







KNN聚类技术

图为年龄与收入,是否会购买杂志
KNN就是选定一个K为半径,样本为原点的圆,如果圆内那个类别偏多,那么我们就将该样本分为该类。K为超参数,由于我们自己确定。
KNN理论基础:同一个集群的客户将表现出相同的行为。
所以集群与相邻的客户相同,它不是一种机器学习方法
劣势:效率低下,因为不能确定K所以要多次尝试。
很难解释为什么使用KNN聚类效果会比naïve prediction的预测好。
KNN与Naïve Prediction结果概率对比:

我们发现正确概率确实大很多。
实际运用KNN的3个步骤
数据的预处理(Data Preprocessing)保证属性(age vs Income)的度量(比例)scale没有问题。记得标准化
距离的计算(Distance Caculation):选择哪种距离计算公式
预测概率的推算(Predicted Probability)
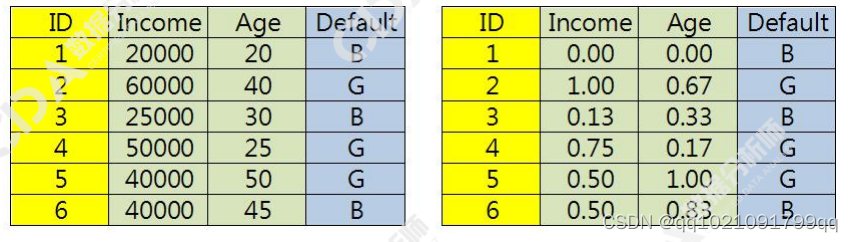
步骤1:标准化
我们这里使用极值正规划(Min-max Normalization)【0,1】

转变效果如下:
步骤2几种距离计算:
曼哈顿距离(一次方),这个是街道距离,不是直线距离

其中的R公式如下:

欧式距离(二次方)
就是我们经典的距离公式了,直线距离

二者的差距在于p的把控最终公式为

当p等于1时为曼哈顿距离
当p等于2时为欧式距离
Python配件中就是以改变p来改变距离公式
步骤3:
比如有一个分3类的距离,测试数据样本为T,k=5.结果如下
最近一笔的目标为A类
第二近的一笔目标属性为B类
第三近的一笔目标属性为A类
第四近的一笔目标属性为C类
第五近的一笔目标属性为A类
则我们预测该笔目标属性值为A,准确率为3/5
案例1给下列疾病诊断数据,字段一是病人代号,后面的输入字段(喉咙痛、发烧、淋巴腺肿胀、充血,头疼)以及目标字段(诊断结果)

利用KNN预测下列病人的诊断结果(K=3)
Distance(Yes,No)=1
DIStance(YES,YES)=0
Distance(No,No)=0
两客户的distance计算方式采用截取距离















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











