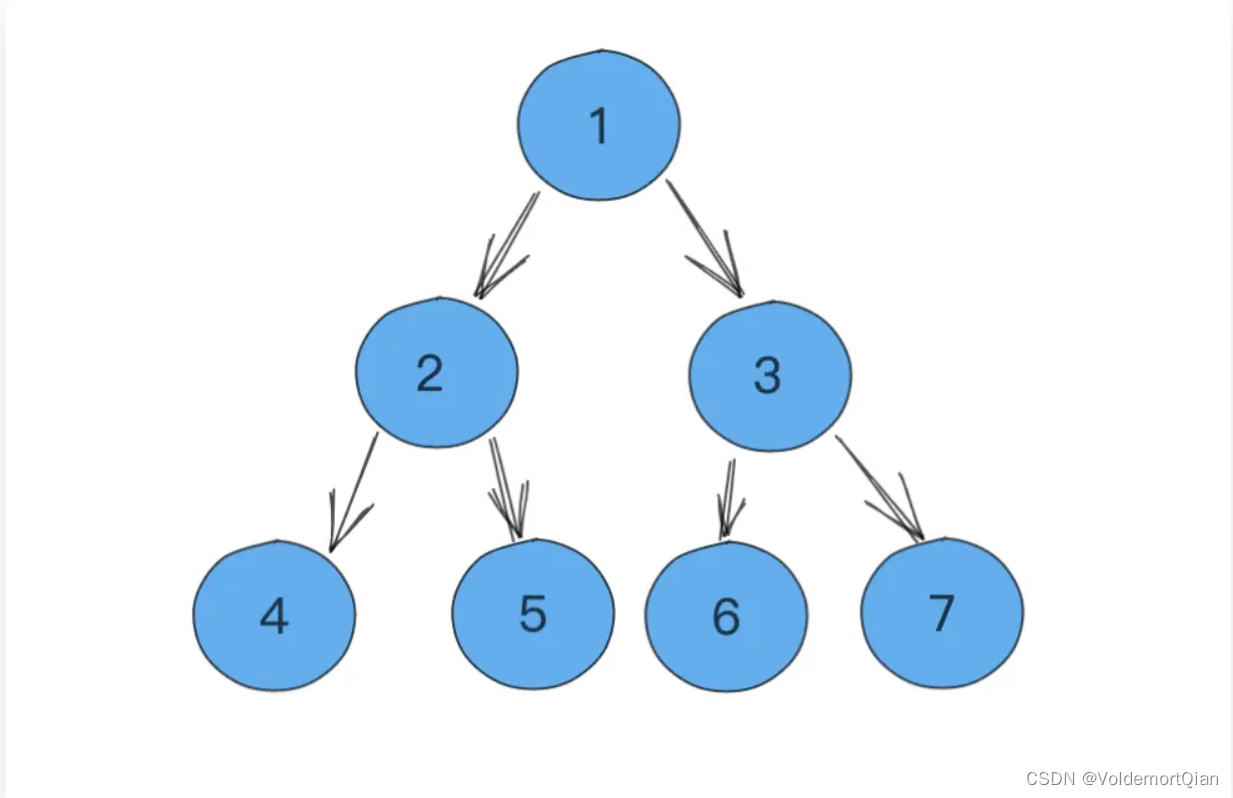
堆原图,现在将堆顶元素1进行pop操作
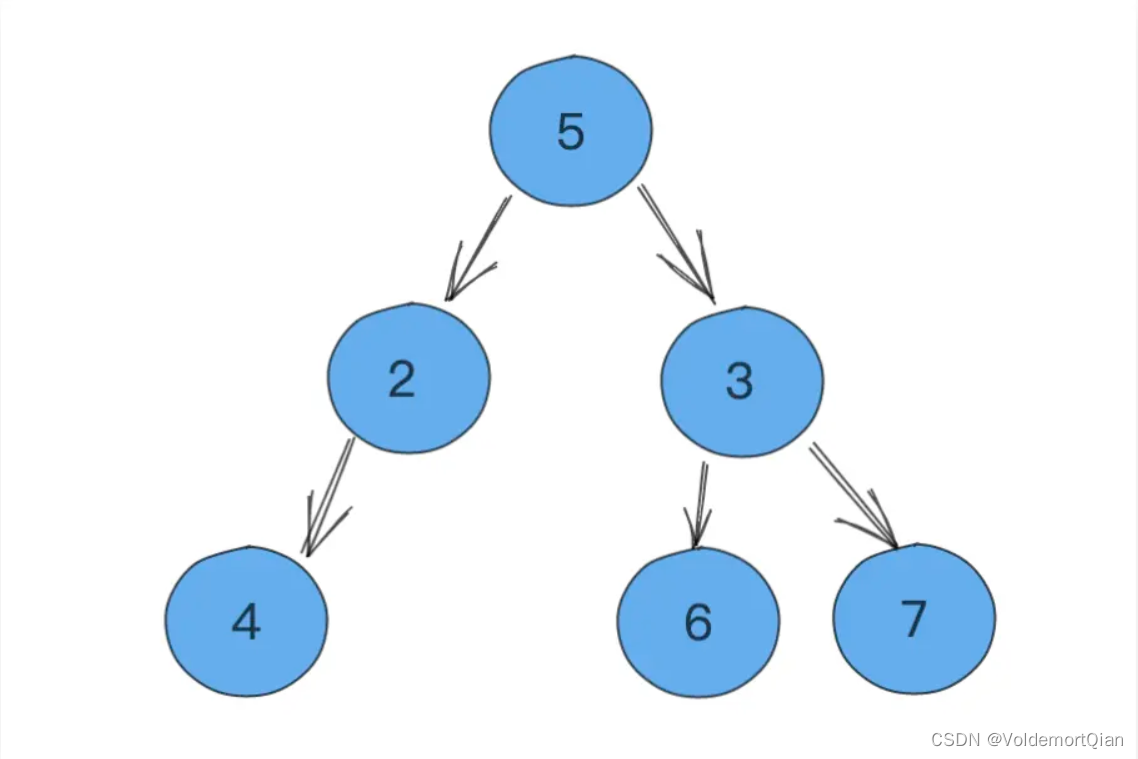
pop堆顶元素1后,从堆顶拿到元素5,并放置在堆顶元素的位置上
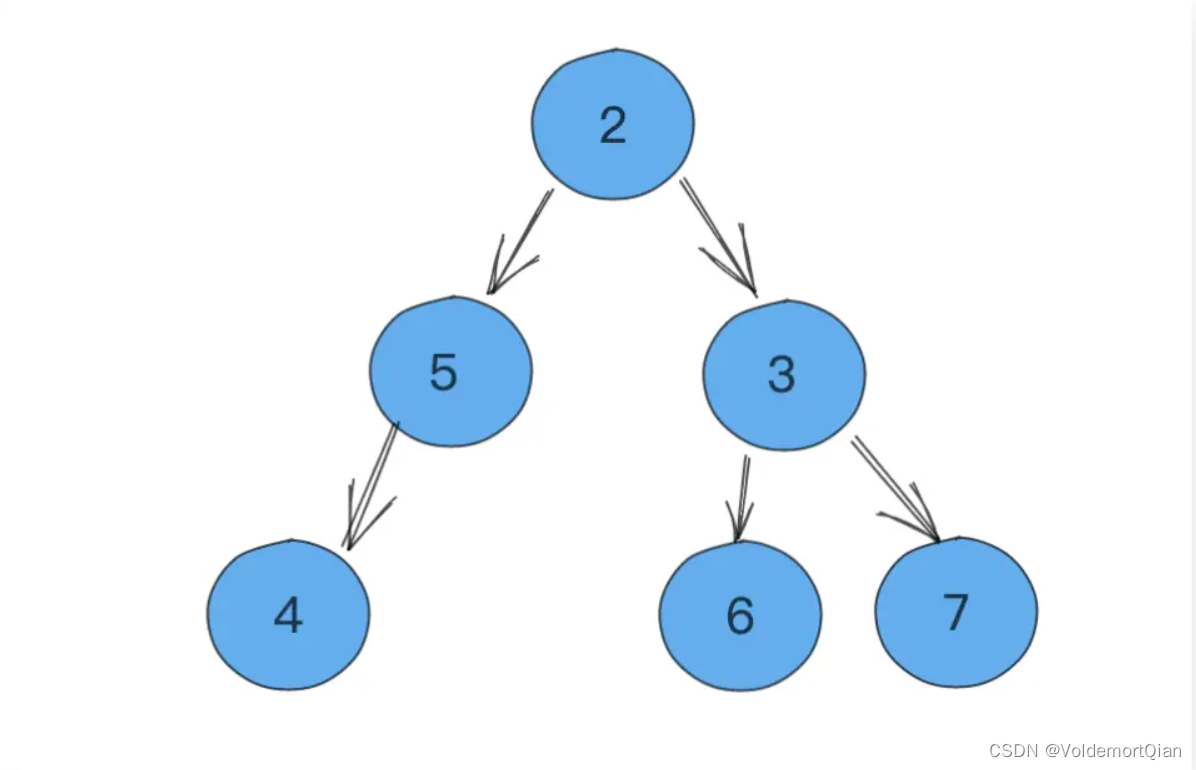
不断与其子节点比较并进行下浮操作,例如这里将5与2进行了交换
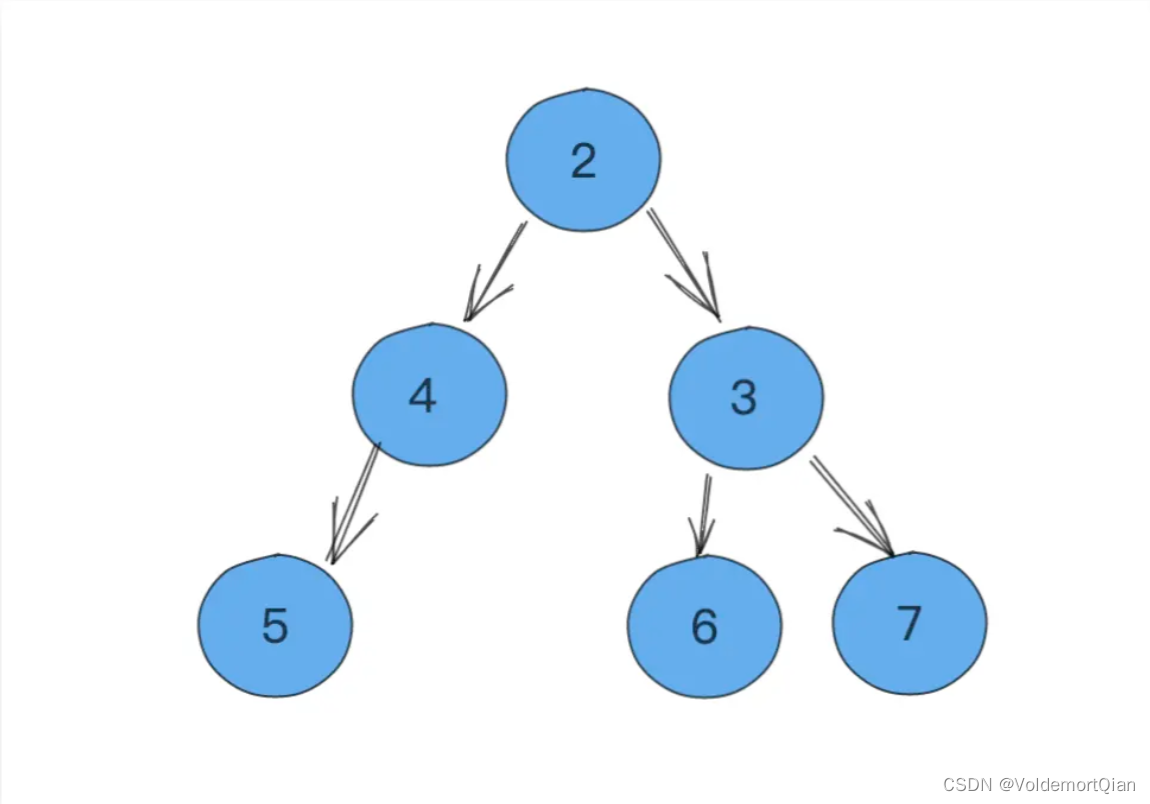
继续与4进行交换,最终完成小顶堆的样子
手写堆
下面我们用代码来呈现手写建立堆的过程
这里我们所说的堆以二叉堆进行理解
二叉堆的数据结构可以用一维数组来进行展现,我们从数组下标的角度进行理解,如果采用数组的形式,将一棵完全二叉树存放,父节点在一维数组中下表为n,则其左孩子的下标为2n,右孩子的下标为2n+1,不相信的小伙伴可以进行计算验证一下哦
经过以上的介绍,我们采用数组的形式来手写一个堆解决以上的算法题,相关代码如下
#include<iostream>
#include<algorithm>
using namespace std;
int n,m;
const int N=100010;
int d[N],dSize;
void down(int u){
int t=u;
if(u*2<=dSize &&d[t]>d[u*2]) t=u*2;
if((u*2+1)<=dSize &&d[t]>d[u*2+1]) t=u*2+1;
if (u != t)
{
swap(d[u], d[t]);
down(t);
}
}//最小堆的下降
int main(){
cin>>n>>m;
for (int i=1;i<=n;i++){
cin>>d[i];
}
dSize=n;
for (int i = n / 2; i; i -- ) down(i);
while (m--){
//去除最小数
cout<<d[1]<<" ";
d[1]=d[dSize--];
down(1);
}
cout<<endl;
}
三、相关算法题
堆数据结构相关算法题记录
NC119 最小的K个数
求最小的K个数和求最大的K个数都可以通过维护堆的方式来进行完成
- 最小的K个数,维护大顶堆,陆续往里面插入元素,当堆的长度大于K时,弹出堆顶元素,最后得到的,就是K个数组中最小的元素
- 最大的K个数,同理,维护小顶堆
相关代码
class Solution {
public:
vector<int> GetLeastNumbers_Solution(vector<int> input, int k) {
vector<int> res;
priority_queue<int> heap;//大顶堆
for(int i=0;i<input.size();i++){
heap.push(input[i]);
if(heap.size()>k) heap.pop();
}
while(heap.size()){
res.push_back(heap.top());
heap.pop();
}
reverse(res.begin(),res.end());
return res;
}
};
NC88 第K大的数
同理,使用大顶堆的方式进行完成,注意到这题给的参数中有一个总数,当然没给我们也能自己求,利用大顶堆,他要我们求第K大,那我们反向求n-k+1小就行
class Solution {
public:
int findKth(vector<int> a, int n, int K) {
priority_queue<int> heap;//大顶堆
for(int i=0;i<a.size();i++){
heap.push(a[i]);
if(heap.size()>n-K+1) heap.pop();
}
int result=heap.top();
return result;
}
};
当然这道题,其实时间复杂度最低的方法应是快排优化,每次快排分治K所在的那一侧即可
class Solution {
public:
vector<int> q;
int findKth(vector<int> a, int n, int K) {
q=a;
return quick_sort(0,n-1,n-K+1);
}
int quick_sort(int l,int r, int k){
if(l>=r) return q[l];
int x=q[l+r>>1],i=l-1,j=r+1;
while(i<j){
while(q[++i]<x);
while(q[--j]>x);
if(i<j) swap(q[i],q[j]);
}
int s1=j-l+1;
if(s1>=k) return quick_sort(l,j,k);
return quick_sort(j+1,r,k-s1);
}
};
NC131 数据流中的中位数
这题要求出一堆插入数中的中位数,我们当然可以选择一个vector数组来进行存储,每次插入O(1)的时间复杂度,每次取出来O(nlogn)的时间复杂度来实现,但那样是暴力的解法
我们更好的做法是,维护两个堆,利用分治的思想来解决这个问题
具体做法如下:
中位数是指:有序数组中中间的那个数。则根据中位数可以把数组分为如下三段: [0 … median - 1], [median],
[median … arr.size() - 1],即[中位数的左边,中位数,中位数的右边]那么,如果我有个数据结构保留[0…median-1]的数据,并且可以O(1)时间取出最大值,即arr[0…median-1]中的最大值
相对应的,如果我有个数据结构可以保留[median + 1 … arr.size() - 1] 的数据,并且可以O(1)时间取出最小值,即 arr[median + 1 … arr.size() - 1] 中的最小值。然后,我们把[median]即中位数,随便放到哪个都可以。假设[0 … median - 1]的长度为l_len, [median + 1 … arr.sise() - 1]的长度为r_len.
- 如果l_len == r_len + 1, 说明,中位数是左边数据结构的最大值
- 如果l_len + 1 == r_len, 说明,中位数是右边数据结构的最小值
- 如果l_len == r_len, 说明,中位数是左边数据结构的最大值与右边数据结构的最小值的平均值。
代码如下(示例):
class Solution {
public:
priority_queue<int> min_q;//大顶堆
priority_queue<int,vector<int>, greater<int>> max_q;//小顶堆
void Insert(int num) {
min_q.push(num);//把数字加入到大顶堆
max_q.push(min_q.top());
min_q.pop();//将大顶堆堆顶转移到小顶堆;这个过程保证了大顶堆的所有数都小于小顶堆的堆顶
if(min_q.size()<max_q.size()){
min_q.push(max_q.top());
max_q.pop();//平衡两个堆
}
}
double GetMedian() {
return min_q.size()>max_q.size()?min_q.top()/1.0:(min_q.top()+max_q.top())/2.0;
}
};


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









