










我们的工作中经常遇到如何求两个句子的相似,比如如何判断搜索query和广告query的相似,搜索query和app的相似,再比如短文本相似的问答系统等等。有什么好的方法呢,这里是个人的一点总结吧。
目录:
一、 先贴结果
二、 短文本相似常用的方法
三、主题模型的应用
四、 深度学习的模型搭建
(一)老样子先贴结果吧,样本是处理后的搜索query和广告点击query,准确率在95%左右
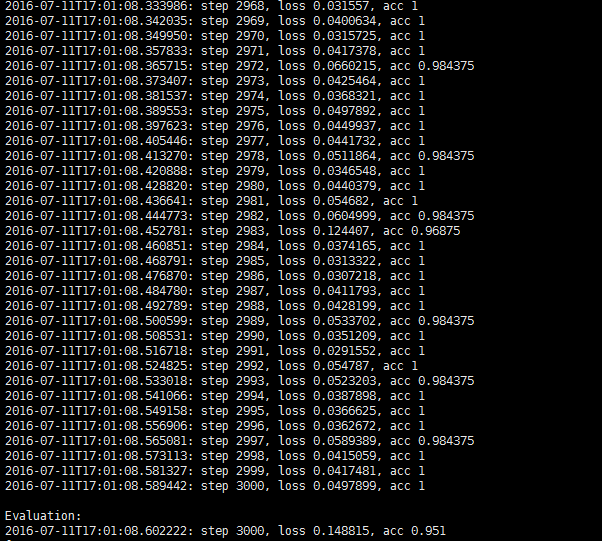
图2的格式为标签(相似为1,不相似为0)、 预测标签、 某个值(大于0为预测标签为1)、 搜索query @ 广告query

(二)我们常用的方法:语义相关app搜索(二) 论短文本相似——qjzcy的博客
1、 Session相关法
2、 句子向量法 :对一个句子生成向量空间模型(比如用tfidf作为权重),用距离公式(比如余弦)求距离
3、 多级的跳转法
4、 算法模型法:比如主题模型和比较火的word2vector模型
(三)主题模型的应用
到里主题模型这里,我们其实有个问题主题模型怎么用?拿word2vector模型来说,它提供每个词的向量,用这个向量可以很好的计算两个词之间的相似度,可是一个句子中有好几个词怎么,怎么计算呢?
几个方法:
1、 把每个词的向量叠加,这个方法有些粗暴,但是简单易行。
2、 第一种方法可行的话,很容易想到如果我们能找到句子中的重点词,给它加权效果是不是更好,但是重点词怎么来,又是一个问题(tfidf显然不是最优,安利一个我做的重点词方法:http://blog.csdn.net/qjzcy/article/details/51737059)。
3、 把向量直接串起来变成一个长向量,这个方法没实验,但是想想就有好多问题,或者偷懒的说这么简单的方法都没听说人用肯定效果不好^_^。
4、 如果句子本身的词可以组成一个1维的空间向量,每个词的主题又有一个维度的向量。很自然我们可以想到可以用卷积来解决这个问题
(四) 深度学习的模型搭建
问题:既然我们想用深度学习的模型,那么怎么让模型识别我们的初始数据?
我们可以这样:
1、 每个句子分别卷积成生成一个向量,利用这个向量再求距离
比如微软的这个模型

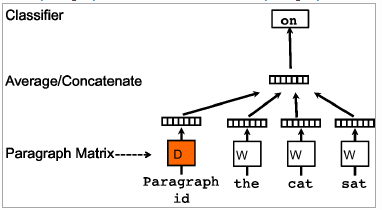
2、把句子也作为一个特征加到词组里一起训练
比如这个论文沿用了word2vector的思路:
Distributed Representations of Sentences and Documents
3、 我这么做:把两个句子拼接成一个句子,用标识隔开,这样形成一个2D结构的数据作为输入,用cnn训练
我更喜欢这种方法,因为这样数据结构更加简单,可以让我们专心的把注意力集中在模型其他结构方面。
问题解决了,我们放到模型里跑一下,duang!几乎没做什么模型上的优化就能有93%左右的准确率,果然对深度学习还是要有一些迷信才好。
另外一种LSTM的尝试:
利用lstm模型实现短文本主题相似——qjzcy的博客

















 4593
4593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









