






点击蓝字,关注我们

不积跬步无以至千里
当我们拿到一个数据的时候,脑海里最先浮现的想法是:
-
这是一个什么样的数据? 我能从这个数据里获取什么样的信息?
-
这个数据有多大?也就是我们所说的这个数据多少行多少列?
-
这个数据都有哪些列?列名规范吗?如果不规范如何修改?
-
这些列分别是什么格式,什么类型的数据? 分类变量?还是数值型变量?
-
_数据的unique ID是什么?有没有缺失值?有没有重复?
_ -
其他列有没有缺失值?缺失值对后面的分析有没有影响?
在了解这些问题之前,让我们先把数据读入。
本文数据源自Kaggle,仅以此作为练习。
- 首先导入数据处理的包,Python中常用的数据处理包为Pandas,基本可以解决所有数据处理的问题, 包括数据运算,数据清洗,增删改查,数据加工,画图等;
import pandas
- 读入文件
df = pd.read_csv('../data.csv',sep=',')
sep参数用于分割字段的字符,默认为逗号(,),除此之外还有分号(;)、制表符(\t),当数据中有空格、制表符、换页符或者空白字符时可以用(\s)。
- 数据读进去之后查看数据;head(n) 查看前n行, tail(n) 查看后n行,默认返回5行。如果直接查看表,则返回前5行和后5行,中间用…代替。
df

df.head()
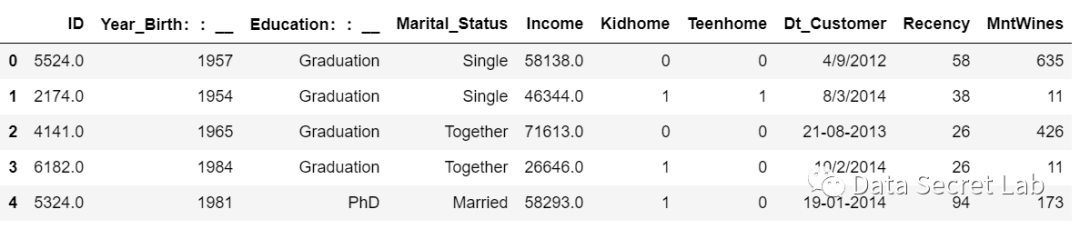
df.tail()

- 查看数据的基本信息, 有多少列,列名,有多少非空值,数据格式
df.info()
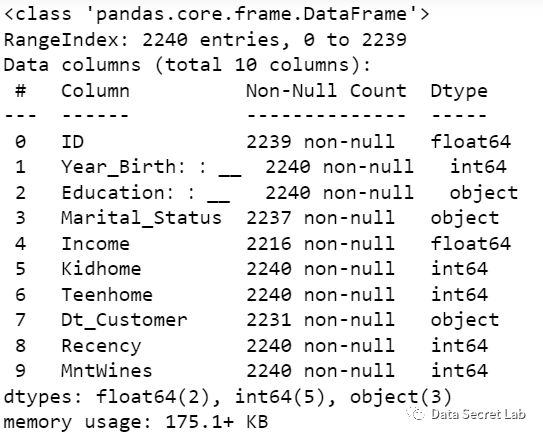
#此数据为2240x10的数据框,第一列为列index, 第二列为列名,第三列为每列中不为空数据的个数,第四列为数据类型
#数据类型:2个浮点型,6个整型,3个分类变量
- 我们发现有两列列名中有特殊符号,为了后期数据处理方便,我们将特殊符号去掉或者对列重命名
df = df.rename(columns={'Year_Birth::__':'Year_Birth','Education::__':'Education'})``df.columns

- 数据中的uniqueID为ID列,作为关键key,我们来检查下有没有空值以及空值的个数
pd.isnull(df['ID'])
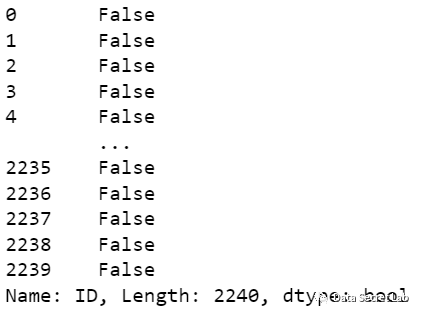
- 后续我们有可能会做不同表之间的关联,需要确保ID为unique
print(len(df['ID']))``print(len(df['ID'].unique()))

ID共2240个,unique值也为2240,ID为unique
- 检查ID有没有空
pd.isnull(df['ID']).sum()

- 除此之外,我们再看其他列是否也有空值
df.isnull().sum()

- 看分类变量中有哪些类别
df['Education'].value_counts()

到此,我们对数据有了大致的了解和认识,发现数据中还有些问题待处理,在下一节,我们继续来介绍数据分析中常用的一些函数和功能。
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
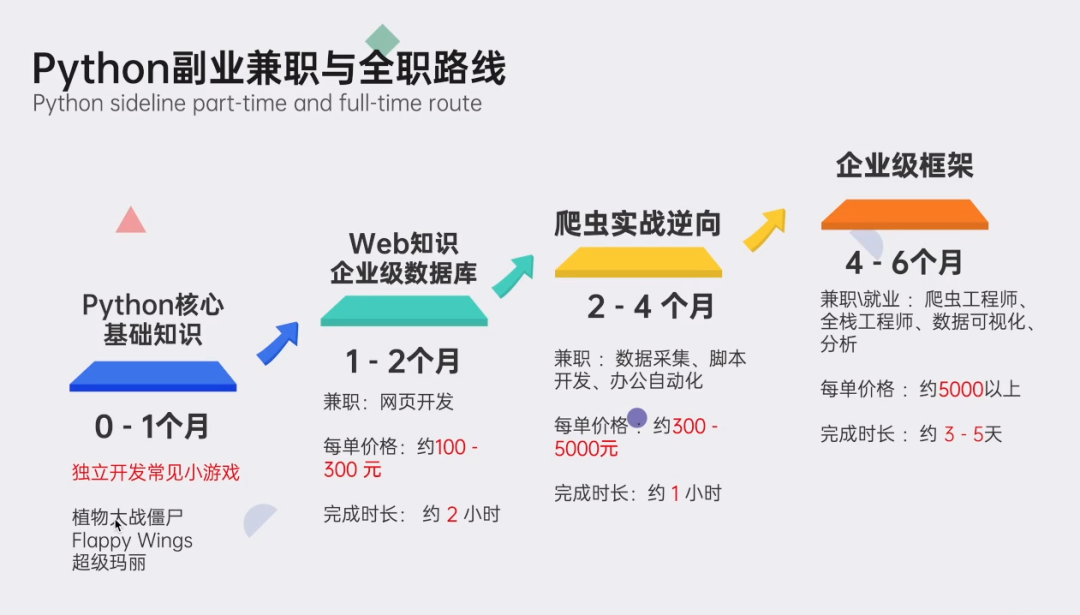
👉Python副业创收路线👈
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









