










A. A and B and Chess
A and B are preparing themselves for programming contests.
To train their logical thinking and solve problems better, A and B decided to play chess. During the game A wondered whose position is now stronger.
For each chess piece we know its weight:
the queen’s weight is 9,
the rook’s weight is 5,
the bishop’s weight is 3,
the knight’s weight is 3,
the pawn’s weight is 1,
the king’s weight isn’t considered in evaluating position.
The player’s weight equals to the sum of weights of all his pieces on the board.
As A doesn’t like counting, he asked you to help him determine which player has the larger position weight.
Input
The input contains eight lines, eight characters each — the board’s description.
The white pieces on the board are marked with uppercase letters, the black pieces are marked with lowercase letters.
The white pieces are denoted as follows: the queen is represented is ‘Q’, the rook — as ‘R’, the bishop — as’B’, the knight — as ‘N’, the pawn — as ‘P’, the king — as ‘K’.
The black pieces are denoted as ‘q’, ‘r’, ‘b’, ‘n’, ‘p’, ‘k’, respectively.
An empty square of the board is marked as ‘.’ (a dot).
It is not guaranteed that the given chess position can be achieved in a real game. Specifically, there can be an arbitrary (possibly zero) number pieces of each type, the king may be under attack and so on.
Output
Print “White” (without quotes) if the weight of the position of the white pieces is more than the weight of the position of the black pieces, print “Black” if the weight of the black pieces is more than the weight of the white pieces and print “Draw” if the weights of the white and black pieces are equal.
题目大意
给你一个国际象棋的残局,以及每个棋子的权值,问当前黑方棋子权值之和大还是白方棋子权值之和大
题解
打表记录每个字母的权值,然后扫一遍棋盘就可以了,本次比赛中的签到水题。
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#define MAXN 20
using namespace std;
char mp[MAXN][MAXN];
int score[200];
int main()
{
score['Q']=9;
score['R']=5;
score['B']=3;
score['N']=3;
score['P']=1;
score['K']=0;
score['q']=-9;
score['r']=-5;
score['b']=-3;
score['n']=-3;
score['p']=-1;
score['k']=0;
int sum=0;
for(int i=1;i<=8;i++)
scanf("%s",mp[i]+1);
for(int i=1;i<=8;i++)
for(int j=1;j<=8;j++)
sum+=score[mp[i][j]];
if(sum>0) printf("White\n");
else if(sum==0) printf("Draw\n");
else printf("Black\n");
return 0;
}B. A and B and Compilation Errors
A and B are preparing themselves for programming contests.
B loves to debug his code. But before he runs the solution and starts debugging, he has to first compile the code.
Initially, the compiler displayed n compilation errors, each of them is represented as a positive integer. After some effort, B managed to fix some mistake and then another one mistake.
However, despite the fact that B is sure that he corrected the two errors, he can not understand exactly what compilation errors disappeared — the compiler of the language which B uses shows errors in the new order every time! B is sure that unlike many other programming languages, compilation errors for his programming language do not depend on each other, that is, if you correct one error, the set of other error does not change.
Can you help B find out exactly what two errors he corrected?
Input
The first line of the input contains integer n (3 ≤ n ≤ 105) — the initial number of compilation errors.
The second line contains n space-separated integers a1, a2, …, an (1 ≤ ai ≤ 109) — the errors the compiler displayed for the first time.
The third line contains n - 1 space-separated integers b1, b2, …, bn - 1 — the errors displayed at the second compilation. It is guaranteed that the sequence in the third line contains all numbers of the second string except for exactly one.
The fourth line contains n - 2 space-separated integers с1, с2, …, сn - 2 — the errors displayed at the third compilation. It is guaranteed that the sequence in the fourth line contains all numbers of the third line except for exactly one.
Output
Print two numbers on a single line: the numbers of the compilation errors that disappeared after B made the first and the second correction, respectively.
题目大意
给你一个长度为
n的A
序列、一个长度为
n−1的B
序列、一个长度为
n−2的C
序列,求
A
中没有出现在
题解
考查哈希表的查找,用STL自带的map就行了,用两个map,一个存上一个序列的每个元素的出现次数,一个存当前序列中每个元素的出现次数,然后用map的find()来找上一个序列的每个元素是否在第二个map中,如果不在那么就输出这个数字,否则如果在第二个map中,但是其出现次数和第二个map中的出现次数不相同,那么也输出这个数字。map的find()函数非常快,不必担心超时问题
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#include <map>
#define MAXN 110000
using namespace std;
map<int,int>mp1,mp2;
map<int,int>::iterator it1,it2;
int a[MAXN],b[MAXN],c[MAXN];
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
mp1[a[i]]++;
}
for(int i=1;i<n;i++)
{
scanf("%d",&b[i]);
mp2[b[i]]++;
}
for(int i=1;i<=n;i++)
{
it1=mp1.find(a[i]),it2=mp2.find(a[i]);
if(it2==mp2.end()||*it1!=*it2)
{
printf("%d\n",a[i]);
break;
}
}
mp1=mp2;
mp2.clear();
for(int i=1;i<n-1;i++)
{
scanf("%d",&c[i]);
mp2[c[i]]++;
}
for(int i=1;i<n;i++)
{
it1=mp1.find(b[i]),it2=mp2.find(b[i]);
if(it2==mp2.end()||*it1!=*it2)
{
printf("%d\n",b[i]);
break;
}
}
return 0;
}C.A and B and Team Training
A and B are preparing themselves for programming contests.
An important part of preparing for a competition is sharing programming knowledge from the experienced members to those who are just beginning to deal with the contests. Therefore, during the next team training A decided to make teams so that newbies are solving problems together with experienced participants.
A believes that the optimal team of three people should consist of one experienced participant and two newbies. Thus, each experienced participant can share the experience with a large number of people.
However, B believes that the optimal team should have two experienced members plus one newbie. Thus, each newbie can gain more knowledge and experience.
As a result, A and B have decided that all the teams during the training session should belong to one of the two types described above. Furthermore, they agree that the total number of teams should be as much as possible.
There are n experienced members and m newbies on the training session. Can you calculate what maximum number of teams can be formed?
Input
The first line contains two integers n and m (0 ≤ n, m ≤ 5·105) — the number of experienced participants and newbies that are present at the training session.
Output
Print the maximum number of teams that can be formed.
题目大意
有
n
个老鸟和
题解
简单的线性规划问题。
设选了
x
个1类队(由1个老鸟和2个菜鸟组成),
2x+y≤m...(1)
x+2y≤n...(2)
x≥0...(3)
y≥0...(4)
目标函数
t=x+y,t
就是最终的队伍总数
然后对(1)、(2)变换:
y≤−2x+m...(5)
y≤−12x+12n...(6)
目标函数可以写成
y=−x+t...(7),因为要让t
最大,所以要让这个目标函数在坐标系上的截距最大
(3)、(4)、(5)、(6)、(7)在坐标系中构成下面这样的区域:
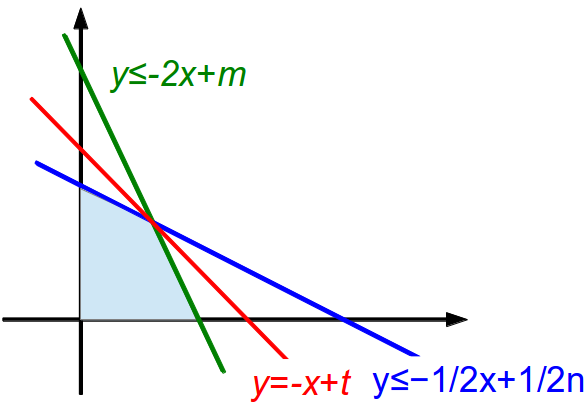
然后根据(5)和(7)的截距可以进行下面的三种分类讨论:
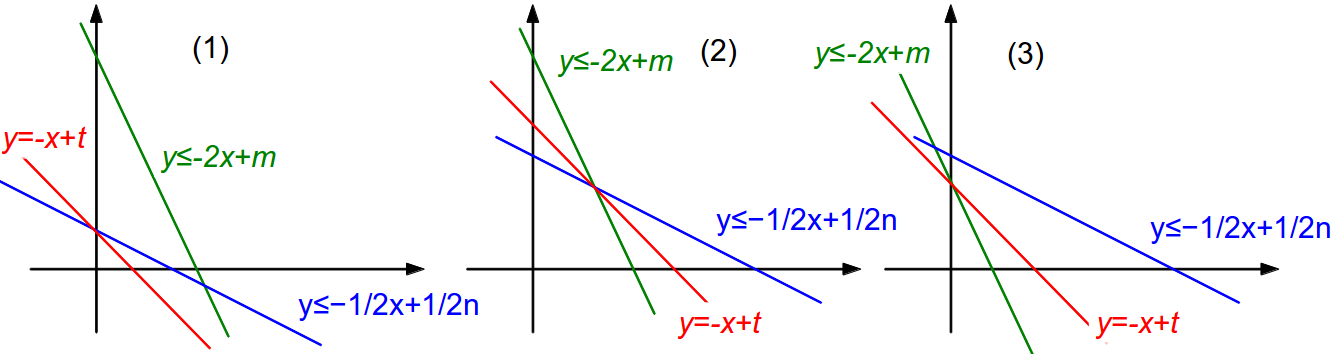
(1)
t=n
(2)
t=(n+m)3
(3)
t=m
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#include <map>
#define MAXN 110000
using namespace std;
int main()
{
int n,m;
scanf("%d%d",&n,&m);
if(m-2*n>=0) printf("%d\n",n);
else if(m-n/2>=0) printf("%d\n",(m+n)/3);
else printf("%d\n",m);
return 0;
}D. A and B and Interesting Substrings
A and B are preparing themselves for programming contests.
After several years of doing sports programming and solving many problems that require calculating all sorts of abstract objects, A and B also developed rather peculiar tastes.
A likes lowercase letters of the Latin alphabet. He has assigned to each letter a number that shows how much he likes that letter (he has assigned negative numbers to the letters he dislikes).
B likes substrings. He especially likes the ones that start and end with the same letter (their length must exceed one).
Also, A and B have a string s. Now they are trying to find out how many substrings t of a string s are interesting to B (that is, t starts and ends with the same letter and its length is larger than one), and also the sum of values of all letters (assigned by A), except for the first and the last one is equal to zero.
Naturally, A and B have quickly found the number of substrings t that are interesting to them. Can you do it?
Input
The first line contains 26 integers xa, xb, …, xz ( - 105 ≤ xi ≤ 105) — the value assigned to letters a, b, c, …, z respectively.
The second line contains string s of length between 1 and 105 characters, consisting of Lating lowercase letters— the string for which you need to calculate the answer.
Output
Print the answer to the problem.
题目大意
给出26个小写字母各自的权值,以及一个字符串
S
,求
题解
用
sum[i]表示前i
个字母的权值和(前缀和),容易发现一个合法的对
<i,j>
<script id="MathJax-Element-28" type="math/tex">
</script>,一定是
sum[i]=sum[j−1]
,这是显然的。那么我们可以对于从a到z中的每个字母,从字符串的开头到结尾扫一遍,用一个map记录每个sum[x]的出现次数,扫到字符串中的某一位
i
时,若这一位不是当前枚举的字母则跳过,否则在最终答案中累加当前
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#include <map>
#define MAXN 110000
using namespace std;
typedef long long int LL;
int score[MAXN];
char s[MAXN];
int n;
LL ans=0,sum[MAXN];
map<LL,int>mp;
int main()
{
for(char i='a';i<='z';i++) scanf("%d",&score[(int)i]);
scanf("%s",s+1);
n=strlen(s+1);
for(int i=1;i<=n;i++) sum[i]=sum[i-1]+score[(int)s[i]];
for(char ch='a';ch<='z';ch++)
{
mp.clear();
for(int i=1;i<=n;i++)
if(s[i]==ch)
{
ans+=mp[sum[i-1]];
mp[sum[i]]++;
}
}
printf("%I64d\n",ans);
return 0;
}
E. A and B and Lecture Rooms
A and B are preparing themselves for programming contests.
The University where A and B study is a set of rooms connected by corridors. Overall, the University has n rooms connected by n - 1 corridors so that you can get from any room to any other one by moving along the corridors. The rooms are numbered from 1 to n.
Every day А and B write contests in some rooms of their university, and after each contest they gather together in the same room and discuss problems. A and B want the distance from the rooms where problems are discussed to the rooms where contests are written to be equal. The distance between two rooms is the number of edges on the shortest path between them.
As they write contests in new rooms every day, they asked you to help them find the number of possible rooms to discuss problems for each of the following m days.
Input
The first line contains integer n (1 ≤ n ≤ 105) — the number of rooms in the University.
The next n - 1 lines describe the corridors. The i-th of these lines (1 ≤ i ≤ n - 1) contains two integers ai and bi (1 ≤ ai, bi ≤ n), showing that the i-th corridor connects rooms ai and bi.
The next line contains integer m (1 ≤ m ≤ 105) — the number of queries.
Next m lines describe the queries. The j-th of these lines (1 ≤ j ≤ m) contains two integers xj and yj (1 ≤ xj, yj ≤ n) that means that on the j-th day A will write the contest in the room xj, B will write in the room yj.
Output
In the i-th (1 ≤ i ≤ m) line print the number of rooms that are equidistant from the rooms where A and B write contest on the i-th day.
题目大意
给一个
n
个点的无根树,有
题解
比较容易想到LCA。首先随便找个点当成树根预处理一遍得到每个子树
然后对于每个询问
<a,b>
<script id="MathJax-Element-44" type="math/tex">
</script>(为了方便起见,保证
depth[a]>=depth[b]
),求出它们的最近公共祖先
LCA(a,b)=lca
,以及a到lca到b的最短路上的中点
c
<script id="MathJax-Element-47" type="math/tex">c</script>(若最短路径为奇数,直接输出无解,这个很显然)
然后分以下四种情况讨论,每种情况中,画红圈的部分都是可以选的点
1、a与b在一条链上
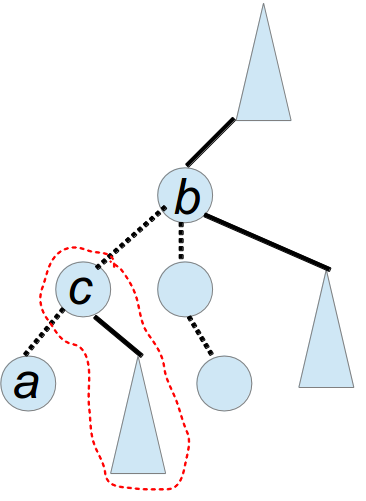
2、a与b的路径是a-lca-b,但是路径中点c在a与lca的链上
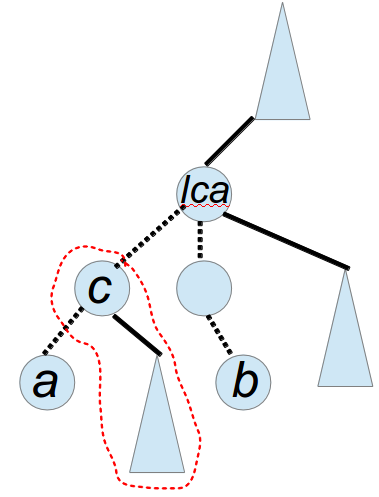
3、a与b的路径是a-lca-b,但是路径中点c在b与lca的链上
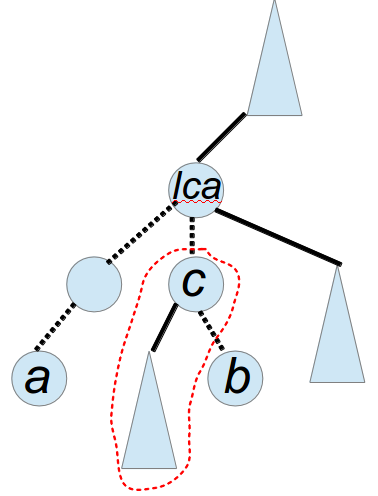
4、a与b的路径是a-lca-b,路径中点c就是lca
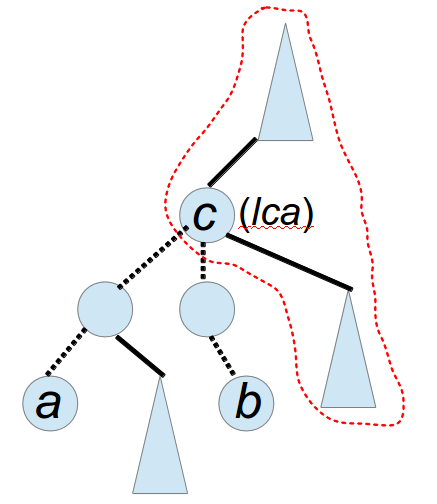
这样这个题就做完了,此题细节很多,如果考虑不周全便会贡献很多WA,比如像弱渣我>_<
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#include <map>
#define MAXN 110000
using namespace std;
typedef long long int LL;
int fa[MAXN][20];
int n,m;
struct edge
{
int u,v,next;
}edges[MAXN*2];
int head[MAXN],nCount=0;
void AddEdge(int U,int V)
{
edges[++nCount].u=U;
edges[nCount].v=V;
edges[nCount].next=head[U];
head[U]=nCount;
}
int size[MAXN],depth[MAXN];
void DFS(int u,int father)
{
size[u]=1;
for(int p=head[u];p!=-1;p=edges[p].next)
{
int v=edges[p].v;
if(v==father) continue;
depth[v]=depth[u]+1;
DFS(v,u);
size[u]+=size[v];
fa[v][0]=u;
}
}
void LCA_prework()
{
for(int i=1;i<=n;i++)
for(int j=1;j<=19;j++)
fa[i][j]=fa[fa[i][j-1]][j-1];
}
int LCA(int a,int b)
{
if(depth[b]>depth[a]) swap(a,b); //保证a比b深
for(int i=19;i>=0;i--)
{
if(depth[fa[a][i]]<=depth[b]) continue;
a=fa[a][i];
}
if(depth[a]>depth[b]) a=fa[a][0];
if(a==b) return a;
for(int i=19;i>=0;i--)
{
if(fa[a][i]==fa[b][i]) continue;
a=fa[a][i];
b=fa[b][i];
}
return fa[a][0];
}
int findNth(int x,int N) //找x的第N个祖先
{
if(!N) return x;
int goal=depth[x]-N;
for(int i=19;i>=0;i--)
{
if(depth[fa[x][i]]<=goal) continue;
x=fa[x][i];
}
x=fa[x][0];
return x;
}
int main()
{
memset(head,-1,sizeof(head));
scanf("%d",&n);
for(int i=1;i<n;i++)
{
int u,v;
scanf("%d%d",&u,&v);
AddEdge(u,v);
AddEdge(v,u);
}
DFS(1,-1);
LCA_prework();
scanf("%d",&m);
for(int i=1;i<=m;i++)
{
int a,b;
scanf("%d%d",&a,&b);
if(a==b) //特判!!!!坑爹啊
{
printf("%d\n",n);
continue;
}
if(depth[a]<depth[b]) swap(a,b); //保证a比b深
int lca=LCA(a,b);
int dist=(depth[a]-depth[lca])+(depth[b]-depth[lca]); //dist=a和b的最短路的距离
if(dist&1) //dist是奇数,则最短路径上没有中点无解
{
printf("0\n");
continue;
}
else
{
dist/=2; //此时dist是a(b)到最短路径中点的距离
int c=findNth(a,dist);
int ans=size[c];
if(lca==b||depth[a]-depth[c]>depth[b]-depth[c]) //a和b在一条链上或c在a到lca的链上
{
ans-=size[findNth(a,dist-1)];
}
else if(depth[a]-depth[c]<depth[b]-depth[c]) //c在b到lca的链上
{
ans-=size[findNth(b,dist-1)];
}
else
{
ans-=size[findNth(a,dist-1)];
ans-=size[findNth(b,dist-1)];
ans+=n-size[c];
}
printf("%d\n",ans); //答案是中点的子树大小
}
}
return 0;
}














 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









