









 本文探讨了熵在自然语言处理中的应用,包括其基本概念、公式解析及实际案例。通过对熵值的理解,作者介绍了如何利用熵评估词汇的重要性,并讨论了最大熵模型的基本原理。
本文探讨了熵在自然语言处理中的应用,包括其基本概念、公式解析及实际案例。通过对熵值的理解,作者介绍了如何利用熵评估词汇的重要性,并讨论了最大熵模型的基本原理。
熵的应用(一)——工作学习中的一点体会
最近在做一个广告重点词的项目,用到了最大熵做特征,感觉这个概念经常被用到,比如最大熵隐马,条件随机场,都有涉及,这里总结一下。
目录:
一、含义
二、公式
三、公式理解
四、小应用
五、最大熵模型
一、 含义
熵是一个算法经常用到的概念,通俗来说就是越平均熵越大,并且这个世界里的东西一定是趋向于熵最大。比如冰火在一起,一定是趋于平均温度。有钱人和没钱人在一起?为什么不是趋于共产主义!!!好吧扯远了~~
二、 熵值公式:
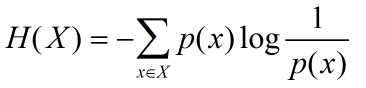
三、 公式理解:
就拿刚刚冰火的列子:
1、极端情况百分百的冰或者火,于是概率p(x)=1/0,取1的时候log(1/1)为0, 取0的时候p(x)是log(1/p(x))部分的高阶无穷小,所以还是0。综合H(x)为0
2、均匀分布的时候,p(x)=50%,最后结果为H(x)=-0.5*log(0.5)+( -0.5*log(0.5)),怎么算都比0大
3、在冰火极端情况和均衡情况之间分布,这个大家可以随便取个值计算,肯定在0~ H(x)之间
所以我们发现均衡分布熵值最大,同时我们也发现如果没有约束,事物总是向熵最大靠近,比较冰火就会趋于温度综和
四、 小应用
来个小应用吧,在一个句子什么词最重要,我们发现分布越均衡,也就是跟着的词越平均,则这个词越不重要。
比如“手机”,左右熵都很高

熵值归一化:
这里我们发现个问题,出现次数越多的词信息熵越大,比如都是均衡分布出现3次H(x)=log3,出现5次则为log5,我们需要对熵值进行归一化,归一化的方法为除以理论最大值log(N),N为出现的种类改进后的公式为
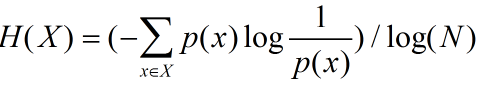
问题2:还有个问题是首尾的词因为接的词少,也会造成熵比较大,需要专门处理,大家有兴趣可以试验一下怎么处理比较好
五、 最大熵模型
一般来说我们常见的算法模型都是需要求一个熵值的最值,为啥要求最值呢,这个是非线性规划中的条件,求个极值,
非线性规划:
http://blog.csdn.net/qjzcy/article/details/51727741
最大熵的算法模型和条件随机场差不多,这里偷个懒就不写了,贴个条件随机场的吧
http://blog.csdn.net/qjzcy/article/details/51728194


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









