







canopy是聚类算法的一种实现
它是一种快速,简单,但是不太准确的聚类算法
canopy通过两个人为确定的阈值t1,t2来对数据进行计算,可以达到将一堆混乱的数据分类成有一定规则的n个数据堆
由于canopy算法本身的目的只是将混乱的数据划分成大概的几个类别,所以它是不太准确的
但是通过canopy计算出来的n个类别可以用在kmeans算法中的k值的确定(因为人为无法准确的确定k值到底要多少才合适,而有kmeans算法本身随机产生的话结果可能不是很精确。有关kmeans算法的解释请看点击打开链接)
canopy算法流程如下:
(1)确定两个阈值t1,t2(确保t1一定大于t2)
(2)从数据集合中随机选出一个数据,计算这个数据到canopy的距离(如果当前没有canopy,则该点直接作为canopy)
(3)如果这个距离小于t1,则给这个数据标上弱标记,将t1加入这个canopy中(同时这个数据可以作为新的canopy来计算其他数据到这个点的距离)
(4)如果这个距离小于t2,则给这个数据标上强标记,并将其中数据集合中删除,此时认为这个数据点距离该canopy已经足够近了,不可能在形成新的canopy
(5)重复2-4的过程,直至数据集合中没有数据
这里的canopy指的是作为要划分数据的中心点,以这个canopy为中心,t2为半径,形成一个小圆。t1为半径,形成一个大圆。在小圆范围内的数据点被认为一定属于这个canopy,不能作为一个新的canopy来划分数据,而小圆范围外,大圆范围内的数据则又可以作为新的canopy来划分数据
划分完之后的数据类似下图
虚线的圈是t2,实线的圈是t1
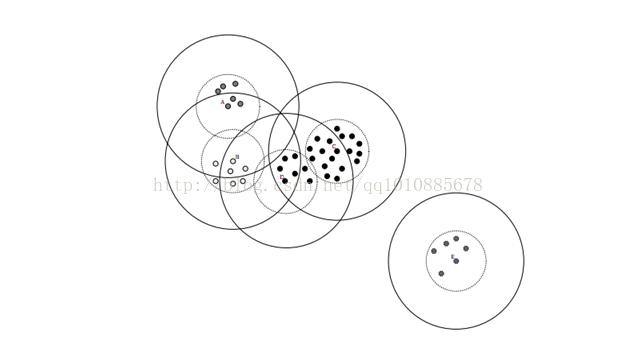
可以看到canopy算法将可以将一堆杂乱的数据大致的划分为几块
所以canopy算法一般会和kmeans算法配合使用来到达使用者的目的
在使用canopy算法时,阈值t1,t2的确定是十分重要的
t1的值过大,会导致更多的数据会被重复迭代,形成过多的canopy;值过小则导致相反的效果
t2的值过大,会导致一个canopy中的数据太多,反之则过少
这样的情况都会导致运行的结果不准确















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









