






一、概述
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型:ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中优秀的性能。
- 更完整的功能支持:ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在登记后亦允许免费商业使用。
二、前期准备
创建阿里云账户
准备数据集:网络搜索,魔搭社区,阿里云平台寻找
模型下载,配置:魔搭社区、阿里云平台
三、模型部署
(1)魔搭社区
1、git GLM3仓库
git clone https://github.com/THUDM/ChatGLM3打开文件
cd ChatGLM32、pip安装依赖
pip install -r requirements.txt3、git模型到本地
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git4、修改变量路径
打开chatglm3-6b的comfig.json文件,修改为chatglm3-6b当前文件所在的地址。
5、克隆OpenVINO GLM3推理仓库并安装依赖
git clone https://github.com/OpenVINO-dev-contest/chatglm3.openvino.git
cd chatglm3.openvino按照以下代码安装依赖
python3 -m venv openvino_env
source openvino_env/bin/activate
python3 -m pip install --upgrade pip
pip install wheel setuptools
pip install -r requirements.txt6、转换模型
python3 convert.py --model_id THUDM/chatglm3-6b --output {your_path}/chatglm3-6bTHUDM/chatglm3-6b为模型所在目录的绝对路径,{you_path}/chatglm3-6b为转换后的模型保存的地址。
7、运行模型
python3 chat.py --model_path {your_path}/chatglm3-6b --max_sequence_length 4096 --
device CPU{your_path}/插头glm-b为转换后的模型目录的位置。
8、openvino技术介绍
OpenVINO(Open Visual Inference & Neural Network Optimization)是由英特尔开发的一种端到端的深度学习推理神经网络的开源工具包。它提供了一种高效的方式来优化和部署深度学习模型,并且支持多种硬件平台。
OpenVINO的工作流程如下:首先,通过模型优化工具对深度学习模型进行剪枝、量化和融合等操作,以减小模型的大小和计算量。然后,使用型转换工具将优化后的模型转换为IR格式。接下来,选择目标硬件平台,并安装相应的驱动程序和加速库。然后,通过OpenVINO的推理引擎加载IR格式的模型,并在硬件上进行推理。最后,获取推理结果并进行后续处理,如结果可视化或其他业务逻辑。
总结来说,OpenVINO是一种高效的端到端深度学习推理神经网络的开源工具包,它通过模型优化、转换和硬件加速来实现高性能的推理。利用OpenVINO,可以将深度学习模型优化为较小的计算量并转换为推理阶段的格式,然后利用硬件的性能和优化算法来高效地运行推理过程。通过OpenVINO,开发者可以更方便地部署和优化深度学习模型,实现实时和高效的推理应用。
9、openvino部署前后对比
部署前:


在魔搭平台部署前的相应时间为:“你好”是5分30秒做出完全回答,“介绍中南大学”和“介绍周杰伦”都是使用50多分钟做出完全回答。
部署后:



在魔搭平台部署了openvino后,模型对问题的相应速度明显加快:
“你好”的回答为13秒;“介绍中南大学”的回答时间为1分50秒,“介绍周杰伦”的回答时间为1分53秒。
经过我们的测试表明,在不同的平台上部署openvino,模型回答问题的时间也会有差异,在阿里云平台上的回答速度会明显快于魔搭平台。
(2)阿里云平台
1、git GLM3仓库
在我的操作中使用的是阿里云的人工智能平台API,已经默认帮我们配置好了环境、网络,所以在操作中我们无需进行环境配置,可以直接下载模型文件。
git clone https://github.com/THUDM/ChatGLM32、进入仓库目录
cd ChatGLM3 (可以使用pwd指令查看当前所在目录,在后续实验操作中对于所在目录存在要求,使用pwd可以帮助判断)
3、安装依赖
pip install -r requirements.txt4、下载本地模型
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git5、修改变量路径
6、部署运行
python basic_demo/cli_demo.py四、微调(需要在finetune_demo文件下打开一个终端,可以使用前文提到的pwd进行查看,使用cd+文件名进行跳转)
1、pip安装依赖
pip install -r requirements.txt如果无法一次性全部安装(安装过程中出现error),则需要通过pip install指令按照requirements.txt文件中列出的依赖一个个安装。
安装完成后可以使用pip list并与requtrements.txt中列出文件进行对比,确保全部安装。
2、准备数据集
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"},
{"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘
逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿
到夏天也很舒适。"}]}3、模型微调
python finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml微调前可以根据寻找到的数据集的情况对部分参数进行更改

在微调过程中会出现很多报错,报错后会出现如下界面。
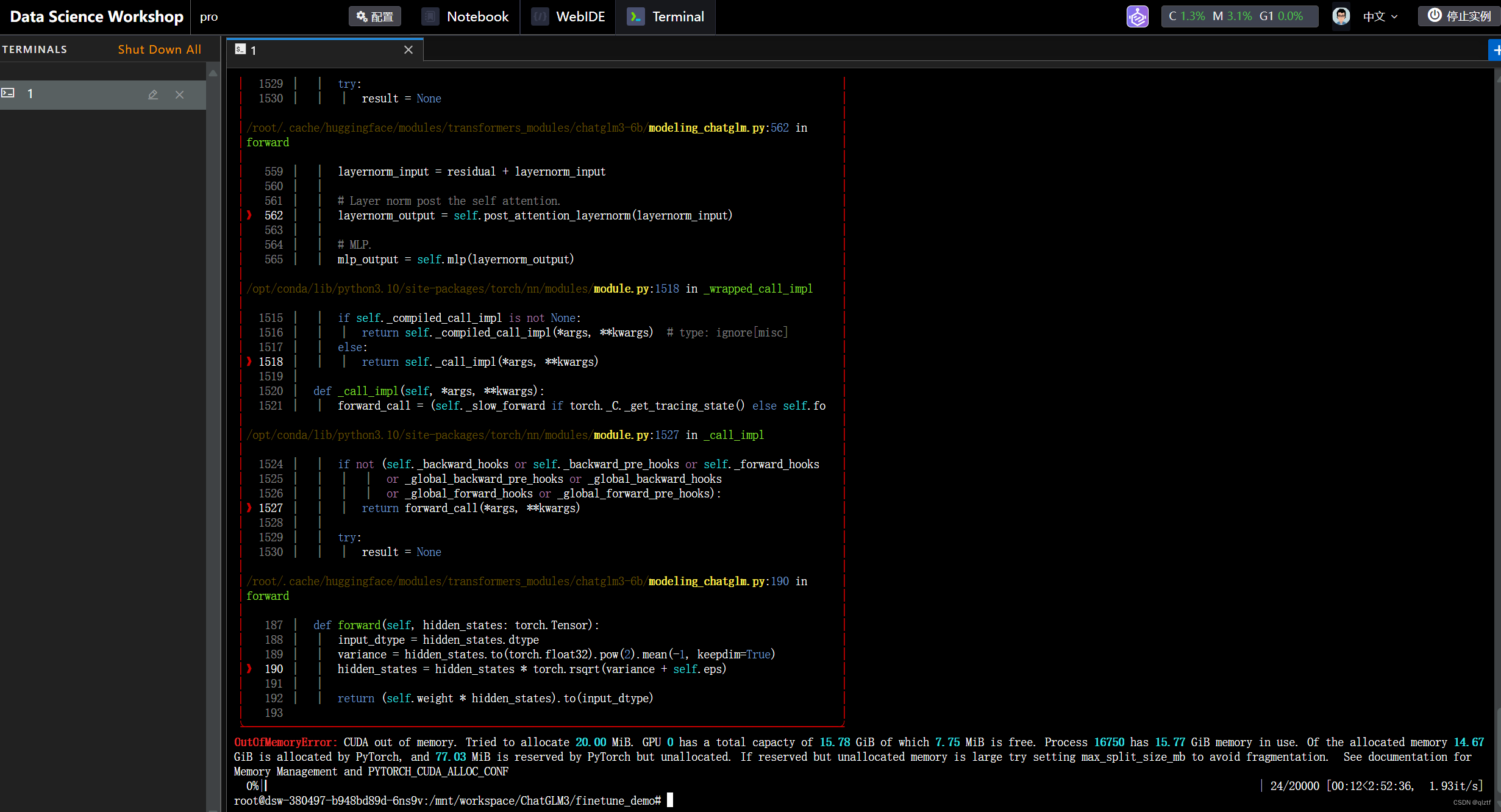
以下是我在微调过程中遇到的报错信息:
in 关键字来检查一个键是否存在于一个字典中。通过添加这个检查,可以避免在字典中不存在键时发生 KeyError。
微调过程中可能会出现如下提示:
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results这些指令是关于使用Weights & Biases(W&B)的工具进行结果可视化的。
如果选择选项(1),将会创建一个新的W&B账户。
选择选项(2)将会使用现有的W&B账户。
而选择选项(3)表示不将结果进行可视化展示。
这里建议选择选项3,选择选项3则不用进行其余操作。
微调成功进行时会出现如下界面
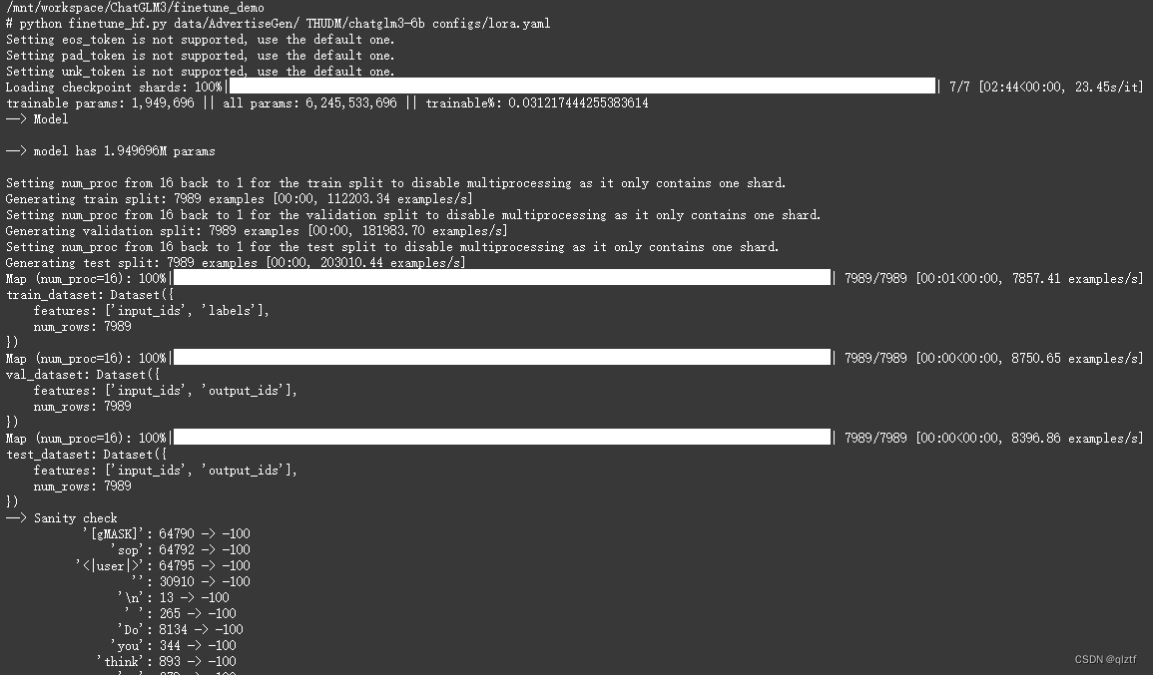

出现以上画面则代表已经正常进行微调,只需等待其微调完成即可。
下图为训练结束后根据训练情况画出的loss图:
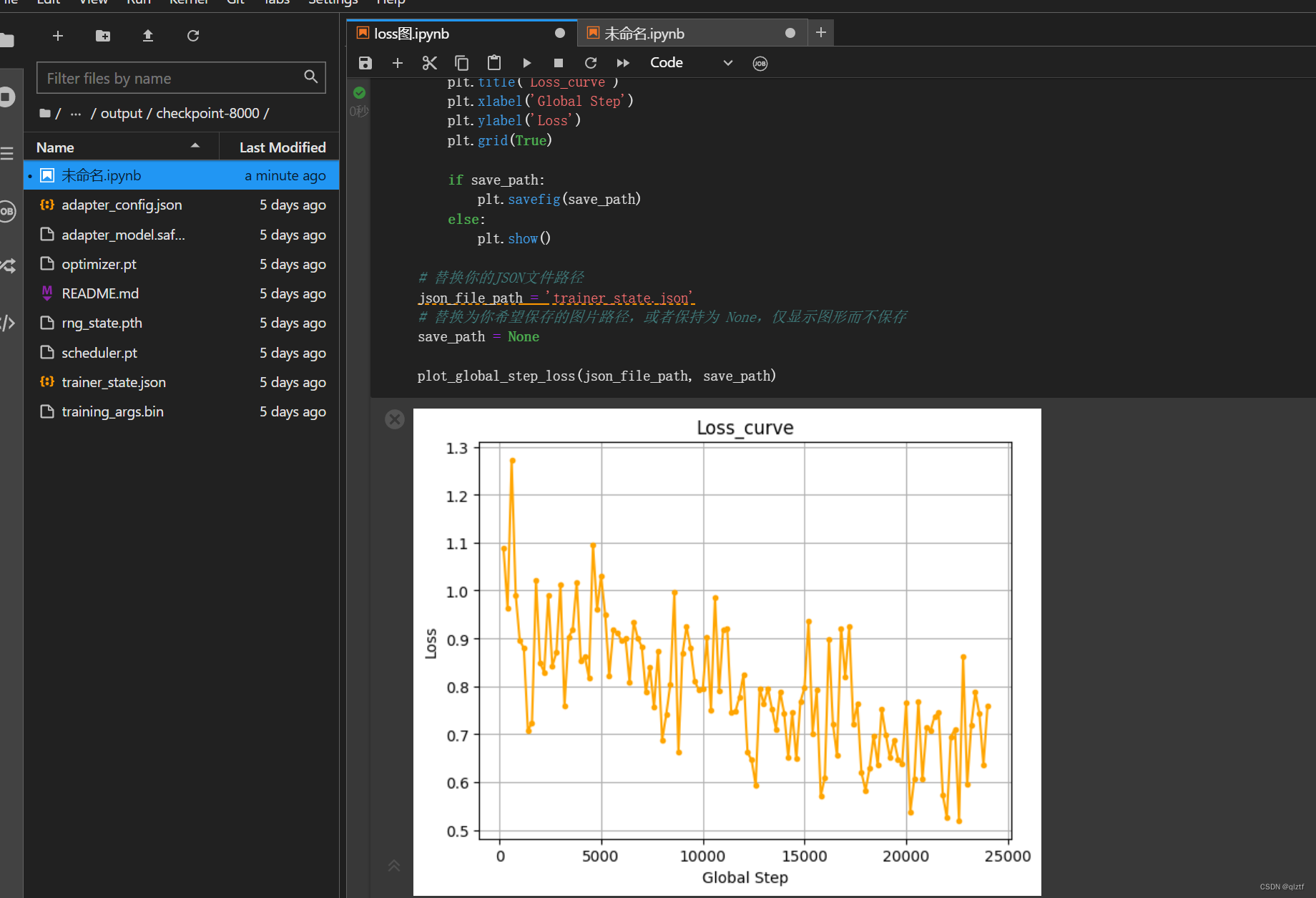
4、训练完成模型测试
在finetune_demo文件下打开终端输入以下代码:
python inference_hf.py your_finetune_path --prompt your prompt5、训练后模型与训练前模型问答对比
训练前:

训练后:

五、UI界面的实现
打开ChatGLM3文件夹下basic_demo文件夹中的web_demo_gradio.py,进行以下修改:

将如图第69行代码注释掉,增加第70、71行代码:
finetune_path= '/mnt/workspace/ChatGLM3/finetune_demo/output/checkpoint-3000'
model, tokenizer = load_model_and_tokenizer(finetune_path)
其中红色部分为最后一次保存的微调模型文件的绝对路径
同时在微调后的模型文件内的adapter_config.json文件的路径也需要进行相应的修改

之后运行web_demo_gradio.py文件即可
cd ChatGLM3
python basic_demo/web_demo_gradio.py
点击链接即可进入交互页面

运行后的结果


使用UI界面后可以更加直观的显示用户的问题以及模型的回答,更为符合人们的使用习惯。















 6632
6632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









