









文章目录
- 前言
- 5.1 进程的内部机理
- 5.2 受保护的进程
- 5.3 CreateProcess的流程
- 5.4 线程的内部机理
- 5.5 检查线程的活动
- 5.6 工作者工厂(线程池)
- 5.7 线程调度
- 5.8 基于处理器份额的调度
- 5.9 动态的处理器添加与更换
- 5.10 作业对象
- 实验
- 总结
前言
在本章中,我们将介绍Microsoft Windows中用于处理进程(process)、线程(thread)和作业(job)的数据结构和算法。
第一节集中介绍了构成一个进程的内部结构。
第二节概要地介绍了创建一个进程(和它的初始线程)时所涉及的步骤。然后介绍了线程的内部机理和线程调度机制。本章最后还讲述了作业对象。
因为在Windows中进程和线程牵涉到了如此众多的组件,所以,本章中引用到了大量的术语和数据结构(比如工作集、对象和句柄、系统内存堆,等等),但是它们的细节解释却在本书别的地方。
为了全面理解本章的内容,你需要熟悉第1章——“概念和工具”和第2章一“系统架构”中解释的术语和概念,比如进程和线程之间的差别、Windows虚拟地址空间的布局结构,以及用户模式和内核模式之间的差别。
5.1 进程的内部机理
本节讲述了由系统各个部分维护的Windows进程的关键数据结构,并且描述了能查看这些数据的方法和工具。
本节之后掌握的知识点:
- EProcess: Executor Process 执行体进程
- EThread: Executor Thread 执行体线程
- PEB:Process Enviroment Block 进程环境块。
- CSR_Process:每一个进程都对应着一个 CSR_PROCESS 结构体,所有进程的CSR_PROCESS 结构体
5.1.1 数据结构
每个Windows进程都是由一个执行体进程(EPROCESS)结构来表示的。EPROCESS结构中除了包含许多与进程有关的属性以外,还包含和指向了许多其他的相关数据结构。例如,每个进程都有一个或者多个线程,这些线程由执行体线程(ETHREAD)结构来表示(本章后面的“线程的内部机理”一节解释了有关线程的数据结构)。
EPROCESS和相关的数据结构位于系统空间中,不过,进程环境块(PEB)是个例外,它位于进程地址空间中(因为它包含一些需要由用户模式代码来修改的信息)。此外,一些用于内存管理的数据结构,如工作集列表,仅在当前进程的环境中有效,因为它们保存在进程相对应的系统空间中(参见本书下册第10章一“内存管理”以得到更多的有关进程地址空间的信息)。
对于每个执行了一个Win32程序的进程,Win32子系统进程(Csrss)为它维护了一个平行的结构CSR_PROCESS。最后,Windows子系统的内核模式部分(Win32k.sys)有一个针对每个进程的数据结构,W32PROCESS。当一个线程第一次调用Windows的USER或GDI函数(它们是在内核模式中实现的)时,W32PROCESS结构就会被创建。除了空闲进程外,每个EPROCESS结构被执行体对象管理器 (executiveobjectmanager)封装为一个进程对象(在第3章一“系统机制”中描述)。
因为进程不是命名的对象 (named object),它们在Winobj工具中不可见。然而,你可以在objectTypes目录中见到名为“Process的对象。一个进程句柄通过进程相关的API提供EPROCESS结构中部分数据以及它的相关结构中数据的访问。图5.1是一个简化的关于进程和线程数据结构的框图。图中显示的每个数据结构在本章中都有详细的描述。
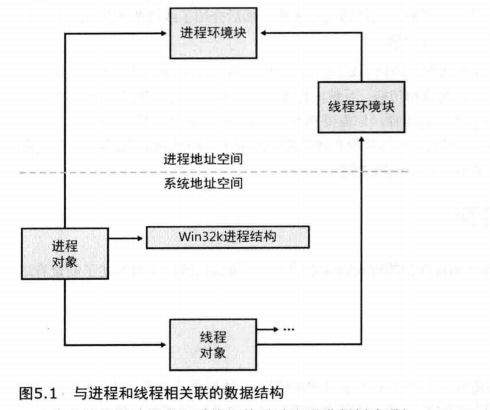
许多其他驱动程序和系统组件通过注册进程创建通知(process creation notification),能够选择创建它们自己的数据结构,从而以进程为单位跟踪它们保存的信息。当谈及进程的额外开销时,此类数据结构的大小通常必须考虑在内,尽管精确的数值几乎无法得到。
首先我们来关注进程对象(在本章后面的“线程的内部机理”一节中我们将会介绍线程对象)。图5.2 显示了EPROCESS结构中的关键域。
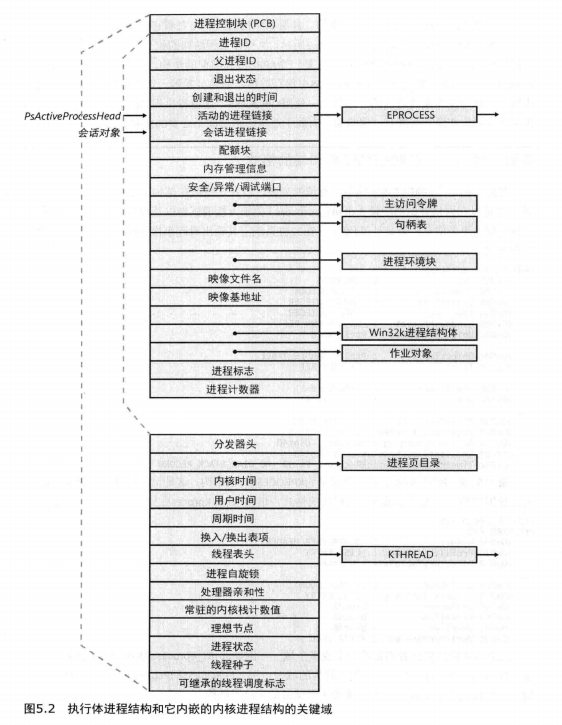
正如内核的API和组件被分成隔离的、具层次结构的模块,有着它们各自的命名规范,进程的数据结构也遵循类似的设计。如图5.2所示,执行体进程结构的第一个成员称作Pcb,代表进程控制块(process control block)。它是一个KPROCESS类型的结构,代表内核进程(kernelprocess)。虽然执行体的例程往EPROCESS中保存数据,但是分发器、调度器和中断/时间记账代码一一作为操作系统内核的一部分一一使用KPROCESS。这使得执行体的高层功能和下面的底层特定功能实现之间能有一层抽象,有助于避免这两层间不必要的依赖关系。
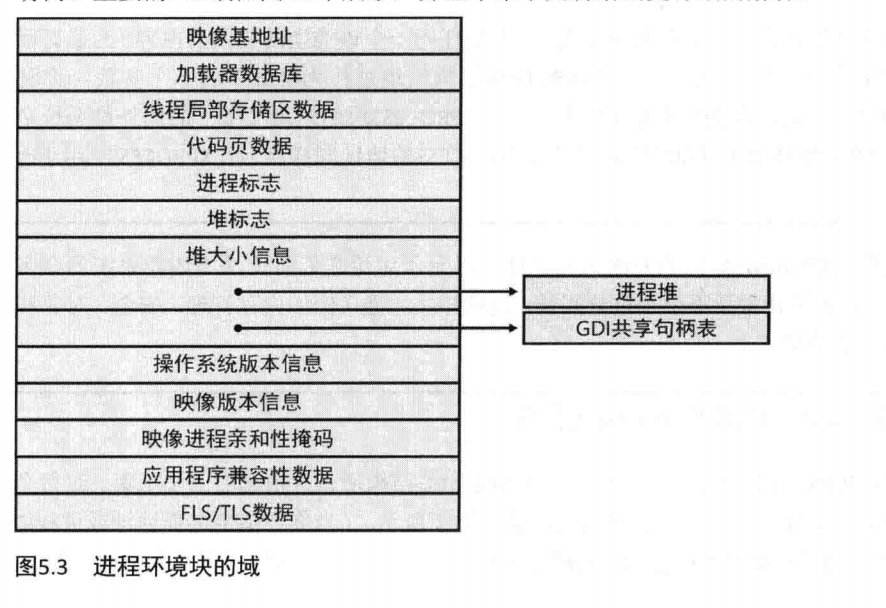
PEB位于它所描述的进程的用户模式地址空间。它包含映像加载器、堆管理器以及其他需要从用户模式访问它的Windows组件所需的信息。EPROCESS和KPROCESS结构只能从内核模式访问。重要的PEB域在图5.3中展示,并且本章下文将给出更详细的解释。
5.2 受保护的进程
在Windows安全模型中,任何一个进程的令牌只要有调试权限(例如一个管理员账号)就能对机器上其他任何进程请求任意的访问权限一一例如,它可以读写任意进程内存,注入代码,挂起和恢复线程,以及查询其他进程的信息。类似于Process Explorer和任务管理器这样的进程需要并会请求这些访问权限以提供它们的功能给用户。
这种逻辑行为(它们帮助保证管理员对系统上正在运行的代码总是拥有完全控制)与媒体工业要求数码权限管理的系统行为相冲突。它针对需要支持高级、高品质数码内容的播放,如播放蓝光、HD-DVD等媒体的计算机操作系统。
为了支持此类内容可靠的、受保护的播放Windows使用了受保护进程这些进程与普通Windows进程并存,但它们对系统中其他进程(即使以管理员特权运行)可申请的访问权限上增加了重要的限制。
受保护进程可以由任何应用程序创建
然而,操作系统仅在以下条件下允许一个进程被保护:
它的映像已被一个特殊的Windows Media证书数字签名过。
Windows中的受保护的媒体路径(PMP)使用受保护进程来提供对高价值媒体的保护,同时DVD播放器之类应用程序的开发人员可以使用媒体基础API (Media Foundation API)来使用受保护进程的功能。
音频设备图形进程(Audiodg.exe)是一个受保护进程,因为受保护的音乐内容可以通过它被解码。类似地,Windows错误报告 (WER,在第3章中讨论过)客户进程 (Werfault.exe)也能受保护地运行,因为它需要在一个受保护进程崩溃时访问它。最后,System进程它自己也是受保护的,因为某些解密信息是通过Ksecdd.sys驱动程序生成后保存在它的用户模式内存中的System进程受保护的另一个原因是为了保护所有内核句柄的完整性(因为System进程的句柄表含有系统中所有的内核句柄)。
在内核层面上对受保护进程的支持分为两块:首先,进程创建过程完全在内核模式进行以避免注入式攻击。(下一节将详细描述普通进程和受保护进程的创建流程。) 其次,受保护进程会在EPROCESS结构中设置一个特殊的位,它修饰了进程管理器中安全方面例程的行为,会拒绝某些通常授予管理员的访问权。
事实上,对受保护进程仅有的访问权是:
- PROCESS QUERY
- SET_LIMITED_INFORMATION
- PROCESS_TERMINATE
- PROCESS_SUSPEND_RESUME。
某些特定的访问权对运行于受保护进程内的线程也是禁用的:我们将在本章后面的 “线程的内部机理节探索它们。
因为Process Explorer使用普通的用户模式Windows API来查询进程内部的信息,它对受保护进程无法进行某些操作。另一方面,WinDbg这样的工具运行于内核调试模式下,使用内核模式基础设施来获取这些信息,能得到完整的信息。参见“线程的内部机理”一节,有关ProcessExplorer面对受保护进程如Audiodgexe时如何反应的实验。
注 如同在第1章中讲到的,要执行本地内核调试,你必须以调试模式引导系统(可通过bcdedit/debug on或通过Msconfig高级启动选项启用)。这种实现能够避免基于调试器的对受保护进程和受保护的媒体路径(PMP)的攻击。当系统以调试模式引导时,高清内容播放将不工作。
对这些访间权的限制,能够可靠地让内核把受保护进程放在一个避开用户模式访问的沙箱内。另一方面,因为受保护进程是通过EPROCESS结构内的标志位表示的,管理员仍可以加载一个禁用此标志位的内核模式驱动程序。然而,这是对PMP模型的破坏,并且被认为是恶意的,而且这样的驱动程序最终将很可能被64位系统禁止加载,因为内核模式的数字签名策略严禁对恶意代码签名。即使在一个32位系统上,驱动程序也必须被PMP策略识别,否则播放将被停止。这个策略是Microsoft制定的,而不是通过任何内核探测机制实现。这种禁止机制将罗求Microsoft通过人工操作来定义签名是恶意的,并更新内核。
5.3 CreateProcess的流程
本章到现在为止已经展示了各种在进程状态操作和管理中使用的结构,以及各种工具和调试器命令如何能够观察这些信息。在本节中,我们将看到如何及何时这些数据结构被创建和填充,以及进程幕后总体的创建和终止行为。
当一个应用程序调用 (或最终结束于)某个进程创建函数,比如CreateProcess、CreateProcessAsUser、CreateProcessWithTokenw或CreateProcessWithLogonw时,一个Windows子系统进程就被创建起来了。创建一个Windows进程的过程,是由操作系统的三个部分执行系列步骤来完成的,这三个部分是客户方的Windows库Kernel32dll (在CreateProcessAsUser、CreateProcessWithTokenW或CreateProcessWithLogonw的情况下时,部分工作是由Advapi32.dll先做的)、Windows执行体和Windows子系统进程(Csrss)。
由于Windows是多环境子系统的体系结构,因此,创建一个Windows执行体进程对象(其他的子系统也可以使用),与创建一个Windows子系统进程的工作是分离的。所以,尽管接下来关于Windows的CreateProcess函数的流程的介绍非常复杂,但是,要记住,这其中的一部分工作是与Windows子系统加入的语义相关的(相对于创建一个Windows执行体进程对象所需要的核心工作而言,这是额外加入的工作)。
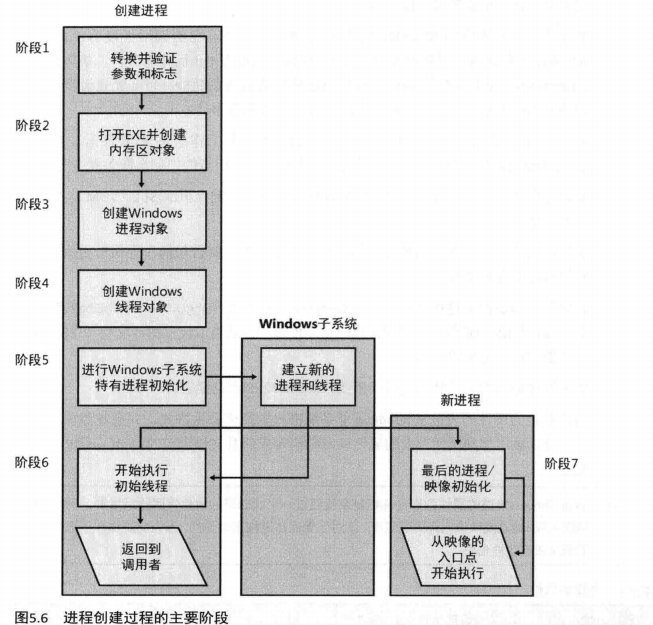
下面的列表概括了在利用Windows的CreateProcess函数来创建一个进程时所涉及的主要阶段。在后续的小节中将详细地讲述在每一个阶段中执行的操作。这些操作中有的会由CreateProcess自己完成(或其他的用户模式的工具例程),而其他的操作将由NtCreateUserProcess或它的工具例程在内核模式完成。在后面的详细分析中,对每个必要步骤我们将区分这两者。
注:CreateProcess的许多步骤与进程虚拟地址空间的建立有关系,因此,在下面的介绍中引用了本书下册第10章中定义的许多与内存管理有关的术语和结构。
- 验证参数,转换Windows子系统标志和选项为对应的原生形式:解析、验证和转换属1性列表为其原生形式。
- 打开将要在该进程中执行的映像文件 (.exe)。
- 创建Windows执行体进程对象。
- 创建初始线程(栈、执行环境,以及Windows执行体线程对象)。
- 进行创建之后的、Windows子系统特有的进程初始化。
- 开始执行初始线程(除非指定了CREATESUSPENDED标志)
- 在新进程和线程的环境中,完成地址空间的初始化(比如加载必要的DLL),并开始执行程序。
阶段1
阶段2
阶段3
阶段4
阶段5
阶段6
5.4 线程的内部机理
在操作系统层次上,Windows线程是由一个执行体线程对象来表示的。执行体线程对象封装了一个ETHREAD结构,而后者又含有一个KTHREAD结构作为它的第一个成员。
这些情况如图5.8所示。ETHREAD结构和它所指向的结构都位于系统地址空间中,唯一的例外是线程环境块(TEB),它位于进程地址空间中(同样地,是因为用户模式组件需要访问它)。而且,Windows子系统进程(Csrss)为Windows进程中创建的每个线程维护了一个平行的结构,称为CSR THREAD。另外,对于那些已经调用了任一个Windows子系统USER或GDI函数的线程,Windows子系统的内核模式部分(Win32ksys)为每个这样的线程维护了一个数据结构,称为W32THREAD结构,线程的KTHREAD结构指向此结构。
注:执行体的、高级的、图形相关的Win32k结构是由KTHREAD来指向,而不是ETHREAD来指向的这一事实,看起来像是一个层级关系的违反,或是标准内核的抽象架构的一个设计疏忽一调度器和其他底层组件并不使用这个域。
图5.8中显示的绝大多数域已经不言自明了。ETHREAD的第一个域是Tb,表示“线程控制块”:它是一个类型为KTHREAD的结构。紧随其后的是线程标识信息、进程标识信息 (包括一个指向所有者进程的指针,因而可以访问它的环境信息)、安全信息(其形式包括一个指向访问令牌的指针,以及身份模仿信息),最后是与异步本地过程调用(ALPC)消息和待处理/O请求有关的域。有些关键域将在本书其他地方详细讲述。关于ETHREAD结构的内部结构的更多细节,你可以使用内核调试器dt命令来显示该结构的格式。
现在我们来更仔细地看一看在上面段落中引用到的两个关键的线程数据结构:KTHREAD和TEB。KTHREAD结构(它是ETHREAD的Tcb成员)包含了Windows内核为这些正在运行的线程执行线程调度、同步和计时而需要访问的信息。
5.4.1 一个线程的诞生
当一个程序创建一个新的线程时,该线程的生命周期就开始了。此创建线程的请求被传递到Windows执行体中,在这里,进程管理器(processmanager)为线程对象分配空间,并调用内核来初始化线程控制块(KTHREAD)。
在Windows Kernel32.dll中的CreateThread函数内部,采取以下的步骤来创建一个Windows线程:
- CreateThread转换Windows API标志为原生标志,并构造一个原生结构来描述对象参数(OBJECT_ATTRIBUTES。要了解更多信息,请参见第3章。
- CreateThread构造一个包含两个表项的属性列表:客户ID和TEB地址。这使得CreateThread在线程创建完毕后可以收到它们的值。(有关属性列表的更多信息,参见本章前文中“CreateProcess的流程”一节。)
- 调用NtCreateThreadEx,以创建用户模式执行环境,并应用属性列表及捕获它所需的值。然后它调用PspCreateThread来创建一个挂起的执行体线程对象。有关该函数执行步骤的描述,请参见“CreateProcess的流程”一节中阶段3和阶段5的介绍。
- CreateThread为线程分配一个由并行程序集支持使用的激活环境。然后它查询激活栈看是否有必要激活:如果是,就激活。激活栈的指针保存在新线程的TEB中。
- CreateThread通知Windows子系统有关新线程的信息,子系统为新线程做一些准备工作。
- 将线程句柄和线程ID(在第3步中生成的)返回给调用者。
- 除非调用者在创建线程的调用中指定了CREATESUSPENDED标志,否则,该线程现在恢复运行,因而它可以被调度执行。当该线程开始运行时,它在调用实际用户指定的启动地址以前,首先执行早先一节的“阶段7:在新进程环境下执行进程初始化”中描述的步骤。
5.5 检查线程的活动
如果你试图确定一个宿纳有多个服务的进程(例如Svchostexe,Dllhost.exe,或Lsass.exe)为什么在运行或一个进程为什么挂起了,那么检查线程活动是尤为重要的手段有好几个工具能揭露线程状态的各种元素:WinDbg(在用户模式附载和内核调试模式时)、性能监视器和进程管理器 (Process Explorer)。(“线程调度”一节中列出了一些能显示有关线程调度信息的工具。)
为了使用进程管理器查看一个进程内的线程,你可以选择一个进程,并打开进程的属性(在你选择的进程上双击,或者单击Process菜单,并选择Properties菜单项)。然后在Threads标签上单击。此页面显示了该进程内的线程列表(包含四列信息)。对于每个线程,它显示了它的ID、所消耗CPU时间的百分比(基于配置好的刷新间隔)、为该线程记录的CPU周期数,以及线程的启动地址。你可以按照任何一列来排序。
新创建的线程被加亮显示成绿色,而退出的线程则被加亮显示成红色(通过Options、Difference Highlight Duration菜单项可以配置加亮显示的时间长度)。 这对于发现一个进程中不必要的线程创建操作,可能会非常有帮助(一般而言,线程的创建应该发生在进程启动的时候,而不是每次当该进程处理一个请求的时候)。
当你从线程列表中选中一个线程时,进程管理器显示它的线程ID、启动时间、状态、CPU时间计数器、环境切换的次数、理想的处理器和处理器组,以及基本优先级和当前优先级。窗口中有一个Kill按钮,它将会终止一个线程,但这一功能用起来应该要绝对小心。另一个选择是Suspend按钮:它将阻止线程继续运行,从而避免一个失去控制的线程消耗CPU时间。然而这也可能引起死锁,所以对它也要像对Kill按钮一样小心谨慎。最后,Permissions按钮能让你查看线程的安全描述符。(有关安全描述符的更多信息,请参见第6章“安全性”。)
与任务管理器和所有其他的进程/处理器监视工具不同,进程管理器使用了为线程运行时间记账而设计的时钟周期计数器(如本章后文中所描述的那样),而不是时钟间隔定时器,所以使用进程管理器时,你会看到明显不同的CPU消耗显示。这是因为许多线程每次只运行非常短的时间,短至当时钟间隔定时器中断发生时,它们难得(如果有过的话)成为当前运行的线程,所以它们的大多数CPU时间没有记录,使得基于时钟的工具总是检测到0%的CPU使用。反过来,时钟周期的总数则代表进程中每个线程使用的处理器周期的实际数值。它与时钟间隔定时器的分辨率无关。
线程启动地址被显示成“module!function”(“模块!函数”)的形式,这里module是exe或者.dll的名称。函数名依赖于能否访问该模块的符号文件(参见第1章中的“实验:利用进程管理器查看进程的细节”)。如果你不能确定该模块是什么,你可以按下Module按钮。这将打开Windows资源管理器的文件属性窗口,其中显示了包含该线程启动地址的模块(例如,exe或dll文件)的属性。
注:对于那些通过Windows的CreateThread函数创建的线程,进程管理器显示的是传递给CreateThread的函数,而不是实际的线程启动函数。这是因为,所有的Windows线程都是从-个公共的进程或线程启动封装函数(Ntdl.dl中的RtlUserThreadStart)开始执行的。如果进程管理器换成显示实际启动地址,那么,进程内的绝大多数线程就会看起来都是从同一个地址开始执行的,这对于理解一个线程正在执行什么样的代码,将毫无帮助。然而,如果进程管理器无法查询到用户定义的启动地址(例如,受保护进程的情形),它将显示封装函数,从而你会看见所有的线程都从RtlUserThreadStart启动。
然而,这里显示的线程启动地址可能还不足以查明该线程正在做什么事情,以及该进程内的哪些组件负责该线程所消耗的CPU时间。如果线程的启动地址是一个通用的启动函数(警如,此函数名根本没有指明该线程实际在做什么事情),则情况尤为如此。在这种情况下,检查线程的栈可能会解答这样的问题。为了查看一个线程的栈,你可以在感兴趣的线程上双击(或者选中该线程,并单击Stack按钮)。进程管理器显示了该线程的栈(如果该线程在内核模式中,则同时包括用户模式栈和内核模式栈)。
注:虽然用户模式调试器(WinDbg、Ntsd和Cdb)允许你附载到一个进程中,并显示一个线程的用户栈,但是,在进程管理器中,你只需轻轻点一个按钮,就可以同时显示用户栈和内核栈。你也可以使用Win Db g,在本地内核调试模式下,检查用户线程栈和内核线程栈。
检查线程的栈也有助于你判断为什么一个进程被挂起了。例如,在一个系统上,Microsoftoffice PowerPoint在启动时有一分钟时间停止不动。为了判断为什么它被挂起了,你在启动了PowerPoint之后,可以使用进程管理器来检查该进程中一个线程的栈。图5.12显示了此结果
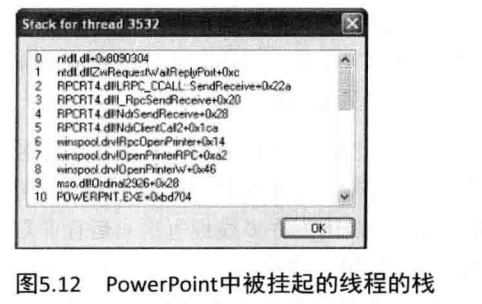
此线程栈表明,PowerPoint(第10行)调用了Msodl (主要的Microsoft office DLL)中的-个函数,该函数又调用了Winspool.drv(一个用于连接至打印机的DLL)中的OpenPrinterW函数。然后,Winspool.drv分发至函数OpenPrinterRPC,它又调用RPC运行库DLL中的一个函数,这说明它正在给一台远程打印机发送请求。所以,无须理解PowerPoint的内部机理,仅仅根据线程栈中显示的模块和函数名,就知道该线程正在等待连接到一台网络打印机。在这个特定的系统上,有一台网络打印机不响应了,这就解释了PowerPoint在启动时的延迟(Microsoft office应用程序在进程启动时会连接到所有已配置的打印机上)。 在用户的系统上删除了该打印机的连接以后,问题就迎刃而解了。
最后,当查看64位系统上作为Wow64进程运行的32位应用程序时(有关Wow64的详细信息,请参见第3章),进程管理器既显示进程中线程的32位栈,也显示它的64位栈。因为在系统调用执行过程中,线程已切换到了64位的栈和环境,所以如果只查看64位栈,将只能看到故事的一半一一线程的64位部分,以及Wow64的thunk代码。所以,当检查Wow64进程时,请确认你已同时考虑了32位栈和64位栈。Microsoft office Word 2007中的一个Wow64线程如图5.13所示。高亮的栈帧和它下面所有的栈帧是32位栈上的32位栈帧。高亮的栈帧上面的栈帧则是64位栈上的栈帧。

5.5.1 受保护进程的线程上的访问限制
如同我们之前在“进程的内部机理”一节中讨论的那样,受保护进程在能提供的访问权这方面有多种限制,即便是对系统上拥有最高特权的用户也是如此。这些限制也适用于这种进程中的线程。这能保证实际运行于受保护进程中的代码不会被劫持,或通过其他途径被标准的Windows函数所影响(这些函数要求某些权限,而这些权限不会为受保护进程提供)。
事实上,能提供的权限仅有:
- THREAD_SUSPEND_RESUME
- THREAD_SET/QUERY LIMITEDINFORMATION
5.6 工作者工厂(线程池)
工作者工厂(Worker Factories)指一种用以实现用户模式线程池的内部机制。老版本的线程池函数(位于Ntdlldll中)曾经完全在用户模式实现。它们的WindowsAPI提供了各种例程以调用到相关的实现例程,实现了可等待定时器、等待回调,以及基于工作量的自动的线程创建与删除。
因为内核可以直接控制线程的调度、创建和终止,并且没有从用户模式做这些操作时具有的典型开销,所以Windows中大多数为支持实现用户模式线程池所要求的功能,现在已被置入内核模式了,这也简化了开发人员需要编写的代码。例如,从一个远程进程创建一个工作者池可以仅通过一个API调用就完成,而不必通过这一操作通常必需的、复杂的一系列虚拟内存调用来完成。在这一模型下,Ntdll.dll仅提供必要的接口和高级API,从而能与工作者工厂代码相衔接。
这一Windows中由内核管理的线程池功能是由名为TpWorkerFactory的对象管理器类型管理的。做这些管理的还有:
- 四个管理工厂及其工作者的原生系统调用(NtCreateWorkerFactory、NtWorkerFactoryWorkerReady、NtReleaseWorkerFactoryWorker、NtShutdownWorkerFactory),两个查询、设置原生调用(NtQuerylnformationWorkerFactory和NtSetlnformationWorkerFactory)和一个等待调用(NtWaitForWorkViaWorkerFactory)。
与其他的原生系统调用一样,这些调用为用户模式提供了一个指向TpWorkerFactory对象的句柄,它包含例如名称、对象属性、请求的访问掩码以及安全描述符之类的信息。然而,与其他的WindowsAPI包装的系统调用不同,线程池的管理是由Ntdll.d中的原生代码处理的。这意味着开发者操作的是一个不透明的、由Ntdll.d所拥有的描述符(一个TP WORK指针)而实际的句柄则保存在它的里面。
如同它的名称所示,工作者工厂的实现要负责分配工作者线程(并调用给定的用户模式工作者线程的入口点),维护最小的和最大的线程数(以允许永久的工作者池或完全动态的池)和其他计账信息。这使得关闭线程池之类的操作只需要对内核调用一次即可完成,因为内核是在使用线程池的过程中对线程创建和终止负责的唯一组件。
由于内核基于所提供的最小和最大的线程数,根据需要动态地创建新线程,这也提高了使用新线程池实现的应用程序的可伸缩性。工作者工厂将在以下所有情况都符合的前提下创
建新线程:
可用的工作者数量低于已为工厂配置的最大工作者数(默认值为500)。
工作者工厂有绑定对象(绑定对象的一个例子是,工作者线程正在等待的一个ALPC端口)或一个线程已被激活进入池中。
存在等待处理的/0请求包(I/O Request Packets,IRPs:更多信息,参见本书下册第8
章“I/O系统”),它们关联到一个工作者线程。已启用动态线程创建。当线程空闲超过10秒钟(默认值)后,工厂会终止线程更进一步,虽然通过老版本的实现,开发人员已经能够(基于系统中的处理器数量)利用尽可能多的线程但是通过Windows Server对动态处理器的支持(参见本章下文中讨论这个题的一节),应用程序现在还能使用线程池对运行时动态添加的处理器进行充分利用。
注意工作者工厂支持只是一个对应用程序能在用户模式(可能会有性能损失) 完成的一些平凡的任务的封装,以及新线程池的很多代码逻辑存在于这一架构的Ntdll.dl一边。(理论上说,通过使用未文档化的函数,可以在工作者工厂之外建造一个不同的线程池实现。) 而且,也并不是工作者工厂的代码提供了可伸缩性、等待的内部机理和工作处理的效率;相反,是我们之前讨论过的一个老得多的Windows组件一-/0完成端口 (I/0 completion ports),或更正确地说,是内核队列(KQUEUE,参见本书下册第8章以获得更多信息)提供了这样的能力和效率。
事实上,当创建一个工作者工厂时,一个I/0完成端口必须已由用户模式创建,而且它的句柄需要被传递下去。正是通过这一/0完成端口,用户模式的实现把工作放入队列中,并等待工作一一但实现的途径是通过调用工作者工厂的系统调用,而不是直接调用I/0完成端口API然而,从内部看,“释放”工作者工厂调用(它把工作入队列)是一个围绕loSetloCompletionEx的封装,它会增加等待处理的工作的计数,而“等待”调用则是对loRemoveloCompletion的封装。这两个例程都会调用到内核队列的实现。
因此,工作者工厂代码的任务是,管理一个或持久、或静态、或动态的线程池;通过自动地创建动态线程,将I/0完成端口模型包装为试图避免停顿的工作者队列的界面:以及在关闭工厂的请求中,简化全局的清理和终止操作(并在此情形下从容地阻止新的请求)。
不幸的是,工作者工厂使用的数据结构并不包含在公开的符号内,但还是可以查看一些工作者池,如同我们将在下一个实验中演示的那样。另外,NtQuerylnformationWorkerFactoryAPI能转储出工作者工厂结构中几乎所有的域。
5.7 线程调度
本节描述了Windows调度策略和算法。第一小节集中描述了在Windows上线程调度是如何工作的,同时也介绍一些关键术语的定义。然后,分别从WindowsAPI和Windows内核的角度讲述了Windows优先级别。在回顾了与调度有关的Windows实用工具以后,接着又详细地介绍了构成Windows调度系统的数据结构和算法,其中也描述了常见的调度发生情形,以及线程和处理器是如何被选择的。
Windows调度概述
Windows实现了一个优先级驱动的、抢先式调度系统一一具有最高优先级的可运行(就绪)线程总是运行,而该线程可能仅限于在允许它运行(或设定为偏好的)的处理器上运行,这种现象称为处理器亲和性(processoraffinity)。
处理器亲和性是基于一个给定的处理器组来定义的,它包含至多64个处理器。在默认情况下,线程只能在它所属的进程关联的处理器组中任何一个空闲的处理器上运行(这样做的目的是为了维持与支持至多64个处理器的老版本Windows的兼容性),但是,开发人员可以使用适当的API或在映像头部设置一个亲和性掩码,来改变处理器亲和性,而用户也可以使用工具,在进程创建时或运行时改变它的亲和性。然而,虽然一个进程中的多个线程可以关联到不同的处理器组,但对单个线程来说,它只能运行在它被指定的单个处理器组中的可用处理器上。另外,开发人员可以选择创建对处理器组敏感的应用程序,它们使用扩展的线程调度API把不同的处理器组内的逻辑处理器关联到线程的亲和性上。这样做的话,该进程就被转换为一个多处理器组进程,理论上它能在机器中任何可用的处理器上运行它的线程。
一个线程被选中运行的时候,它运行一定长度的时间,这段时间称为时限(quantum)。时限是指,一个线程在“系统将运行权交给同一优先级别上的另一个线程”之前允许运行的时间长度。时限值可以随着系统的不同而不同,也可以随着进程的不同而不同,其理由有三:
- 系统配置中的设置(长的或短的时限值,可变的或固定的时限值,以及优先级分离)。
- 进程的前台/后台状态。
- 使用作业对象来改变时限值。
在本章后面的“时限”一节中更加详细地讲述了时限
然而,一个线程可能未能完成它的时限。因为Windows实现了一个抢先式调度器,所以,如果另一个具有更高优先级的线程变成就绪状态时,当前正在运行的线程可能在完成它的时间片之前被抢占掉了。实际上还可能发生这样的情况:一个线程被选中作为下一个将要运行的线程,但是在它的时限开始以前就可能被抢占掉。
Windows调度代码是在内核中实现的。然而,内核中不存在单独的“调度器”模块或者例程一一调度代码散布在内核中凡是会发生与调度相关的事件的各处。执行这些任务的例程合起来称为内核的“分发器(dispatcher)”。下面的事件可能要求线程分发:
- 一个线程变成就绪执行状态时一一例如,一个线程已经被新建起来了,或者刚刚从等待状态中释放出来
- 一个线程离开了运行状态,这可能有以下的原因一一一个线程的时间限额结束了,或者线程终止了,或者线程放弃执行,或者进入了等待状态。
- 一个线程的优先级改变了,可能是由于一个系统服务调用的原因,也可能是因为Windows本身改变了优先级值。
- 一个线程的处理器亲和性改变了,因而它不再在当前运行的处理器上运行了。
在以上每一个交汇处,Windows必须确定接下来该哪个线程运行,如果这个操作适用的话否则就要确定用哪个逻辑处理器来运行这个线程。当一个逻辑处理器选择了一个新的线程来运行时,它总是会执行一次环境切换,切换到该线程中。环境切换是指这样一个过程:将当前正在运行的线程的易失性处理器状态保存起来,并装入另一个线程的易失性状态,然后开始此新线程的执行。
正如前面已经说明过的,Windows在线程粒度上进行调度。
你如果能这样想那就对了:进程并不运行,它只是提供资源和一个环境,让它的线程可以在此环境中运行。因为调度决定是严格在线程的基础上做出的,所以,无须考虑一个线程属于哪个进程。例如,如果进程A有10个可运行的线程,进程B有2个可运行的线程,并且这12个线程在相同的优先级上,那么,理论上讲,每个线程将接收到1/12的CPU时间–Windows不会将50%的CPU时间给进程A,其余的50%给进程B。
优先级别
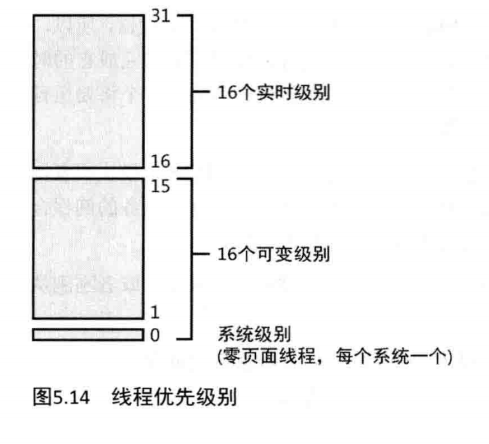
为了理解线程调度算法,你首先必须理解Windows所使用的优先级别。如图5.14中所示的Windows在内部使用32个优先级别,范围从0至31。这些值划分如下
- 16个实时级别(16至31)
- 16个可变级别(0至15),其中级别0保留给零页面线程(zero page thread)。
线程的优先级别是从两个不同的角度来分配的: WindowsAPI和Windows内核。WindowsAPI首先根据进程创建时所分配的优先级类别来组织线程(数字代表能被内核识别的内部PROCESS_PRIORITY_CLASS 索引):实时(4)高(3)普通之上(7)普通(2)普通之下(5)空闲(1)。然后分配这些进程内部单个线程的相对优先级。这里数字代表了应用于进程基本优先级的差值:时间关键(15)最高(2)、普通之上(1)普通(0)普通之下(-1)最低(-2)以及空闲(-15)。
在WindowsAPI中,每个线程都有一个基本优先级,它是其进程优先级类别和相对线程优先级的一个函数。在内核中,进程优先级类别通过PspPriorityTable表和前面讲过的PROCESS_PRIORITY_CLASS索引值,转换成一个基本优先级,这些优先级分别被设为4、8、1314、6和10。(这是一个固定的、不可更改的映射。)然后,基本的线程优先级被作为一个差值加到基本的进程优先级上。例如,一个“最高”优先级的线程会得到比它的进程的基本优先级高2级的线程基本优先级。
从windows优先级到Windows内部的数值优先级的映射关系如表5.3所示
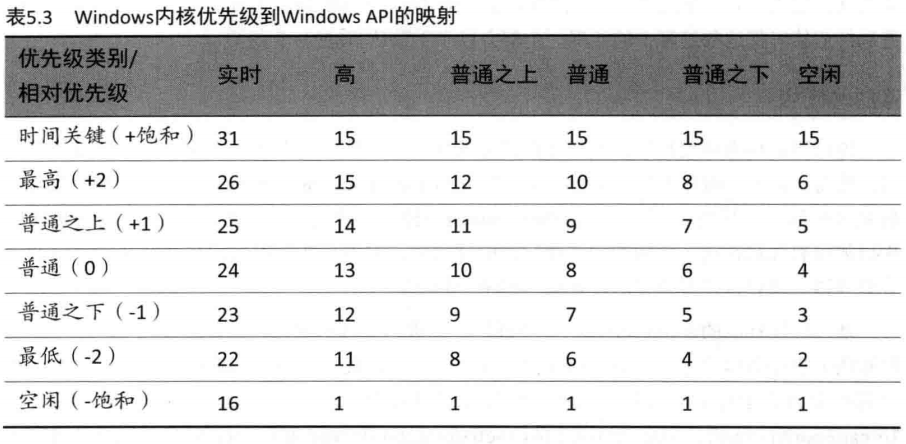
你会发现“时间关键”和“空闲”线程优先级分别保持它们的值,不受进程优先级类别的影响(除非它是“实时”)。这是因为WindowsAPI向内核请求优先级的饱和值,它实际的做法是传入16或-16作为请求的相对优先级(而不是15或-15)。然后,内核将它识别为对饱和的请求,并且KTHREAD的Saturation域(“饱和”域)被置位。这导致,对于正的饱和,线程将收到它的优先级类别中允许的最高的优先级(动态优先级或实时优先级);对于负的饱和,则是允许的最低值。此外,将来如果还有请求要求更改它的进程的基本优先级,这些线程的基本优先级将不再更改,因为在处理代码中饱和的线程是被跳过的。
虽然一个进程只有一个基本优先级值,但是,每个线程有两个优先级值:当前的和基本的。调度决定是根据当前优先级来做出的。正如在下一节关于优先级提升 (priority boost)的介绍中所说的那样,在特定的情况下,系统在很短的周期内,会在动态范围(1至15)之内增加线程的优先级。Windows从来不会在实时优先级范围内(16至31)调整线程的优先级,所以,它们的基本优先级和当前优先级总是相同的。
一个线程的初始基本优先级是从进程的基本优先级继承得来的。在默认情况下,一个进程从创建它的进程那里继承得到基本优先级。这种行为可以在CreateProcess函数中被改变,或者使用命令行start命令也可以改变。在进程被创建以后,也可以通过使用SetPriorityClass函数或者暴露了同样功能的各种工具,比如任务管理器和进程管理器(在进程上右键单击,然后选择一个新的优先级类别),来改变它的优先级。例如,你可以降低一个CPU密集型进程的优先级,使它不会妨碍正常的系统行为。改变一个进程的优先级,也改变了线程优先级向上或向下,但它们的相对设置仍然不变。
通常,面向用户的应用程序和服务以“普通”基本优先级启动,因此它们的初始线程通常在优先级8上执行。不过,一些Windows系统进程(例如会话管理器、服务控制管理器和本地安全认证进程)有一个比“普通”的默认值(8)略高一点的基本进程优先级。这个比默认值更高的值能确保这些进程中的线程,全都会以高于默认值8的优先级启动。
实时优先级
你可以对任意应用程序的线程升高或降低优先级,只要这个优先级在动态优先级的范围内。然而,你必须拥有“升高调度优先级”(increasescheduling priority)特权才能够进入实时优先级的范围。请注意,许多重要的Windows内核模式系统线程运行在“实时”优先级范围,所以如果有线程在这一范围的优先级运行时间过多,它们可能阻碍关键的系统功能(例如内存管理器、缓存管理器或其他设备驱动程序中的功能)。
通过使用标准的WindowsAP1,一个进程一旦进入实时范围,它所有的线程(即使是空闲级别的)也必须运行于实时优先级中的一个级别上。因此,只通过标准接口是不可能在一个进程中混合有运行于实时和动态两种优先级的线程的。这是因为SetThreadPriority API使用ThreadBasePriority信息类别调用原生的NtSetlnformationThread API,而该信息类别只允许在同一范围中指定优先级。而且,这一信息类别还只允许在所识别的WindowsAPI差值-2到2之间(外加“实时”和“空闲”改变优先级,除非该请求来自CSRSS或者一个实时的进程。换句话说,一个实时进程并不能选择16到31之间的线程优先级中的任意一个:即使使用了标准WindowsAPI的相对线程优先级,也只能设置为前面展示的那张表里的多个值中的一个。
然而,通过使用ThreadActualBasePriority信息类别调用上述API,内核提供给线程的基本优先级可以被直接设置,包括实时进程的动态范围优先级。
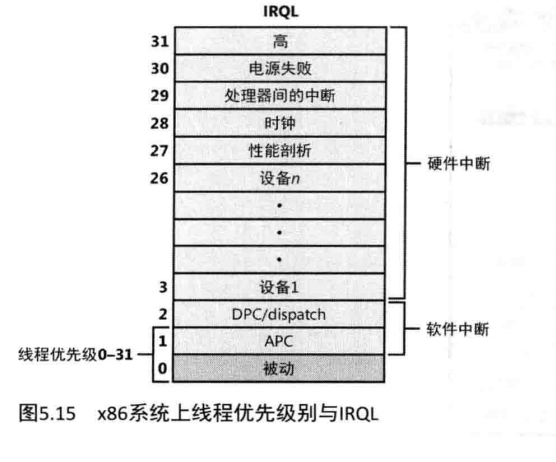
注如图5.15所示,里面显示了中断请求级别(IRQL),虽然Windows有一系列被称为“实时”的优先级,但它们不是通常意义上的“实时”定义。这是因为,视窗没有提供真正的实时操作系统的基础设施,例如可保证的中断延迟,或者一种让线程获得一段可保证的执行时间的途径。
中断级别与优先级
如图5.15所示,32位系统中的中断请求级别(IRQLS),线程通常运行于IRQLO(称为被动级别(passive level),因为此时没有中断在进行,也没有中断被阻塞)或IRQL1(APC级别)(要了解Windows如何使用中断级别,请参见第3章。)用户模式代码总是运行在IRQLO。因此没有一个用户模式线程能阻塞硬件中断,无论它的优先级多高(虽然高优先级、实时的线程可能阻塞重要的系统线程的执行)。
在内核模式运行的线程,虽然初始时被调度于被动级别或APC级别,但之后可以把IRQL提升到更高的级别一一比如,在执行一个包含线程分发、内存管理,或输入/输出的系统调用的时候。如果一个线程把它的IRQL提升到Dispatch (分发)级别或更高,那么在它所在的处理器上就不再发生更多的线程调度行为,直到它把IRQL降到低于Dispatch级别为止。一个执行于Dispatch或更高级别的线程在它所在的处理器上,将阻塞线程调度器的活动,并避免线程环境切换。
如果一个在内核模式执行的线程运行着一个特殊的内核APC,它可以运行在APC级别:或者它可以临时地提升IRQL到APC级别以阻塞其他特殊的内核APC的递交。(有关APC的更详细信息,请参见第3章。)但是,执行于APC级别不会改变该线程与其他线程之间的调度行为:它只影响目标为该线程的内核APC的递交行为。事实上,一个执行于内核模式APC级别的线程,面对一个优先级更高、执行于用户模式、被动级别的线程时,也会被抢占。
使用工具来操作优先级
可以使用任务管理器和进程管理器(Process Explorer),来改变(或查看)基本的进程优先级。通过进程管理器,你可以杀掉一个进程中单独的线程。当然,这种做法应该绝对小心。利用性能监视器、进程管理器和WinDbg,你可以查看单独的线程优先级。增加或者降低一个进程的优先级可能会非常有用,但是,调整一个进程内部单独线程的优先级通常并没有意义,因为只有一个人完全理解了该程序(或者说,通常只有应用程序的开发人员自己),才能够理解该进程内部各个线程之间的相对重要性。
为一个进程指定起始优先级类别的唯一途径是,在Windows命令提示符下使用start命令如果你想要让一个程序每次启动的时候都有一个指定的优先级,那么,你可以定义一个快捷方式来使用start命令,并且以cmd/来开始这一命令。这样会运行命令提示窗口,执行命令行中的命令,然后终止命令提示窗口。例如,为了以低的进程优先级来运行Notepad,快捷方式命令应该是cmd/cstart /low notepad.exe。
Windows系统资源管理器
Windows Server2008R2企业版 (Enterprise Edition)和Windows Server 2008 R2数据中心版(DatacenterEdition)包含一个称为Windows系统资源管理器(WSRM,Windows System ResourceManager)的可选安装组件。它使得管理员可以配置一些策略,在这些策略中指定进程的CPU利用率、亲和性设置和内存限制(物理的和虚拟的)。而且,WSRM可以生成资源利用报告,用于客户的服务等级协议(SLA,service-levelagreement)中的记账和核查。
这些策略可以应用于特定的应用程序(通过映像文件名匹配的方式,可以包含特定的命令行参数,也可以不包含命令行参数)、用户或者组。管理员还可以安排这些策略的作用时间,可以让它们在特定的时间段内生效,也可以一直有效。
当你设置了一个资源分配策略来管理某些特定的进程以后,WSRM服务监视这些被管理进程的CPU消耗情况,当这些进程不符合其预设的CPU分配方案时,调整它们的基本优先级。
物理内存的限制是这样来实现的:通过SetProcessWorkingSetSizeEx函数来设置一个硬性的工作集最大值。而虚拟内存限制则是通过该服务检查这些进程所消耗的私有虚拟内存来实现的(有关这些内存限制的详细解释,请参见本书下册中的第10章)。WSRM可以被配置成:当此限制被超过时,或者杀掉进程,或者在事件日志中写一条记录。通过这种行为,我们可以在一个进程消耗掉系统中所有可用的已提交(committed)虚拟内存以前检测它的内存泄漏。注意,WSRM内存限制并不适用于AWE (Address Windowing Extensions,地址窗口扩展)内存大页面内存,或者内核内存(非换页的或者换页的内存池)。
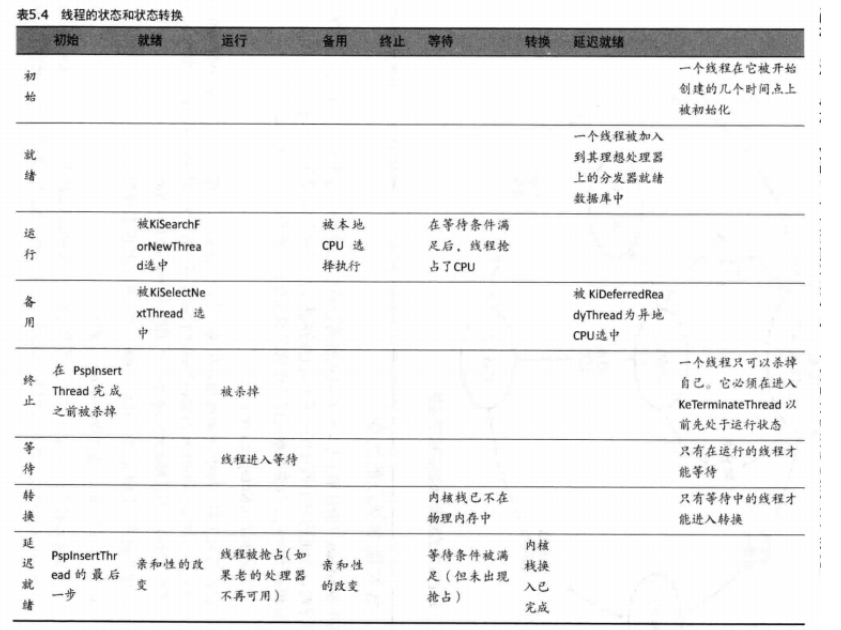
线程状态
在你完全弄清楚线程调度算法以前,你需要理解一个线程可能进入的各种执行状态。这些线程状态如下。
-
就绪(Readv)处于就绪状态中的线程正在等待执行(或在一次等待后准备好被换入)。当分发器需要找一个线程来执行时,它只考虑就绪状态中的线程。 -
延迟的就绪(deferred ready)这种状态用于那些已经被选中要在某个特定的处理器上运行,而尚未被调度的线程。引入了这一新的状态以后,内核可以使调度数据库被系统全局范围内锁住的时间变得最短。 -
备用(Standby)处于备用状态中的线程已经被选中,接下来将在某个特定的处理器上运行。当正确的条件满足时,分发器执行一次环境切换,切换到该线程上。对于系统中的每个处理器,只能有一个线程可以处于备用状态。请注意,一个线程真正被执行以前,它可能会从备用状态中被抢占掉(比如,在备用线程开始执行以前,一个更高优先级的线程变得可以运行了)。 -
运行(Running)一旦分发器将环境切换到一个线程,于是,该线程即进入运行状态,并开始执行。该线程一直执行下去,直到它的时限结束(并且同一优先级上的另一个线程准备运行)、它被一个更高优先级的线程抢占掉、它终止、它放弃执行,或者它自愿进入等待状态。 -
等待(Waiting)一个线程可以通过几种方法进入到等待状态中:它可以自愿等待一个对象以便同步其执行过程、操作系统可以代替该线程进入等待(比如为了解决一个换页I/0),或者环境子系统可以指示该线程自行挂起。当线程的等待结束时,根据优先级的不同,该线程或者立即开始运行,或者被回转到就绪状态。 -
转换(Transition)如果一个线程已经准备好执行,而它的内核栈被换出了内存,那么该线程进入转换状态。一旦它的内核栈被换回到内存中,该线程将进入就绪状态。终止(Terminated)当一个线程完成执行时,它进入终止状态。一旦该线程被终止,执行体线程对象(位于非换页内存池中的用来描述该线程的数据结构)可能已被释放,可能还没有被释放(关于何时删除该对象,对象管理器会设置相应的策略)。 -
初始(Initialized)当一个线程被创建时,内部使用此状态。
表5.4描述了线程的状态转移,而图5.16显示了一个简化版本。(这里显示的数值代表了线程状态性能计数器的值。)在简化版本中,就绪、备用、延迟的就绪这三个状态用一个状态代表。这反映了这样一个事实,即“备用”和“延迟的就绪”是调度器例程使用的临时的保留状态。这些状态几乎总是拥有非常短暂的生命;在这些状态中的线程总是快速地转换到“就绪”“运行”或“等待”状态。本节后面介绍了每一个状态转移所涉及的细节情况。
分发器数据库
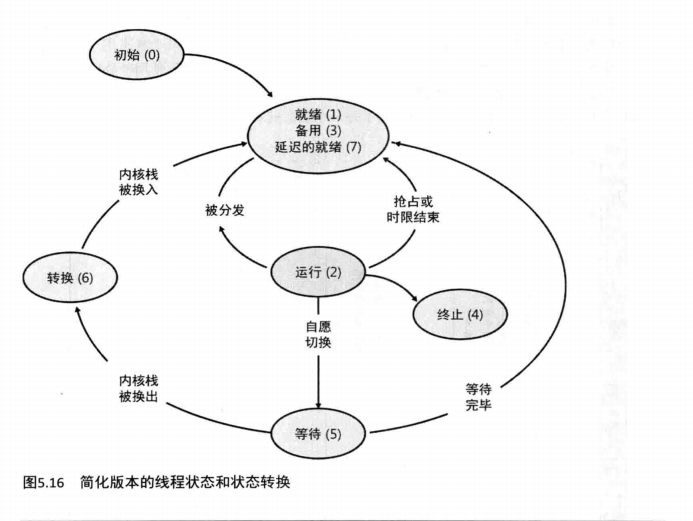
为了做出有关线程调度的各种决定,内核维护了一组数据结构,它们合起来称为分发器数据库 (dispatcher database),如图5.17所示。分发器数据库跟踪记录了哪些线程正在等待执行,哪些处理器正在执行哪些线程。
为了改善可伸缩性,包括线程分发并发性,Windows多处理器系统拥有每处理器的分发器就绪数据器,如图5.17所示。这样,每个CPU可以检查它自己的就绪队列来找到下一个要运行的线程,而不必对系统范围的就绪队列上锁。
每处理器的就绪队列,以及每处理器的就绪摘要信息,都是处理器控制块(PRCB,proessorcontrolblock)的一部分。(要想查看PRCB中的域,请在内核调试器中运行dtnt!_prcb命令。)我们下面要讨论的每个组成部分的名称(用斜体表示)指的是PRCB结构的成员域。
分发器就绪队列(readyqueue)(DispatcherReadyListHead)包含了那些处于就绪状态、正在等待被调度执行的线程。32个优先级中的每一个都有一个队列。为了更加快速地选择一个线程来运行或抢占,Windows维护了一个32位的掩码,称为就绪摘要 (ready summary)
(ReadySummary)每一位一旦被设置,就表示对应的优先级的就绪队列中存在一个或多个线程。(位0代表优先级0,依此类推。)
Windows并不直接扫描每个就绪队列来判断它是否为空(这会让调度决定所花费的时间依赖于不同优先级线程的数量),而是采用一条原生的处理器指令,作一个位扫描,以找到最高的那个被设置的位。这个操作使用一个常数时间,而与就绪队列中线程的数量并无关系,这就是为什么你有时会看见Windows的调度算法被称作0(1)算法或常数时间算法。
在单处理器系统上,分发器数据库是通过将IRQL提升到DISPATCH LEVEL (DPC/Dispatch级别)来同步的(关于中断优先级别的说明,请参见第3章中的“陷阱分发”一节)。按照这种方法来提升IRQL,可以防止其他的线程打断线程分发过程,因为在正常情况下线程运行在IRQLO或者1上。在一个多处理器系统上,除了提升IRQL以外,还需要做更多的事情,因为在同一时刻,每个处理器都可以提升到此IRQL上并试图在分发器数据库上进行操作。关于在多处理器系统上Windows如何对分发器数据库进行同步访问,请参考本章后面的“多处理器系统”一节中的介绍。
时限
正如本章前面多次提到的,时限是指一个线程在“Windows检查是否有另一个同样优先级别的线程正在等待运行”之前所获得运行的时间长度。如果一个线程完成了它的时限,并且在它的优先级上没有其他的线程,那么,Windows允许该线程再运行另一个时限。
在客户版本的Windows上,在默认情况下,线程运行2个时钟间隔;在服务器系统上,在默认情况下,线程运行12个时钟间隔(后面我们将会介绍如何改变这些值)。之所以在服务器系统上默认值更长一些,是因为要使环境切换的次数尽可能地减少。有了一个长的时限以后,如果服务器应用程序一旦接收到客户请求而被唤醒,则它有更好的机会在时限结束以前完成此请求,并回到等待状态。
时钟间隔的长度随着硬件平台的不同而有所不同。时钟中断的频率取决于HAL,而不是内核。例如,大多数86单处理器系统的时钟间隔是10毫秒左右(Windows已不再支持此类机型因此放在这里只是作为一个例子),而大多数x86和x64多处理器系统则是15毫秒左右。这一时钟间隔值保存在内核变量KeMaximumincrement中,它的单位是百纳秒。
系统使用处理器周期数为线程运行时间记账,因此,虽然线程运行的时间仍是时钟间隔的整数倍,系统却并不使用时钟间隔的数量作为主要依据来衡量一个线程运行了多少时间,或它是否用完了它的时限。而是,系统在启动时计算好一个时钟间隔所等价的处理器时钟周期数(这一数值保存在内核变量KiCyclesPerClockQuantum中)。计算过程是把处理器速度的赫兹数(每秒的CPU周期数)乘以单个时钟间隔所对应的秒数(基于前面讲过的
KeMaximumIncrement值)这样的记账方法引起的结果是,线程实际上并不是根据时钟间隔的整数倍来运行完一个时限。而是,它们运行一个时限目标(quantum target),这是一个估计值,代表线程用了多少个CPU时钟周期后会被抢占。这一目标值会是时钟间隔等价的处理器周期数的整数倍。这是因为,正如你之前所见到的,每时限的时钟周期数是和时钟间隔频率相关的。你通过下面的实验可以检查实际的时钟间隔。另一方面,因为处理中断所用的时间不被记录为线程的时间,实际使用的时钟时间可能会更长些。
时限计算
每个进程的进程控制块(KPROCESS)中都有一个时限重置值。当在进程内创建新线程时就会把该值复制给线程控制块 (KTHREAD)。将来给一个线程分配一个新的时限目标时,就会用到该值。时限重置值的存储形式是时限单元 (quantum unit)的一个整数倍数;将它再乘以每时限单元的时钟周期数,就得到了时限目标值(quantum target)。
一个线程的运行过程中,在各种不同的事件(环境切换、中断,以及特定的调度决策)发生时,它的时限都会被减少。如果在一个时钟间隔中断发生时,已使用的CPU时钟周期数已达到(或已超过)时限目标,则会触发时限结束处理过程。如果在同一优先级上另外一个线程正在等待运行,则将环境切换到就绪队列中的下一个线程中。
在内部,此时限单元值被保存为时钟嘀嗒的1/3(因此一个时钟嘀嗒等于3个时限单元)。这意味着,在客户版本的Windows系统上,默认情况下,线程的时限重置值为6(23),而在服务器系统上,时限值为36(123)。由于这个原因,在前面讲到过的KiCyclesPerClockQuantum的值的计算中,在得到每时钟嘀嗒的CPU时钟周期数后,还要除以3才得到最终结果。
时限的内部存储形式之所以是一个时钟嘀嗒的分数,而不是它的倍数,是因为要允许在等待完成时可以部分地减少时限(在Windows Vista之前的版本上是如此)。之前的版本使用了时钟间隔定时器来计算时限是否用完。如果没有这个修正,那么线程的时限有可能永远不被减少。举例来说,如果一个线程先运行,再进入等待状态,再运行,再进入另一个等待状态,但在时钟间隔定时器激发的时候它总也不是当前运行的线程,那么系统永远也不会从它的时限中扣除它运行的时间。因为线程现在使用CPU时钟周期而不是时限单元来进行时间计算,而且时限值也不再依赖时钟间隔定时器来定义,这些修正就不再必要了。
控制时限
你可以为所有的进程改变线程时限,但是你只能选择两种设置之一:短设置(2个时钟嘀嗒,客户机的默认设置),或者长设置 (12个时钟嘀嗒,服务器系统的默认设置)。
注 在运行长时限的系统上,通过使用作业对象,你可以为作业中的进程选择其他的时限值。有关作业对象的更多信息,请参见本章后面的“作业对象”一节。
要想改变时限设置,请右键单击桌面上的“Computer(电脑)”图标,选择“Properties(属性)”,(或者到控制面板中,打开“System(系统)”设置小程序),单击“AdvancedSystemSettings(高级系统设置)”链接再单击“Advanced(高级)”标签页,然后在“Performance(性能)”区域内单击“Settings(设置)”按钮,最后再单击“Advanced(高级)”标签页。你将会看到如图5.18所示的对话框。
“Programs(程序)”设置指定了使用短的、可变的时限一一这是Windows客户版本的默认设置。如果你在Windows服务器系统上安装了终端服务,并且将该服务器配置成应用服务器那么,这一设置将会被选中,因而终端服务器上的用户将可以与他们在桌面系统或客户系统上惯有的时限设置相同。如果你正在运行WindowsServer,并把它作为你的桌面操作系统,那么你也可以手工选择这一设置。
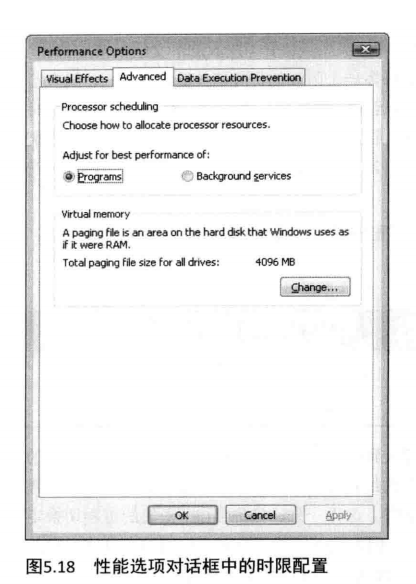
“BackgroundServices(后台服务)”选项指定了使用长的、固定的时限一一这是WindowsServer系统的默认设置。在一台工作站系统上你若要选择这一设置,则唯一可能的理由是,你将这台工作站用做一个服务器系统。然而,因为对这一选项的改变会立即生效,如果机器即将运行一个后台的/服务性的工作任务,那么使用这个设置也是合理的。例如,如果一个长时间运行的任务,如计算、编码或建模模拟,需要运行一晚上的话,可以在晚上选择“BackgroundServices”模式,早上再把系统设置回“Programs”模式。
最后,因为“Programs”模式启用了可变的时限,我们现在来解释一下这些时限的变化是受什么因素控制的。
可变的时限
当可变的时限被启用时,可变时限表(PspVariableQuantums)的内容被载入PspForegroundQuantum表中,该表由PspComputeQuantum函数所使用。它的算法将根据进程是否是一个前台进程(这是指,它是否包含桌面上前台窗口所属的那个线程),来选择适当的索引值指向表中的时限。如果不是这种情况,那么索引值0会被选中,它对应于前面讲的默认线程时限。如果它是一个前台进程,这一索引将等于优先级分离 (priority separation)值。优先级分离值决定了调度器将应用于前台线程的优先级提升(在本章下文的一节中描述)的程度,于是它就联合了对时限值的合理扩展:每多一个附加的优先级(最多有2级),就多给线程一个默认时限。例如,一个线程得到了一级优先级的提升,就同时会得到一个额外的时限。默认情况下,Windows对于前台进程,会使用最大可能值提升其优先级,这意味着优先级分离值将是2,因此会选择在可变时限表中的索引2,导致线程得到2个额外时限,总共拥有3个默认时限。
表5.5描述了从时限索引和正在使用的时限配置出发,所选择的确切的时限值 (请记住,这是用时钟嘀嗒的1/3作为单位的)。
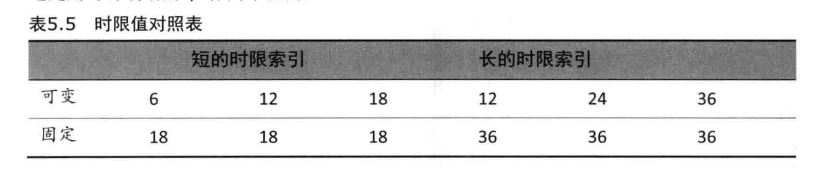
因此,在一个客户系统中,当一个窗口被切换到前台,包含前台窗口所属线程的进程中的所有线程将会得到默认时限的3倍:前台进程中的线程运行6个时钟嘀嗒的时限,而其他进程中的线程获得默认的客户时限值,即2个时钟嘀嗒。这样一来,当你将CPU密集的进程切换走后,新的前台进程将按比例得到更多的CPU时间,因为它的线程运行时,它们将会有比后台线程更长的单次运行时间(这里再次假设前台和后台线程的优先级是一样的)。
时限设置注册表值
前面介绍的用来控制时限设置的用户界面实际上修改了注册表值HKLM\SYSTEM\CurrentControlSet\ControPriorityControWin32PrioritySeparation。除了指定线程时限的相对长度(短或长)以外,此注册表值也定义了是否要使用可变的时限,以及优先级分离(正如你已了解的,当可变时限启用时,它决定了时限表中的时限索引)。此值包含了6位,分成3个2位域,如图5.19所示。
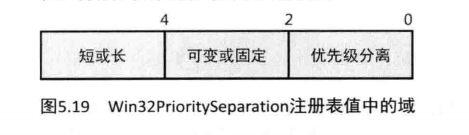
图5.19中显示的域定义如下:
- 短或长 设置为1指定长时限,2指定短时限。0或者3表明将使用适合系统的默认设置(对于客户系统为短,对于服务器系统为长)。
- 可变或固定 设置为1意味着启用可变时限表(基于前面讲的“可变的时限”中描述的算法)。设置为0或者3意味着将使用适合系统的默认设置(对于客户系统是可变的,对于服务器系统是固定的)。
- 优先级分离该域(存储在内核变量PsPrioritySeparation中)定义了优先级分离(该值至多为2):它的含义在“可变的时限”一节中已经解释过了。
注意,当你在使用前面所讲述的Performance Options(性能选项)对话框时,你只能从两种组合中选择其一:短时限且前台时限乘3,或者长时限但前台线程的时限不变。然而,通过直接修改Win32PrioritySeparation注册表值,你可以选择其他的组合。
请注意,对于运行于“空闲”优先级类别的进程中的线程来说,它们总是只能得到单个线程时限(2个时钟嘀嗒),而不会受任何时限配置设置值的影响,无论是默认设置,还是通过注册表设置的值。
在配置为应用服务器的WindowsServer系统上,Win32PrioritySeparation注册表项的值将是十六进制的26,等于在“Performance Options(性能选项)”对话框中“Optimize Performancefor Programs(为应用程序优化性能)”选项设置的注册表值。此设置选择的时限和优先级的提升行为类似于Windows客户系统,正适合于主要用于宿纳面向用户应用程序的服务器。
在Windows客户系统和未被配置为应用服务器的服务器系统上,Win32PrioritySeparation注册表项的初始值将是2。这个设置提供了 值给“短或长”以及“可变或固定”域,让它们依赖于系统中这些选项的默认行为(依赖于它是一个客户系统或是一个服务器系统)。但它提供了2这个值给“优先级分离”域。一旦使用了“Performance Options (性能选项)”对话框修改了该注册表值,就无法把它变成原始的值了,除非直接修改注册表。
优先级提升
Windows调度器会通过一个内部的优先级提升机制,周期性地调整线程的当前优先级。在很多情况下,它这样做是为了减少各种延迟(就是说,让线程更快地响应它们等待着的事件)以及提高响应能力。其他情况下,它应用这些提升以避免优先级倒置和饥饿等情形。
以下是本节中将讨论的一些优先级提升的情形:
- 由于调度器/分发器事件而提升(减少延迟)。
- 由于I/O操作完成而提升(减少延迟)。
- 由于UI输入而提升(减少延迟/提高响应)。
- 由于线程等待某个执行体资源的时间太长而提升(避免饥饿)。
- 一个准备运行的线程在相当一段时间内没有被运行过而提升(避免饥饿和优先级反转)。
然而,如同任何一个调度算法一样,这些调整不是完美的,它们不可能让所有的应用程序都获益。
注Windows从来不会提升实时范围(16至31)内的线程的优先级。因此,相对于实时范围内的其他线程而言,调度过程总是可预测的。Windows假定:如果你正在使用实时的线程优先级,那么你知道你在做什么。
Windows的客户版本也包含另一个伪提升 (pseudo-boosting)机制,它发生于多媒体回放过程。与其他由内核直接作用的优先级提升不同,多媒体回放的优先级提升实际上是通过一个称为多媒体类调度器服务(MultiMedia Class SchedulerService) 的用户模式服务管理的,但它们并非真正的提升一一该服务仅仅根据需要重新设置线程的基本优先级(通过调用用户模式的原生API来修改线程的优先级)。因此,有关提升的规则,对它而言完全不适用。我们将先描述典型的那种由内核管理的优先级提升,然后再谈论MMCSS和它所做的“提升”
由于调度器/分发器事件而提升
当一个分发器事件发生时,KiExitDispatcher 例程会被调用,它的任务是调用KiProcessThreadWaitList处理延迟就绪列表,然后调用KiCheckForThreadDispatch检查本地处理器上是否有任何线程不应该被调度。只要这种类型的事件发生,调用者就能指定线程上应该应用哪种类型的提升,以及提升应该关联的优先级增量。下面的情形在AdiustUnwait分发事件时会被考虑,因为它们处理一个正在进入信号激活状态的分发对象,它可能会唤醒一个或多个线程:
- 一个APC(异步过程调用)被加入线程的APC队列中。3
- 一个事件被设置或被触发
- 一个定时器被设置,或者系统时间已改变,导致定时器必须被重置。
- 一个互斥体被释放或被放弃。
- 一个进程退出了。
- 一个项被加入一个队列,或者一个队列被清空。
- 一个信号量被释放。
- 一个线程被警告、被挂起、被恢复运行、被冻结或被解冻。
- 一个UMS(用户模式调度)主线程正等待着切换到一个被调度的UMS线程
对于关联到公共API的调度事件(例如SetEvent),被应用的提升增量由调用者指定。Windows推荐开发人员使用一些特定的值。我们会在后面谈到它们。对于警告,应用一个值为2的提升,因为与警告相关的API没有一个参数允许调用者指定一个自定义的增量。
调度器也有两个特殊的AdjustBoost分发事件,它们是锁的拥有权优先级机制的一部分。这些提升试图修复下面的情形:当调用者以优先级X拥有着一个锁,最后把锁释放给一个等待的线程,它的优先级 <=X。在这一情况下,新拥有锁的线程必须等待它被调度的机会(如果运行于优先级X的话),或更糟,它可能甚至没有运行的机会,如果它的优先级低于X的话。这样一来,释放锁的线程可能继续它的运行,尽管它应该让新的拥有者线程被唤醒并得到处理器的控制权。下面的两个分发器事件会引发一个AdjustBoost分发器调用并退出:
- 一个事件通过KeSetEventBoostPriority接口被设置,而它由ERESOURCE读者-写者内核锁使用。
- 一个事件通过KeSignalGateBoostPriority接口被设置,而它由释放门锁时的各种内部机制使用。
等待后提升
等待后提升试图减少“线程从一个对象发送了信号而被唤醒,直到它真正开始执行以处理此等待结束情况(从而进入运行状态)”之间的延迟。因为线程等待着的事件可能提供一些信息,例如当前可用内存的状态信息,因此在线程处于就绪状态的这段时间里,这一状态最好不会悄悄改变,这对线程来说是重要的一一否则,该信息在线程开始运行时就成了无用的或不正确的信息了。
各个Windows头文件指定了内核模式API如KeSetEvent和KeReleaseSemaphore等的调用者应该使用的推荐值,即MUTANTINCREMENT和EVENT INCREMENT等的定义。这些定义在头文件中总是被设为1,因此,可以安全地假定,绝大多数对这些对象的等待结束后会产生值为1的提升。在用户模式API中,无法指定一个增量;原生的系统调用如NtSetEvent中也没有指定这种提升的参数。取而代之的是,当这些API调用底层的Ke接口时,它们自动使用默认的INCREMENT定义。这也是互斥体被放弃时,或因系统时间改变而引起定时器被重置时的情况:系统会使用默认的提升,相当于互斥体被释放时通常会应用的那种。最后,APC提升则完全取决于调用者。很快你就会在下面看到有关I/0完成时,APC提升的使用场景。
注 有一些分发器对象没有与之关联的提升。例如,当一个定时器被设置或过期时,或当一个进程被设置信号时,没有提升会被应用。
所有这些+1的提升试图解决初始问题的方法都是:假定释放和等待的线程都运行于同样的优先级。通过将等待的线程提升一个优先级,该等待的线程将在操作完成时会立即抢占释放的那个线程。不幸的是,在单处理器系统上,如果这一假设不成立的话,提升将起不了多大的作用:如果等待的线程等待在优先级4上,而释放的线程是在优先级8上,等待在优先级5上将不会对减少延迟和强制抢占起多少作用。然而,在多处理器系统上,由于重分配和平衡算法(stealingand balancing algorithms),这个高优先级的线程可能有更高的可能性被另一个逻辑处理器选中。这一现实之所以发生,归因于最初的NT架构中的一个设计选择,就是不跟踪锁的拥有权(除了少量的一些锁以外)。这意味着调度器不能确定到底谁拥有这个事件,以及它是否真的被用作了一个锁。即使使用了锁拥有权的跟踪,拥有权通常也不会被传递,以避免封护效应(convoyeffects)。但下面我们将解释的ERESOURCE情形除外。
但是,对于某些种类的、使用事件或门(gate)作为它们底层同步机制的锁对象,锁拥有权提升会解决那个两难问题。并且,由于你在下面将看到的处理器分布和负载平衡策略,在一个多处理器机器上,就绪的线程可能由另一个处理器取走,并且它所处的高优先级能增加它运行于那个处理器的几率。
出于锁拥有权的提升
因为执行体资源(ERESOURCE)和临界区的锁使用底层的分发器对象,所以,释放这些锁会导致前面讲过的等待后提升。另一方面,因为这些对象的上层实现并不跟踪锁的拥有权,内核可以作一个更具体的决定,通过使用AdjustBoost原因,决定应该应用哪种提升。在这些种类的提升中,Adjustlncrement被设置为: 作释放(或设置)操作的线程的当前优先级,减去任何GUI前台分离提升。并且,在KiExitDispatcher函数被调用以前,KiRemoveBoostThread被事件和门代码调用,以让释放线程返回它的正常优先级(通过KiComputeNewPriority函数)。这一步是必要的,用以避免一种锁封护 (lock convoy)情形:两个线程反复地在互相之间传递锁,得到不断增长的提升。
注意推锁(pushlocks)是一种不公平的锁,因为在争夺的获取路径中,锁的拥有权不是可预测的(而是随机的,与自旋锁相似);它不会因为拥有权而应用优先级提升。这是因为这样做只会增加抢占的发生和优先级的扩散,而这是不必要的,因为锁在被释放后会马上可用(而不通过通常的等待/等待后路径)。
锁拥有权提升和等待后提升的其他方面的区别会在调度器实际应用提升的方法中体现。
本节之后的下一个主题即将讨论它。
IO完成以后的优先级提升
Windows每当特定的/0操作完成时就会赋予临时的优先级提升,这样,那些正在等待I/0的线程将有更多的机会被立即运行,从而尽快完成正在等待处理的任务。尽管你可以从Windows驱动程序工具箱(WDK,Windows Driver Kit)的头文件中找到推荐的提升值(在Wdm.h或Ntddk.h中搜索“#definel0”),但实际的提升值要取决于设备驱动程序(表5.6中列出了这些值)。正是设备驱动程序在完成了一个/0请求时,在对内核函数loCompleteRequest的调用中指定了提升值。在表5.6中,你可以注意到,越是针对那些要求更高响应性的设备的I/O请求,越是有更高的提升值。


注 你可能直观地认为,显示卡或磁盘需要“更好的响应能力”,而不只是提升1。但是,事实上内核是在为延迟尝试作优化;某些设备(以及人类感官输入)对它更敏感而某些次之。给你一个概念吧:声卡期望每1毫秒就有声音数据给它,才能没有跳音地播放音乐,而显示卡只需要每秒24帧的输出,或者说,每40毫秒一帧,只有超过这一时间以后人的眼睛才会注意到跳顺。
正如之前提示的,这些1/0完成后的提升依赖于前一节讲的等待后提升。在本书下册第8章将会深入讲解I/0完成机制。现在,重要的细节是,oCompleteRequest API中的信号发送代码的内核实现方式是,或者通过一个APC(异步I/0的情况),或者通过一个事件(同步I/0的情况)来实现。当一个驱动程序带着一个提升参数,例如IO_DISK_INCREMENT,调用loCompleteRequest以进行一次异步磁盘读的时候,内核会带着那个提升参数,I0_DISK INCREMENT,来调用KelnsertQueueApc。于是,当线程的等待由于APC而被打断时,它就得到一个值为1的提升。请注意,前面那张表中给出的提升值只不过是Microsot的推荐值一一驱动程序开发人员如果选择忽略它们的话,可以自由地去做,而且某些特殊的驱动程序也可以使用它们自己的值。例如,处理一台医学设备发送的超声波数据的驱动程序,必须将新数据的到达通知给-个用户模式的可视化应用程序。它就很可能使用一个值为8的提升,以实现与声卡相同的延迟然而,在绝大多数情况下,由于Windows驱动程序栈的构建方式(同样的,请参见本书下册第8章“I/0系统”以获得更多信息),驱动程序开发人员经常编写小驱动程序(minidrivers)。它们会调用一个Microsoft私有的驱动程序,而它会提供它自己的提升值给loCompleteRequest。例如,RAID或SATA控制器板卡的开发人员通常会调用StorPortCompleteRequest来完成处理它们的请求。这一调用没有任何提升值参数,因为Storportsys驱动程序会在调用内核时填入正确的
值。另外,在较新版本的Windows中,每当一个文件系统驱动程序(通过设置它的设备类型为FILEDEVICE_DISK FILE SYSTEM或FILE DEVICE NETWORK FILE SYSTEM来识别)完成它的请求时,如果驱动程序传入10 NO INCREMENT作为提升值,那么,总是会应用值为IODISK INCREMENT的提升来代替它。因此,这一提升值已经变得不再像是一个建议值,而更像是一个内核强制的要求值了。
等待执行体资源时的提升
当一个线程试图获取一个执行体资源(ERESOURCE:请参见第3章以获得有关内核同步对象的更多信息),而这个执行体资源已被另一个线程以独占方式拥有时,它必须进入一个等待状态,直到那个线程释放该资源。为了减少死锁的风险,执行体以5秒的间隔来做此等待,而不是无时间限制地等待该资源。
在每个这样5秒的末尾,如果资源仍被占有,那么执行体就试图避免CPU饥饿,方法是获取分发器锁,提升占有资源的这一个或多个线程的优先级到14(仅当原占有者线程的优先级低于等待者,并且还没到14的时候),重置它们的时限,然后进行下一次等待。
因为执行体资源既可以被共享,也可以被独占,内核会首先提升独占的拥有者,然后检查共享的拥有者并把它们全部提升。当等待线程再次进入等待状态时,调度器将有希望调度拥有者线程中的一个,该线程将会有足够的时间来完成它的工作并释放该资源。注意这一提升机制仅当资源没有被设置禁止提升 (Disable Boost)标志的时候才会被使用。这个标志可由开发人员选择设置,前提是这里描述的优先级反转机制能与他们对资源的使用方式很好地一起工作。
此外,这一机制也并非完美。例如,如果资源有多个共享的拥有者,执行体把全部这些线程提升到优先级14,会导致系统中突然多出许多高优先级的线程,而且全都拥有完整的时限。虽然初始拥有者线程会先运行(因为它是第一个被提升的线程,因此它会在就绪列表中排在首位),但是其他的共享拥有者也会相继运行,因为等待线程的优先级并没有被提升。只有当所有的共享拥有者已经运行过一次,并且它们的优先级已经被降到了等待线程之下时,等待线程才会得到它去获取资源的机会。因为共享的拥有者在独占的拥有者释放资源时,能马上提高或转换它们的拥有权,将其从共享的变为独占的,所以,此机制有可能无法达到想要达到的目的。
等待以后,前台线程的优先级提升
正如很快要讲到的那样,无论何时,当前台进程中的线程完成了一个等待内核对象的操作时,内核使用PsPrioritySeparation的当前值提升它的当前(而不是基本)优先级(由窗口系统负责确定哪个进程被认为是在前台)。正如在时限控制一节中所讲述的那样,PsPrioritySeparation反映了时限表的索引,用于为前台应用程序中的线程选择时限。然而,在这里,它被用做一个优先级提升值。
这里提升优先级的理由是,为了增强交互式应用程序的响应性一一当前台应用程序完成一个等待时,给它一个小小的提升,它就有更好的机会被立即运行,尤其是当同一优先级上的其他进程可能正处于后台运行的时候。
GUI线程醒来以后的优先级提升
对于包含窗口的线程,它们由于一个窗口活动(比如窗口消息到来)而醒来的时候,会接收到一个额外的提升值2。当窗口系统(Win32ksys)调用KeSetEvent来设置一个事件,因而唤醒一个GUI线程的时候,窗口系统就会应用这种优先级提升。这种优先级提升的理由与上一种类似一-为了更加有利于交互式应用。
因为CPU饥饿而引起的优先级提升
想象下面的情形:你有一个优先级为7的线程正在运行,因而妨碍了一个优先级为4的线程获得CPU时间,然而,一个优先级为11的线程正在等待某一资源,而该资源又被这一优先级为4的线程锁住了;但是,因为位于中间的优先级为7的线程用光了所有的CPU时间,所以,优先级为4的线程永远也不会有足够的时间来做完它所要做的事情,并释放这一阻塞住优先级11线程的资源。Windows该如何来解决这种情形呢?
你已经在前面看到过,对执行体资源负责的执行体代码是这样来管理这种情形的:它把拥有者线程提升,从而它们有机会运行并释放相关的资源。然而,执行体资源只是对开发者可用的许多种同步结构中的一种,因而前面所说的提升功能将无法应用于其他的同步原语。因此,Windows也包含了一个通用的CPU饥饿缓解机制,包含在名为平衡集管理器(balancesetmanager)的线程之中(这是个系统线程,它存在的主要目的是执行内存管理功能,在本书下册第10章中有更详细的描述),成为它功能的一部分。
该线程每秒钟扫描就绪队列一次,查找已在就绪状态(也就是说,还没有被运行)将近4秒钟的线程。如果平衡集管理器找到了这样一个线程,则它将该线程的优先级提升到15,并将这一线程的时限目标设置为3个时限单元对应的CPU时钟周期数。一旦此时限到期,线程的优先级立即被减退到它原来的基本优先级。如果该线程尚未完成时一个更高优先级的线程准备运行了,那么,减退的线程将返回就绪队列中;如果它在该队列中又待上4秒钟的话,则它再次获得另一优先级提升。
平衡集管理器每次运行的时候并不真正扫描所有就绪的线程。为了尽最大可能减少它所用的CPU时间,它只扫描16个就绪线程;如果在一个优先级上还有更多的线程,那么,它记录下这次扫描的位置,因而下一次扫描可以从这里开始。而且,它每次扫描只提升10个线程一一如果它找到了10个线程,而且这些线程都符合这种特殊的优先级提升要求(这也表明了这是一个异常繁忙的系统),那么它在这个点上停止扫描,下次扫描还从这个地方开始。
注 我们前面提到过,Windows里面生成调度决定所花费的时间并不受线程数量影响,而是常数时间,或者说是0(1)。平衡集管理器需要它自己扫描就绪队列,因此这一操作的时间会依赖于系统上运行的线程的数量,并且这一数字越大,就要花费越多的时间去做扫描。然而,平衡集管理器并不被认为是调度器及其算法的一部分。它只是为了增加可靠性而设的一个扩展机制。此外,由于扫描的线程和队列的数量都有个上限,它在性能上的影响已经变得最小,即使是在最坏情况下也是可预测的。
这个算法总能解决这种优先级反转(priorityinversion)的问题吗?不无论如何它都不是完美的。但是,随着时间的推移,CPU匮乏的线程应该能得到足够的CPU时间来完成它们正在处理的事务,并重新进入等待状态。
应用提升的过程
回到KiExitDispatcher中,你已经看到了KiProcessThreadWaitList会被调用,以处理延迟就绪列表中的线程。正是在这个位置,调用者传递的提升信息被处理了。处理的方法是循环遍历每个DeferredReady线程,解除连到它的等待块(wait blocks)的链接(只有活动 (Active)和已略过(Bypassed)的块会被解除链接),然后设置两个内核线程控制块中的关键值:AdjustReason和Adjustlncrement。提升原因(reason)可以是前面见到过的两种原因之一,而增量(increment)则对应提升值。然后,KiDeferredReadyThread被调用:它通过运行两个算法,让线程进入准备执行的状态:时限和优先级选择算法,以及处理器选择算法。前一个算法将会分两个部分为你展示,而后一个算法将在后面一节相关主题中展示。
我们先看一下应用提升的算法,它仅当线程不在实时优先级范围内时才发生。对于一个AdjustUnwait提升,它的前提之一是线程并不在一个非正常的提升过程当中,前提之二是线程并未通过调用SetThreadPriorityBoost禁用提升,也就是说,没有设置过KTHREAD中的DisableBoost标志。另一个在此情形下会禁用提升的情况是,内核意识到线程实际上已经用完了它的时限(但时钟中断还没有被激发过,所以之前还没有被记账),而线程从一次少于两个时钟间隔的等待后醒来。
如果上述情况都不符合,那就会把Adjustincrement的值加到线程当前的基本优先级上,来完成新的线程优先级的计算。此外,如果线程已知属于一个前台进程(意味着内存优先级被没置为MEMORY PRIORITY FOREGROUND,它是由Win32k.svs在输入焦点改变时设置的),那么现在就是优先级分离提升 (PsPrioritySeparation)被应用的时候,此提升值会被加到新的优先级上。这也称作前台优先级提升,我们之前已经解释过了。
最后,内核检查这个计算出的优先级是否高于线程的当前优先级,并且会限制此值不超过15,以避免跨入实时优先级范围。然后,它把这个值设置为线程新的当前优先级。如果已经应用了任何前台分离提升,它把该提升值设置到KTHREAD的ForegroundBoost域,导致一个与分
离提升值相同的PriorityDecrement值。对于AdjustBoost提升,内核检查线程的当前优先级是否低于Adjustlncrement(前面提到过它是设置锁的那个线程的当前优先级),以及线程的当前优先级是否低于13。如果是这样,并且线程的优先级提升没有被禁用,那么Adjustincrement值将用作新的当前优先级,但最高不超过13。同时,KTHREAD的UnusualBoost(非正常提升)域将包含这一提升值,导致一个与锁拥
有权提升值相同的PriorityDecrement值。在PriorityDecrement存在的所有情形下,线程的时限也会被重新计算为等价于只有一个时钟喃嗒的值,这个计算使用KiLockQuantumTarget的值来完成。这保证了前台提升和非正常提升将会在一个时钟嘀嗒后就失去,而不是通常的两个(或其他配置值)。这一点会在下一节中展示。这也会发生在AdjustBoost被请求,但是线程运行于优先级13或14,或者提升被禁用的情况
当这些工作完成以后,AdjustReason现在被设置为AdjustNone
移除提升的过程
提升的移除是在KiDeferredReadyThread中,提升和时限被重新计算,再应用计算结果的时候完成的(就是前一节中讲到过的地方)。这个算法首先检查所做的调整的类型,来作为它的开始。
对于AdjustNone情形,这意味着线程可能是因为抢占而准备好运行的。这种情况下,如果它已经用完它的目标时限,但没有被时钟中断遇到并处理过,线程的时限会被重新计算,前提是线程运行于动态优先级范围。此外,线程的优先级也将被重新计算。对于一个非实时线程的AdjustUnwait或AdjustBoost情形,内核会检查线程是否已经悄悄地用完了它的时限(正如在前一节中讲到的)。如果已经用完了,或者线程运行于基本优先级14或更高,又或者PriorityDecrement存在,而且线程已经完成了一次超过两个时钟嘀嗒的等待,线程的时限和它的优先级都会被重新计算。
优先级重新计算发生在非实时的线程上。它的计算方式是把线程的当前优先级减去它的前台提升值,再减去它的非正常提升值(后面这两项的组合就是PriorityDecrement),然后再减掉1。最后,这个新的优先级的下界再由基本优先级限定一下(即两者中取较大值),而当前存在的任何优先级减少值 (priority decrement)被清零(清除非正常提升和前台提升)这意味着在锁拥有权提升,或在前面解释过的其他任何非正常提升的情形下,所有的提升现在都已经失去了。另一方面,对于一个常规的AdjustUnwait提升,由于那个减1操作,优先级自然而然地一级一级下降。这个下降最终会停止在基本优先级这个位置,原因就是下界检查。
还有一种情况,提升也必须被移除,这由KiRemoveBoostThread函数完成。这是个提升移除的特例,由锁拥有权提升规则引起。该规则指定了,当设置锁的那个线程把它的优先级让给被唤醒的线程时,必须失去它自己的提升,以避免锁的封护效应。它也被用来撤销由定向的DPC调用引起的提升,以及由ERESOURCE饥饿引起的提升。对于这个例程来说,唯一特殊的细节是,当计算新的优先级时,它会特别小心地处理PriorityDecrement中的前台提升(ForegroundBoost)和非正常提升 (UnusualBoost)部分,以便区分它们,从而维持线程积累的任何GUI前台分离提升。这是windows 7中新引入的行为,它能够保证依赖于锁拥有权提升的线程在前台运行时不会行为怪异,不在前台时也不会行为异常。
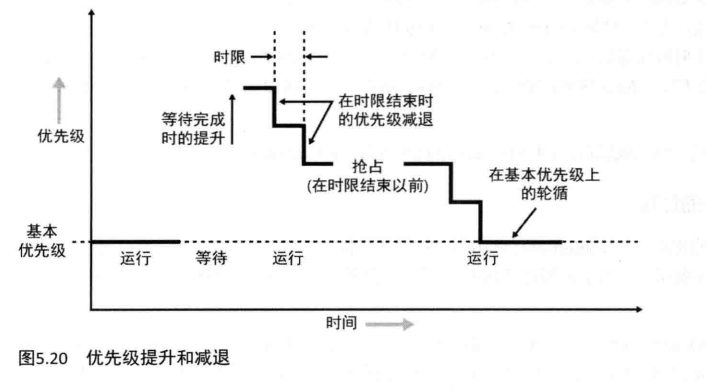
图5.20展示了一个例子:当一个线程经历时限结束时,正常的提升是如何从一个线程中被移除的。
针对多媒体应用程序和游戏的提升
就像你在上一个实验中看到的,虽然Windows的CPU饥饿优先级提升可能足以让一个线程走出长时间的等待状态或潜在的死锁,但它们应付不了CPU密集型程序对资源的要求,比如WindowsMedia Plaver或3D电脑游戏这样的程序。
跳音和其他音频质量问题曾是令过去的Windows用户最感到头疼的问题之一,而Windows的用户模式音频栈也加剧了这一局面,因为它提供了更多抢占的机会。为了解决这一问题,Windows的客户版本引入了一个服务 (叫做MMCSS,在本章前些介绍过了),它的目的是,对于向它注册的应用程序,保证无跳跃的多媒体回放。
MMCSS的工作方式定义了一些任务,包含下面的这些项:
- 音频
- 捕获
- 发行
- 游戏
- 回放
- 专业音频
- 窗口管理器
注: 你能在注册表键HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Multimedia\SystemProfile\底下找到MMCSS的设置,包括一些任务的列表也在那儿(它们可以被OEM修改,以包含其他特定的任务,只要合适的话)。此外,SystemResponsiveness值允许你微调MMCSS,让它保证把多少CPU留给低优先级线程使用。
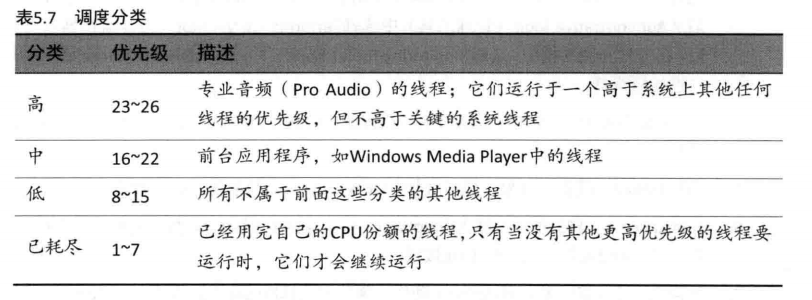
这些任务中的每一个都含有一些信息,表达了任务之间各不相同的各种属性。最重要的条有关调度的属性称为调度分类(SchedulingCategory)`,它是决定注册到MMCSS的线程有多高优先级的主要因素。表5.7显示了各个调度分类。
MMCSS的主要机制把已注册进程的线程的优先级提升到一个能匹配它们的调度分类和分类中的相对优先级的值,并维持可保证的一段时间。然后它把那些线程的优先级降低到“已耗尽”分类;这样一来,系统中非多媒体的其他线程也能得到执行的机会。
默认情况下,多媒体线程能得到可用CPU时间的80%,而其他线程得到20%(这是通过每10毫秒一次的采样来分配的,或者说,每8毫秒加2毫秒)。MMCSS它自己运行于优先级27,这是因为它需要抢占任意专业音频线程,并把它们的优先级降低到“已耗尽”类别的缘故。请注意,内核仍然只是提升了KTHREAD中的值(MMCSS只是做了任何其他应用程序都能做的系统调用),并且,调度器依然控制着这些线程。维持这些线程在机器上几乎不被打断地运行的因素,只是它们的高优先级而已一一因为它们运行在实时范围内,远高于绝大多数用户模式应用程序运行时所在的级别。
前面我们讨论过,改变进程中的相对线程优先级通常并没有意义,并且没有工具允许这样做。这是因为只有应用程序开发人员自己才理解程序中各个线程的重要性。另一方面来说,因为应用程序必须显式地向MMCSS注册,并向它提供有关线程是属于哪个种类的信息,所以MMCSS的确有足够的数据来修改这些线程的相对优先级(并且开发人员也明确知道这件事将会发生)。
然而,MMCSS的功能不仅仅是简单的优先级提升。由于Windows里网络驱动程序和NDIS栈的特性,延迟过程调用(DPC)是用于在收到来自网卡的中断后,把工作推迟执行的一种很常见的机制。因为DPC运行在高于用户模式代码的IRQL(有关DPC和IRQL的更多信息,请参见第3章)上,长时间运行的网卡驱动程序代码还是可能在网络传输过程中打断媒体的播放,或者,举例来说,这种情况也可能发生在玩游戏的时候。
因此,MMCSS也会向网络栈发送一个特殊的命令,告诉它在媒体播放的时候要调节网络包的流量 (throttle network packets)。这种调节机制的设计目标是最大化播放性能,尽管在网络处理能力上会有些许损失(但对于播放过程中通常会执行的网络操作而言,这种损失并不会被注意到,例如,在玩一个在线游戏的时候)。它背后确切的机制并不属于调度器的任何部分,所以我们不在这里详细讨论它。
注:网络流量调节代码的初始实现有一些设计上的问题,会在配有千兆网络适配器的机器上引起严重的网络吞吐量损失,特别是当系统中装有多个适配器的时候(中档主板常见的功能之一).这个问题被Microsoft的MMCSS组和网络组分析了以后,最终得到了解决。
环境切换
一个线程的环境和用于环境切换的过程随着处理器体系结构的不同而不尽相同。一个典型的环境切换需要保存和加载以下的数据:
- 指令指针。
- 内核栈的指针。
- 指向该线程运行所在的地址空间 (该进程的页表目录)的指针
内核把老线程的这些信息保存起来,其做法是:将这些信息压入到当前的(即老线程的)内核模式栈中,更新栈指针,然后将此栈指针保存在老线程的KTHREAD块中。然后,内核栈指针被设置为新线程的内核栈,新线程的环境被加载进来。如果新线程位于不同的进程中,那么,它将新进程的页表目录加载到一个专门的处理器寄存器中,从而使用新进程的地址空间(参见本书下册第10章中关于地址转译的介绍)。如果一个需要被交付的内核APC正在等待处理,则一个IRQL为1的中断就会产生(有关APC的更多信息,请参见第3章)。否则,处理器的控制被传递给新线程中已被恢复的指令指针,于是新线程恢复执行。
调度情形
Windows根据线程优先级来回答“谁该得到CPU?”,但实际上这又是如何做到的呢?下面的小节说明了优先级驱动的抢先式多任务调度是如何在线程级别上完成的。
自愿切换
首先,一个线程可能会通过调用某个Windows等待函数(比如WaitForSingleObject或WaitForMultipleObjects)来等待某个对象(比如一个事件、互斥体、信号量、I/0完成端口、进程、线程、窗口消息,等等),从而进入等待状态,主动放弃对处理器的使用。第3章详细地讲述了有关等待对象的细节。
图5.21显示了一个线程进入等待状态,Windows选择一个新的线程来运行。在图5.21中最上边的块(线程)自愿放弃处理器,所以就绪队列中的下一个线程可以运行(在“运行”这一列中用一圈光环来表示)。虽然从图中来看,放弃处理器的线程的优先级似乎被降低了,但其实不是这样的,它只是被移到了该线程正在等待的对象的等待队列中。
抢占
在这种调度情形中,当一个高优先级的线程变成就绪时,低优先级的线程被抢占。之所以发生这样的情形,有以下两个理由。
- 一个高优先级线程的等待完成了 (另一个线程正在等待的事件发生了)。
- 一个线程的优先级被增加或减低
以上无论哪一种情形,Windows必须确定:当前正在运行的线程是应该继续运行,还是应该被抢占掉,以便让更高优先级的线程运行。
注 用户模式中的线程可以抢占掉在内核模式中运行的线程一一线程当前所在的模式并没有关系。线程优先级是决定因素。
当一个线程被抢占时,它被放到它刚才运行时所在优先级的就绪队列的头部。图5.22显示了这种情形。
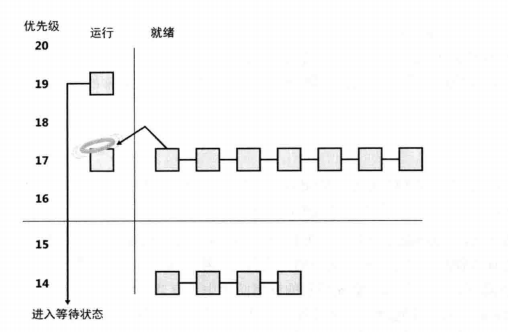
在图5.22中,一个优先级为18的线程从等待状态中醒来,重新拥有CPU,因而使得当前已经在运行的线程(在优先级16)被转移到就绪队列的头部。可以注意到,这个被转移的线程并不是插入到队列的末尾,而是到开始处:当抢占的线程完成了运行以后,被转移的线程可以继续完成它的时限。
时限结束
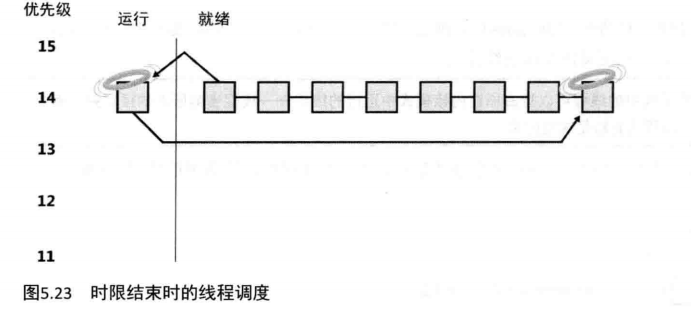
当正在运行的线程用完了它的CPU时限时,Windows必须决定该线程的优先级是否应该被降低,然后决定是否应该调度另一个线程到当前处理器上来。
如果线程优先级被降低,则Windows寻找一个更加合适的线程来调度(例如,这个更加合适的线程是,比当前运行线程的新优先级还要更高的优先级的就绪队列中的一个线程)。 如果线程的优先级没有被降低,并且在同一优先级别的就绪队列中还有其他的线程,那么,Windows从同一优先级的就绪队列中选择下一个线程,并且将原来运行的线程移到该队列的尾部(赋予它新的时限值,并且将它的状态从运行态改变为就绪态)。这一情形如图5.23所示。如果同一优先级的就绪队列中没有其他的线程在等着运行,那么该线程再获得一个时限的运行权。
正如你所见到的那样,Windows并不是简单地依赖于时钟间隔定时器确定的时限来调度线程,而是使用了一个精确的CPU时钟周期数来维护时限目标。我们还没有讲到的另一个因素是,Windows也使用这个数值来确定线程的时限是否已经结束-一这件事可能在时钟中断之前已经发生,并且,这是个重要的话题。
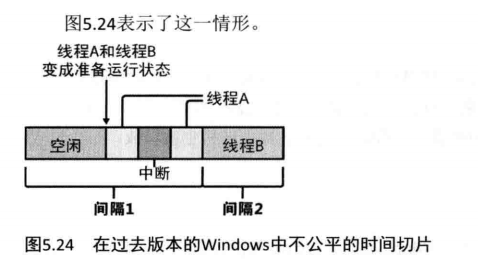
如果使用一个只依赖于时钟间隔定时器的调度模型的话,可能会产生下面的情形:
- 在一个时钟间隔的中间,线程A和线程B变成了准备运行的状态(调度代码不是只会在每次时钟间隔运行,所以这种情况会经常发生)。
- 线程A开始运行但被中断过一小会儿。处理中断的这段时间被记在了该线程的账上中断处理过程完成后,线程A重新开始运行,但它很快就遇到了下一个时钟间隔。调度器只能假设线程A在这段时间里都在运行,所以就切换到了线程B。
- 线程B开始运行,并有机会运行一个完整的时钟间隔(如果没有抢占或中断处理发生的话)。
在这一情形下,线程A被不公平地通过两种不同方式“惩罚”了两次。首先,为了处理一个设备中断,它所耗费的时间被记录在了它自己的CPU时间里,虽然这个线程很有可能和这个中断没有任何关系(请记住,中断被处理时的环境,是当时运行着的、无论哪一个线程的执行环境)。其次,在它被调度的那个时钟间隔里,调度之前的系统空闲时间也被不公平地拿来“惩罚”了它。
因为Windows保存了线程被调度以后真正要做的工作所花费的时钟周期数,而且是实际CPU时钟周期的准确计数(意味着去除了中断的开销),再加上Windows也保存了线程在时限结束时应该用掉的、以时钟周期为单位的时限目标,所以,前面所说的作用于线程A的两种不公平的调度决定,将不会在windows中发生。
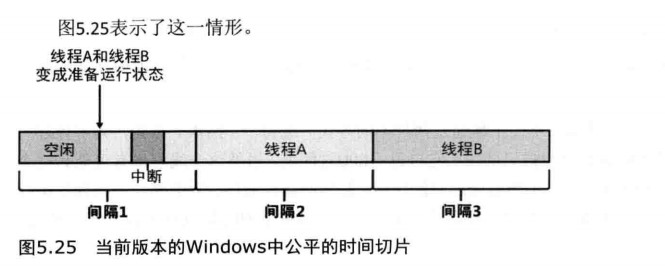
取而代之的是,下面的情况将会发生:
- Q在一个时钟间隔的中间,线程A和线程B变成了准备运行的状态。
- 线程A开始运行但被中断过一小会儿。处理中断所花费的CPU时钟周期数并没有被记在该线程的账上。
- 中断处理过程完成后,线程A重新开始运行,但它很快就遇到了下一个时钟间隔。调度器检查线程用掉的CPU时钟周期数,并把它与时限结束时期望用掉的CPU时钟周期数作比较。
- 因为前面的那个值比应该用掉的值小很多,所以,调度器假定线程A是在一个时钟间隔的中间开始运行的,可能还被中断过了。
- 线程A得到了又一个时钟间隔带来的时限增长,并且时限目标也被重新计算。线程A现在有机会运行一个完整的时钟间隔了。
- 在下一个时钟间隔,线程A已经完成了它的时限。线程B现在就有机会运行了
终止
当一个线程结束运行(或者因为它从主例程中返回了,或者因为调用了ExitThread,或者被通过TerminateThread杀掉了)时,它从运行状态被转移到终止状态。如果该线程对象上没有已打开的句柄,则从进程的线程列表中删除该线程,相关联的数据结构也被释放。
空闲(Idle)线程
当一个CPU上不存在可运行的线程时,Windows把执行权分发给该CPU的空闲线程。每个CPU都被分配了一个空闲线程,因为在一个多处理器系统上,当一个CPU正在执行某个线程的时候,另一个CPU可能没有线程要执行。
所有的空闲线程都属于空闲进程。空闲进程和空闲线程在很多情况下都是进程和线程的特例。当然,它们也是由EPROCESS/KPROCESS以及ETHREAD/KTHREAD表示的,但它们并不是扶行体管理器的进程和线程对象。空闲进程也不在系统的进程列表中(这就是为什么它不出现在内核调试器的!process00命令的输出中的原因)。然而,可以通过其他途径,来找到空闲线程以及它们的进程。
前面的实验显示了空闲进程以及它的线程的某些不规则性。调试器显示的“映像”名称为“idle”(它来自EPROCESS结构的imageFileName成员)但是Windows的各种实用工具使用了各式各样的名称来表示空闲进程。任务管理器和进程管理器把它称作“Systemldle Process”,而Tlist把它称作“Svstem Process”。它的进程ID和线程ID(调试器输出中的“cientiDs”或者“Cid”)是零,PEB和TEB指针也是零,而且空闲进程和线程中还有许多域可能被报告为零。这之所以发生是因为,空闲进程没有用户模式地址空间,并且它的线程不执行任何用户模式代码,所以它们都不需要用于管理用户模式环境的各种数据。此外,空闲进程也不是对象管理器的进程对象,它的空闲线程也不是对象管理器的线程对象。相反,初始的空闲线程和空闲进程结构都是静态分配的,并且在进程管理器和对象管理器初始化之前,被用于引导系统。后续的空闲线程结构是在系统将更多的处理器带上线时,动态分配的(简单地从非换页内存池中分配,绕过了对象管理器)。一旦进程管理初始化已完成,它就会用特殊的变量PsidleProcess来指
向空闲进程。也许,关于空闲进程的一个最有趣的与众不同之处,是Windows把空闲线程的优先级报告为0(x64系统上是16,如前面讲过的)。然而,实际上,空闲线程的优先级成员的值是没有意义的,因为这些线程只有在没有其他线程运行的时候才会被选中分发。它们的优先级从来不与任何其他线程比较,也从不根据优先级把一个空闲线程放到就绪队列中:空闲线程从来不是任何就绪队列的一部分(记住,每个Windows系统只有一个线程真正运行在优先级0上一-零页面线程,参见本书下册第10章中的解释)。
正如空闲线程对于“被选中执行”这一操作来说是个特例,对于抢占来说,它们也是个特例。空闲线程的例程KildleLoop会执行一系列操作,以避免它被另一个线程通过常见的方式抢占。在一个处理器上,当不存在非空闲的可运行线程时,那个处理器会在它自己的PRCB中被标记为“空闲”。然后,如果一个线程被选中在那个空闲处理器上执行,那么,该线程的地址会被保存在空闲处理器的PRCB的NextThread指针里。空闲线程在它的每一遍循环中都会检查这个指针。
虽然在不同的体系结构之间,细节流程可能有所不同,但是,空闲线程的基本操作步骤如
- 短时间内开启中断,以允许任何等待处理的中断被交付,然后再禁止中断(通过使用x86和x64处理器上的STI和CLI指令)。这是有必要的,因为空闲线程很大一部分的执行过程中,中断是关闭的。
- 在某些处理器体系结构的调试版本上,检查是否有内核调试器正在试图打断系统的执行,如果是,就给它这种类型的访问。
- 检查该处理器上是否有DPC(参见第3章的介绍)正在等待。如果DPC在入队列的时候DPC中断没有生成,那么该DPC就会等待。如果有DPC在等待,那么空闲循环就调用KiRetireDpcList来分发并处理它们。这也会执行定时器到期处理,以及进行延迟就绪的处理;关于后者,在后续的多处理器调度一节中会有解释。KiRetireDpcList必须在禁用中断的情况下进入,这也就是为什么中断在第一步的末尾被留置在禁用状态的原因。KiRetireDpcList退出时中断仍然被禁用
- 检查是否有一个线程被选中作为在该处理器上运行的下一个线程:如果有的话,分发该线程。这种情况的发生有几种可能性,例如,在第3步中处理的一个DPC或者定时器到期解除了一个线程的等待状态,或者,另一个处理器曾在它的空闲循环中,为当前处理器选择了一个线程来运行。
- 如果收到相关请求,就检查在其他处理器上就绪的线程,并且如果可能的话,把其中之一放在本地调度(在后续的“空闲调度器”一节中会解释这一操作)。
- 调用已注册的电源管理处理器空闲例程(如果存在任何电源管理功能需要被执行的话),它们或者存在于处理器的电源驱动程序(例如intelppm.sys)中,或者,如果这样的一个驱动程序不可用的话,存在于HAL中。
线程选择
当一个逻辑处理器需要选择下一个要运行的线程时,它会调用KiSelectNextThread调度器函数。这件事情会在好几种情况下发生:
- 发生了一次硬的亲和性改变,使得当前运行或备用的线程不再被允许在它之前选择的逻辑处理器上执行,从而该处理器必须选择另一个线程。
- 当前运行的线程到达了它的时限尾端,而且它运行所在的SMT集(SMT Set)现在已经变得忙碌了,而理想节点中的其他SMT集则是完全空闲的(SMT是Symmetric Multi.Threading(对称多线程)的缩写,是第2章中描述的Hyperthreading(超线程)技术的技术名称)。调度器给当前线程作时限结束时的转移,从而必须选择另一个线程。
- 一个等待操作已经完成,并且在等待状态寄存器里有待处理的调度操作(或者说优先级”位和/或“亲和性”位已被设置)。
在这些情形下,调度器的行为如下所示: - 调用KiSelectReadyThread来查找该处理器应该运行的下一个就绪线程,并检查是否真正找到了它。
如果没有找到就绪线程,就会启用空闲调度器,并选择空闲线程来执行
或者,找到了就绪线程,那么它就被设置为备用(Standby) 状态,并且设置为逻辑D处理器的KPRCB中的NextThread值。
只有在逻辑处理器需要选择(但还不是运行)下一个可调度的线程的时候,KiselectNextThread操作才会被执行(这就是那个线程会进入备用状态的原因)。然而,在其他情况下,逻辑处理器有兴趣马上运行下一个就绪线程,或者,如果就绪线程不可用的话,执行另一个动作(而不是进入空闲状态),比如,当下面的情况发生的时候:
- 发生了优先级的改变,使得当前处于备用状态或运行中的线程,不再是它被选中的逻辑处理器上优先级最高的就绪线程了,所以一个优先级更高的就绪线程现在必须运行。
线程通过调用YieldProcessor或NtYieldExecution,已经显式地放弃了CPU,而且另一个线程可能已经准备好运行了。 - 当前线程的时限已到期,并且同一优先级上的其他线程也需要得到它们的运行机会
- 一个线程失去了它的优先级提升,导致优先级的改变,这类似于前面讲的一种情况。
- 空闲调度器在运行,并且需要检查:在空闲调度被请求,直到空闲调度器运行的时间段中,是否还没有出现过就绪线程。
要想记住到底哪个例程是要运行的,一种简单的方法是:检查逻辑处理器是否必须运行个不同的线程(这种情况下KiSelectNextThread被调用),还是应该,只要可能的话,运行-个不同的线程(这种情况下KiSelectReadyThread被调用)
无论在哪种情况下,因为每个处理器都有它自己的数据库记录着准备运行的线程(也就是在KPRCB中,分发器数据库的多个就绪队列),KiSelectReadyThread可以只检查当前逻辑处理器的队列,移除它找到的第一个优先级最高的线程,除非这一优先级低于某个当前运行着的线程(依赖于当前线程是否还被允许运行,在KiSelectNextThread的场景下不会出现这种情况)。
如果没有优先级更高的线程(或者完全没有就绪的线程),就不返回任何线程。
空闲调度器
空闲线程一运行,就会检查空闲调度是否已经被启用,比如,可能由于上一节中讲到过的某个情形。如果是,空闲线程就调用KiSearchForNewThread,开始扫描其他处理器的就绪队列,寻找它可以运行的线程。注意这一操作的运行时开销并不被记作空闲线程的时间,而是被记作中断和DPC的时间(记在相关的处理器上),因此空闲调度的时间被认为是系统时间。KiSearchForNewThread算法是通过前面“线程选择”一节中见过的函数来实现的,它会在下-节中进一步解释。
多处理器系统
在一个单处理器系统上,调度过程相对比较简单:在所有想要运行的线程中,最高优先级的线程总是在运行。在一个多处理器系统上,调度过程要复杂得多,因为Windows试图将线程安排到对于它们来说最优的处理器上,它要考虑到线程的首选处理器、以前运行的处理器,以及多处理器系统的配置情况。因此,尽管Windows试图将那些最高优先级的可运行线程安排到所有可用的CPU上,但是,它只保证一个最高优先级的线程在某个处理器上运行。
我们在介绍“如何选择哪些线程在哪里、何时运行”的专门算法以前,先来看一看Windows维护了哪些额外的信息来记录多处理器系统中线程和处理器的状态,以及Windows支持的三种不同类型的多处理器系统(超线程、多核和NUMA)。
封装集和SMT集
面对逻辑处理器拓扑的情况,Windows使用KPRCB中的五个域来确定正确的调度决定。第一个域,CoresPerPhysicalProcessor,决定了该逻辑处理器是否属于一个多核封装,它根据处理器返回的CPUID计算得来,再取整为2的幂次。第二个域,LogicalProcessorsPerCore,决定了该逻辑处理器是否属于一个SMT集,例如在一个启用HyperThreading功能的英特尔处理器上,这也是从CPUID中查询并取整的。把这两个数字相乘,得到的是每个封装的逻辑处理器个数,或者说,在一个插口 (socket)上的物理处理器里面的逻辑处理器个数。有了这些数字以后,每个PRCB就能填入它的PackageProcessorSet值,这是一个亲和性掩码,描述了同一组(因为每个封装的范围都限定在一个组内)里其他逻辑处理器中的哪些是属于同一个物理处理器的。类似地,CoreProcessorSet值把同一核上的其他逻辑处理器连接起来,称为一个SMT集。最后,GroupSetMember值定义了当前处理器组中的哪个位掩码,标识了当前的这个逻辑处理器。例如,3号逻辑处理器通常会有一个值为8(23)的GroupSetMember成员。
NUMA系统
Windows支持的另一种类型的多处理器系统,是那些具有非一致内存访问(nonuniformmemoryaccess,NUMA)体系结构的多处理器系统。在一个NUMA系统中,处理器被组织成稍小一些的单元(称为节点)。每个节点有它自己的处理器和内存,它们通过一条具有统一缓存的互联总线连接到大系统中。这些系统之所以称为“非一致”的,是因为每个节点有它自己的局部高速内存。虽然任何节点上的任何一个处理器都可以访问所有的内存,但是,访问节点的局部内存要快得多。
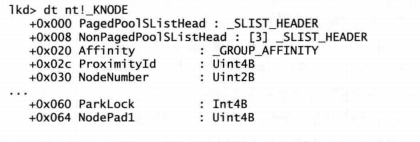
在一个NUMA系统中,内核把有关每个节点的信息保存在一个称为KNODE的数据结构中。内核变量KeNodeBlock是一个指针数组,其中的指针元素指向了每个节点的KNODE结构。在内核调试器中使用dt命令,可以显示KNODE结构的格式,如下所示:
如果应用程序想要在NUMA系统上获得最好的性能,则可以设置亲和性掩码,以限制一个进程只在一个特定节点中的处理器上运行。然而,由于Windows的调度算法能感知NUMA的存在,它已经把几乎所有的线程都限制在单个NUMA节点上了。
调度算法如何考虑NUMA系统呢?在接下来的“处理器的选择”一节中将会介绍(本书下册第10章还将介绍在内存管理器中,为了充分利用节点的局部内存所采取的一些优化手段)。
处理器组的分配
Windows会查询系统的拓扑结构,以建立逻辑处理器、SMT集、多核封装和物理插口间的各种关系。此时,Windows把各个处理器分配到一个合适的、能描述它们的亲和性的处理器组(通过前面讲过的扩展的亲和性掩码)。这一工作是由KePerformGroupConfiguration例程完成的,它会在第1阶段的初始化过程之中、任何其他工作完成之前被调用。注意,无关乎下面的分配组的步骤,任何情况下,NUMA节点0总是被分配到组0。
首先,函数查询所有被检测到的节点 (KeNumberNodes),并计算每个节点的容量 (即可以有多少逻辑处理器属于该节点)。这个值被保存在KeNodeBlock中的MaximumProcessors域标识着系统上所有的NUMA节点。如果系统支持NUMA近距ID 功能(NUMAProximityIDs),就为每个节点查询近距ID,并保存在节点块中。其次,分配NUMA距离数组 (KeNodeDistance),并按第3章描述的那样,计算每个NUMA节点间的距离。
下一系列的步骤要处理特定的用户配置选项,它们覆盖了默认的NUMA分配方案。例如,在一个安装有Hyper-V(并且其超级监督者 (hpervisor)被配置为自动启动)的系统上,只有一个处理器组将被启用,并且所有的NUMA节点 (大小能装得进去的)会被关联到组0。这意味着目前的Hyper-V场景还无法充分利用处理器个数在64个以上的机器。
下一步,该函数检查加载器是否传递了任何静态的组分配数据(因此,这可以由用户来配置)。这些数据指定了每个NUMA节点的近距信息和组的分配。
注 与大型的NUMA服务器打交道的用户,出于测试或验证的目的,可能需要自定义地控制近距信息和组的分配为此可以通过HKLM\SYSTEM\CurrentControlSet\ControNUMA注册表键的GroupAssignment和Node Distance注册表值,来输入这一数据。这一数据的准确格式包含一个计数值,后面跟着一个近距ID和组分配数据的数组,它们都是32位的值。
在把这一数据当作有效数据以前,内核会查询近距ID来匹配节点号,然后按照请求把组号关联好。然后,它确认NUMA节点0是关联到组0的,并且所有NUMA节点的容量与组的大小-致。最后,该函数会检查还有多少组有剩余容量。
接下来,如果已经通过我们前面描述的方式,传入了节点的静态配置,那么内核就会遵循这些配置,尝试动态地分配NUMA节点到各个组里。通常,内核会试着把创建的组的数量减到最小,在每个组中合并尽可能多的NUMA节点。然而,如果并不想要这一行为,也可以通过加载器参数/MAXGROUP来给它不同的配置,它可以通过BCD选项maxgroup来配置。打开了这个值以后,默认的行为将被覆盖,导致该算法把NUMA节点尽可能多地分散在尽可能多的组中(同时遵循当前实现的组限制为4)。如果只有一个节点,或者所有的节点能被放到一个组中(而且maxgroup是关着的),则系统会执行默认的设置,把所有的节点分配给组0.
如果有一个以上的节点,Windows会检查静态的NUMA节点距离(如果存在的话),并按节点的容量把所有节点排序,最大的节点排在前面。在组数量最小的模式下,内核计算所有容量的总和,以计算出可能的最多处理器的数量。把这个数除以每组的处理器数,内核就假定机器上总共会有这个数量的组(受最大值为4的限制)。在组数量最大的模式下,初始的估算是有多少节点就有多少组(仍然受最大值为4的限制)。
现在,内核开始最后的分配过程。所有之前确定下来的分配方案现在被提交,并且这些分配方案用到的组也被创建。下一步,所有的NUMA节点被重新打乱,以最小化同组内不同节点间的距离。换句话说,相对比较接近的节点被放在同一个组,并按距离排序。下一步,对所有动态配置的节点,也执行同样的组分配过程。最后,任何余下的空节点被分配到组0。
每个组中的逻辑处理器
通常情况下,如前面解释过的,Windows为每个组分配64个逻辑处理器,但是这个配置也可以通过使用不同的加载选项来自定义,例如/GROUPSIZE开关,它由BCD元素groupsize配置。通过指定2的某个暴次这样的数字,可以强制让组内包含的处理器数比通常情况少,这可以出于各种目的,例如,测试系统中的组感知度(举例来说,一个有8个逻辑处理器的系统可以被配置成有1个、2个或4个组)。为了强化这一问题,/FORCEGROUPAWARE选项(BCD元素groupaware)让内核尽可能地避开组0,把最高的可用组号,用于诸如线程及DPC的亲和性选择以及进程的组选择时的分配。请避免把组的容量设为1,因为这会强制系统上几乎所有的应用程序的行为看起来就像是在单处理器的机器上运行一样,因为对任一给定的进程,内核会默认把它的亲和性掩码设置成只有一个组,直到应用程序作出它自己的不同请求为止(而目前绝大多数应用程序还不会这么做)。
注意,在边界情况下,如果一个封装内的逻辑处理器太多无法装入单个组,那么Windows就调节相应的数值,从而使该封装放得进单独的一个组方法是把CoresPerPhysicalProcessor的数值减少:如果SMT也放不下的话,就也对LogicalProcessorsPerCore作同样的处理。对这一规则的一个例外是,该系统实际上有一个封装内包含了多个NUMA节点。虽然在写这本书时还不存在这种可能性,但未来的多芯片模块(Multiple-Chip Modules,MCMs,多核封装的扩展版本)将在不远的将来从处理器生产商那里发行。在这些模块中,两套核以及两个内存控制器会出现在同一个晶粒或封装内。如果ACPI的SRAT表把该MCM定义成“有两个NUMA节点”,那么根据组配置算法,Windows可能把这两个节点关联到两个不同的组。在这一情形下,该MCM封装将会跨越多于一个的组。
除了导致重要的驱动程序和应用程序兼容性问题以外(其设计目的就是为了让开发人员使用它们,来识别这些问题并找出其根源),这些选项对机器来说还有着更大的影响:即便是一台非NUMA的机器,它们也会强制NUMA的行为。这是因为,正如分配算法中所展示的那样,Windows从来不让一个NUMA节点跨越多个组。所以,当内核在创建人为配置的很小的组时这两个组就必须拥有各自的NUMA节点。例如,对于一个四核处理器,假定组的大小为2,就会有两个组被创建,从而有两个NUMA节点,它们将是主节点的两个子节点。这将影响调度和内存管理的策略,就如同在一个真正的NUMA系统中那样,因此对于测试会比较有用。
逻辑处理器的状态
除了就绪队列和就绪摘要以外,Windows还维护了两个位掩码,用于跟踪系统中处理器的状态(在下一节“处理器的选择”中将解释这些位掩码是如何被使用的)。下面的文字描述了这两个Windows维护的位掩码。
第一个掩码是“活动处理器”掩码 (KeAtiveProcessors),它为系统上每一个可用的处理器设置一个对应的二进制位。这可能比实际的处理器数量要少,如果正在运行的Windows版本的许可证限制所支持的处理器个数低于可用的物理处理器个数的话。要检查这一点,可以使用变量KeRegisteredProcessors,以得到机器上实际许可的处理器数量。这里变量名中的“processors”,指的是物理的处理器封装。另一方面,KeMaximumProcessors变量指的则是逻辑处理器的最大数量,包括所有将来可能动态添加的处理器,再与许可证限制,以及通过调用HAL层、检查ACPI的SRAT表等方法查询得到的任何平台上的限制(如果有的话),放在一起取最小值。
空闲摘要(KildleSummary)实际上是两个扩展的位掩码组成的数组。在第一个项(称为CpuSet)中,每个值为1的位代表一个空闲的处理器;而在第二个项,SMTSet中,每个位描述了一个空闲的SMT集。
未停运摘要(KiNonParkedSummary)的每个位定义了一个未停运的逻辑处理器
调度器的可伸缩性
因为在一个多处理器的系统上,一个处理器可能需要修改另一个处理器的每CPU(per-CPU)调度数据结构(例如,在某个处理器上插入一个想要运行的线程),所以,需要使用针对每个PRCB的排队自旋锁来同步这些结构,持有该锁的中断请求级别是DISPATCH_LEVEL。这样一来只锁定单个处理器的PRCB,也能做线程选择。如果有必要,也可以同时锁定另一个处理器的PRCB,例如,在线程重分配 (thread stealing)的情形下,后面会描述它。线程的环境切换也是通过一个更细粒度的针对每个线程的自旋锁来同步的。
也有一个针对每个CPU的处于延迟就绪状态的线程列表。它们代表准备好运行,但还没有被系统准备好执行的线程:实际的就绪操作被延迟到一个更合适的时间。因为每个处理器只操作它自己的延迟就绪列表,所以,这个列表并不通过PRCB自旋锁来同步。延迟就绪线程列表是由KiProcessDeferredReadyList来处理的,这发生在一个函数已经完成进程或线程的亲和性优先级(包括由优先级提升引起的)、时限值等修改以后。
该函数为列表上的每个线程调用KiDeferredReadyThread,而它会执行后面“处理器的选择一节中演示的算法。这一算法或者会让线程立即运行:或把它放进处理器的就绪列表:或者,若当前处理器不可用,则把线程放进另一个处理器的延迟就绪列表,它会处于备用状态,或者被立即执行。这一特性是在停运一个处理器核的时候,由核停运引擎(Core Parkingengine)使用的:所有的线程都被放入延迟就绪列表,然后再被处理。因为KiDeferredReadvThread会群过被停运的核(将会讲到这一点),它会导致该处理器上所有的线程都被移走到其他的处理器te
亲和性
每个线程都有一个亲和性掩码,它指定了该线程只允许在哪些处理器上才可以运行。线程亲和性掩码是从进程的亲和性掩码继承过来的。在默认情况下,所有的进程(因而也是所有的线程)的起始亲和性掩码都等于它们被分配到的处理器组中活动处理器的集合。换句话说,系统可以自由地在进程所关联的组中任何可用的处理器上调度所有的线程。然而,为了优化总吞吐量,以及/或者将工作负载分布到特定的处理器集合上,应用程序可以选择改变一个线程的亲和性掩码。这可以在以下几个不同的层次上完成。
调用SetThreadAffinityMask函数,为单独的线程设置亲和性。
调用SetProcessAffinityMask函数,为一个进程中的所有线程设置亲和性。任务管理器和进程管理器为这个函数提供了GUI界面:你只要右键单击一个进程,并选择SetAffinity。Psexec工具(来自Sysinternals)为这一函数提供了命令行界面(参见它的帮输出中的-a开关)。
让一个进程成为一个作业的成员。对于作业对象,通过SetlnformationJobobject函数,它可以有一个作业范围内的亲和性掩码(在本章后面的“作业对象”一节中介绍了作业)。
编译应用程序时,在映像头部指定一个亲和性掩码(有关Windows映像的细节格式的更多信息,请在www.microsoftcom上搜索“Portable Executable and Common ObjectFile Format Specification”)
在链接时,你也可以为一个映像设置“uniprocessor(单处理器)”标志。如果该标志被设置的话,则系统在创建进程的时候选择一个处理器(MmRotatingProcessorNumber),并以此作为该进程的亲和性掩码:系统从第一个处理器开始分配,然后通过轮循的方法遍历组里所有的处理器。例如,在一个双处理器系统上,当你第一次运行一个被标记为单处理器的映像时它被分配给CPU0:第二次,分配CPU1: 第三次,分配CPUO: 第四次,分配CPU1: 依此类推。对于那些有多线程同步错误(因为竞争条件而引起的错误,在多处理器系统上会出现,但是在单处理器系统上不会发生)的程序,这一标志可以被用做一种临时的解决方案。如果一个映像出现这样的症状,并且它没有被数字签名,那么,该标志可以手动地添加,做法是,使用诸如imagecfg.exe这样的工具来编辑映像头部。一个更好的、同时也兼容于有签名的可执行文件的解决方案是使用Microsoft应用程序兼容性工具箱 (Application Compatibility Toolkit)并添加一个兼容性铺垫,以强制兼容性数据库将该映像标记为仅运行于单处理器的模式。
假设一个线程正在一个CPU上运行,它也可以到别的处理器上运行,而另一个线程的亲和性设置限定了它只能在第一个CPU上运行,那么,Windows不会将第一个线程移到第二个处理器上,以便让第二个线程到第一个CPU上运行。例如,考虑这样的情形:CPU O正在运行一个优先级为8的线程,该线程可以在任何一个处理器上运行;而CPU1正在运行一个优先级为4的线程,它也可以在任何一个处理器上运行。另有一个优先级为6的线程只能在CPUO上运行,它现在进入就绪状态那会怎么样呢? Windows不会将优先级为8的线程从CPUO移到CPU1上(抢占优先级为4的线程),以便让优先级为6的线程可以运行:相反,优先级为6的线程必须等待。因此,改变一个进程或者一个线程的亲和性掩码可能会导致这些线程得到比在正常情况下更少的CPU时间,因为Windows被限制了,不允许其在某些特定的处理器上运行此线程。因此,设置亲和性必须非常小心一一在大多数情况下,让Windows来决定在哪些CPU上运行哪些线程是最佳的做法。
扩展的亲和性掩码
为了支持超过64个处理器,也就要突破亲和性掩码结构(在64位系统上由64个位组成)强加的限制,Windows采用了一个扩展的亲和性掩码(KAFFINITY EX)它是一个亲和性掩码组成的数组,每个受支持的处理器组(目前定义为4个)都对应其中一个元素。当调度器需要在扩展的亲和性掩码中引用一个处理器时,它首先通过处理器的组号找到正确的掩码,然后直接访问要查找的亲和性。在内核API中,扩展的亲和性掩码是不暴露出来的;相反地,API的调用者把组号作为参数传入,并接收针对该组的传统的亲和性掩码。另一方面,在Windows API中,通常只能查询关于单个组的信息,也就是当前运行着的线程所在的那个组(它是不变的)。如果一个进程不想受初始时分配给它的处理器组的限制,而想跨越组的边界,则也需要用到扩展的亲和性掩码以及它的底层功能。通过使用扩展的亲和性AP1,一个进程中的线程可以选择其他处理器组上的亲和性掩码。举例来说,如果一个进程有4个线程,并且机器有256个处理器,那么,只要每个线程在组0、1、2、3上设置值为0x10(二进制值0b10000)的亲和性掩码,则线程1可以运行在处理器4上,线程2可以运行在处理器68上,线程3在处理器132上,而线程4在处理器196上。或者,每个线程可以在它们指定的组设置值为OXFFFFFFFF的亲和性从而整个进程可以在系统上所有可用的处理器上运行(有一个限制,就是每个线程只能在它自己的组里运行)。
要利用扩展的亲和性,必须在创建的时候完成,做法是,在创建一个新线程的时候,在线程属性列表中指定一个组号(可参考前面有关线程创建的主题,以得到有关属性列表的更多信息)。
系统的亲和性掩码
由于Windows驱动程序通常在调用者线程的环境,或是任意线程的环境中执行(也就是说不是在ystem进程的安全界限之内),当前运行着的驱动程序代码可能受限于应用程序开发人员设定的亲和性规则;这些规则并不与驱动程序的代码相关,而且甚至可能导致中断和其他入队列的工作无法被正确地处理。因此,驱动程序开发人员可以通过下列AP:KeSetSystemAffinityThread(Ex)/KeSetSystemGroupAffinityThread和KeRevertToUserAffinityThread(Ex/KeRevertToUserGroupAfinityThread,利用一个系统机制来临时地忽略用户模式的线程亲和性设置。
理想处理器和上一个处理器
每个线程在内核线程控制块中保存了三个CPU编号:
- 理想处理器,或者,该线程应该运行于其上的首选处理器。
- 上一个处理器,或者,该线程最近一次运行时所在的处理器
- 下一个处理器,或者,该线程将运行在或已经运行在其上的处理器
一个线程的理想处理器是在该线程被创建时,利用进程控制块中的一个种子来选定的。每次当一个线程被创建时,该种子就会被递增,所以,一个进程中的每个新线程的理想处理器会循环经历当前系统上所有可用的处理器。例如,系统中第一个进程的第一个线程被分配的理想处理器是0,该进程中的第二个线程被分配到1号理想处理器。然而,系统中下一个进程的第一个线程的理想处理器被设置为1,第二个被设置为2,以此类推。通过这种方式,每个进程内的线程被散布在这些处理器上。
注意,这种分配方法假定了,一个进程内的线程完成的是等量的工作。在一个多线程进程中,这往往是不成立的,通常的模式是,由一个或者多个线程做事务管理工作,其他另有一组工作者线程。因此,一个多线程应用程序想要充分利用底层平台的优势,可能会发现,利用SetThreadldealProcessor函数来为它的线程指定理想处理器编号是很有用的。若要利用多个处理器组的话,开发人员则应当调用SetThreadidealProcessorEx(而不是前面讲的函数),它允许为亲和性选择一个组号。
64位Windows使用KPRCB中的Stride(大步)域来平衡地分配一个进程中新创建的线程。这“大步”是一个标量数值,代表了一个给定的NUMA节点中为了得到下一个独立的逻辑处理器分段,所要跳过的亲和性二进制位数,这里“独立”指的是另一个核(如果是在一个SMT系统中的话)或是另一个封装(如果是在一个非SMT的多核系统中的话)。由于32位Windows不支持大型的处理器配置系统,它不使用“大步”,而只是简单地选择下一个处理器编号,试若尽可能地避免共享同一个SMT集。例如,在一台双处理器的SMT系统上,它共有四个逻辑处理器,如果第一个线程的理想处理器被分配为逻辑处理器0,则第二个线程将被分配为逻辑处理器2,第三个线程为逻辑处理器1,第四个线程为逻辑处理器3,以此类推。按照这种方式,这些线程被均匀地散布在物理处理器上。
理想节点
在NUMA系统上,当一个进程被创建的时候,该进程的理想节点即被选出来。第一个进程被分配到节点0,第二个进程被分配到节点1,以此类推。然后,进程中的线程的理想处理器又是从相应进程的理想节点中选择出来的。一个进程中的第一个线程的理想处理器被分配为相应节点中的第一个处理器。在具有相同理想节点的进程中,随着越来越多的线程被创建,节点中的下一个处理器被用做下一个线程的理想处理器,如此类推下去。
多处理器系统上的线程选择
在更详细地讲述多处理器系统以前,我应该先总结一下“线程选择”一节中讨论过的算法。它们或者继续执行当前的线程(如果没有找到新的候选的话),或者开始运行空闲线程(如果当前的线程必须被阻塞的话)。然而,还有第三个线程选择算法,它其实在前面的“空闲调度器”一节中被暗示过,称为KiSearchForNewThread。这个算法在一个特定的场合下被调用当前线程由于等待一个对象而被阻塞,包括在进行NtDelayExecutionThread调用的时候(即Windows中的Sleep API)。
注:这显示了常用的Sleep(1)调用和SwitchToThread调用之间的微妙区别;前者把当前线程阻塞,直到下一个定时器嘀嗒为止,而后者则采取前面演示过的行为《指前面讲过的KiSelectReadyThread或是KiSelectNextThread的做法一-译者注)。Sleep使用的算法后面会讲而“放弃执行(yield)”则使用前面演示过的逻辑。
KiSearchForNewThread初始时检查当前处理器是否已经选中了一个线程(通过读取NextThread域);如果是这样,它立即分发这个线程,让它进入“运行”状态。否则,它调用KiSelectReadyThread例程,若找到线程,则执行同样的步骤。
然而,如果没有找到任何线程,则处理器会被标记为空闲(即使空闲线程还没有开始运行也是如此),并且系统将启动一个对其他逻辑处理器上队列的扫描(不像其他标准算法,这个时候就会放弃)。而且,因为处理器现在被认为是空闲的,如果分布式公平份额调度模式(DistributedFairShareSchedulingmode,将在下一个主题中介绍)已启用,那么,只要可能的话,就会从“仅空闲时运行(idle-only)”的队列中释放一个线程并调度它。另一方面,如果处理器核现在已经被停运,那么该算法将不再试着检查其他的逻辑处理器,因为,相对于给它新的工作,让它不能空闲下来而言,允许该核进入停运状态是更好的选择。
如果这两种情况都不成立,那么工作重分配(work-stealing)循环现在运行。这段代码会检查当前的NUMA节点并移除任何空闲的处理器(因为它们不会包含需要重新分配的线程)。
然后,从最高编号的处理器开始,循环调用KiFindReadyThread,但将它指向远程的KPRCB,而不是当前这个,从而让当前处理器从另一个处理器的队列中找到最合适的就绪线程。如果这操作不成功,并且分布式公平份额调度器已启用,那么就会从远程逻辑处理器的“只在空闲时运行”的队列中释放一个线程到当前处理器上,若这样做可行的话。
如果没有找到候选的就绪线程,就尝试下一个编号较小的逻辑处理器,以此类推,直到当前NUMA节点上所有的逻辑处理器都已被穷尽。在此情况下,算法继续寻找下一个距离最近的节点,以此类推,直到当前组里所有的节点都被穷尽(还记得吗,Windows允许一个线程的亲和性只在单个组的范围内)。如果这一过程无法找到任何候选,那么函数将返回NULL,并且在此前线程进入等待的情况下,处理器将进入空闲线程(跳过空闲调度)。如果这一工作已经由空闲调度器完成,则处理器进入睡眠状态
处理器的选择
到现在为止,我们已经描述了当逻辑处理器需要选择一个线程时(或者,当必须为某个逻辑处理器选择一个线程的时候),Windows是如何去选择的,并假定了各种调度例程有一个现成的就绪数据库,可以从中选择线程。现在我们来看看这个数据库首先是怎样被填充的一-换句话说,给出一个就绪线程,Windows如何选择哪些逻辑处理器的就绪队列来关联它。既然已经讲过了Windows支持的多处理器系统的各种类型,以及线程亲和性与理想处理器的设置,有了这些准备,我们就能够检验这些信息是如何被用来完成这一任务了。
当存在空闲处理器时,为一个线程选择一个处理器
当一个线程准备好运行时,KiDeferredReadyThread调度器函数会被调用,这会让Window做两件事:根据需要调节优先级并刷新时限,就像前面在“优先级提升”一节中解释的那样,然后,为线程选择最佳的逻辑处理器。Windows首先查找线程的理想处理器,然后计算出在线程的硬亲和性掩码范围内所有空闲处理器的集合。接着,按下面讲的方法修剪这一集合:任何空闲的逻辑处理器,只要被核停运机制停运了,就被移除。(有关处理器核停运的更多信息,请参见本书下册第9章“存储管理“。如果这一步之后没有空闲处理器留下,则放弃对空闲处理器的选择,并且调度器的行为就像没有找到空闲处理器一样(在下一节就会讲到这一情形)。
0任何空闲的逻辑处理器,只要不在理想节点(被定义为“含有理想处理器的那个节点”)上,就被移除,除非这样做会导致所有的空闲处理器都被移除。在一个SMT系统上,任何非空闲的SMT集被移除,即使这样做可能会移除理想处理器它自己。换句话说,相对于理想处理器,Windows更倾向于一个非理想,但却是空闲的SMT集。
然后,Windows检查理想处理器是否存在于现在剩下的空闲处理器集合中。如果它不在其中,Windows必须找到最合适的空闲处理器。为此,它首先检查该线程上次运行所在的处理器是否属于剩余的空闲处理器集合。如果是,该处理器就被认作一个临时的理想处理器而选上。(还记得吗,理想处理器的设定是为了最大化处理器缓存命中率,而选择线程上次运行所在的处理器正是达到这个目标的好办法。
9如果上一次运行所在的处理器不属于剩余的空闲集合,Windows下一步将检查当前的处理器(也就是当前执行这段调度器代码的处理器)是否属于这一集合:如果是它就应用和上一步相同的逻辑。
如果“上次”处理器和当前的处理器都不空闲,Windows再执行一次修剪操作,对空闲的逻辑处理器,只要不在理想处理器所在的SMT集中,就把它移除。如果没有剩下的,Windows重新来一次,把不在当前处理器所在的SMT集中的空闲处理器都移除,除非这样做也移除了所有空闲处理器。换句话说,Windows首先考虑与那个不可用的理想处理器,和/或“上次”处理器共享着同一个SMT集的空闲处理器,来作为优先选择的对象。因为SMT的实现都共享了核上的缓存,所以,从缓存的角度看,这样做的效果几乎等于选择了理想的或上次的处理器。
g最后,如果上一步操作以后,留在空闲集合里的处理器超过一个,那么,Windows将选择编号最低的处理器作为线程的当前处理器。
一旦一个处理器被选中来运行该线程,该线程即被设为备用状态,并且空闲处理器的PRCB被更新以指向该线程。如果处理器是空闲的,但没有被暂停(halted),就会有一个DPC中断发送给它,让处理器能够马上处理这个调度操作。
每当上述调度操作被发起时,KiCheckForThreadDispatch被调用,它会意识到处理器上有一个新线程被调度了,并在可能的情况下,马上作一个环境切换(以及分发待处理的APC),或者它会发送一个DPC中断。
当没有空闲处理器时,为一个线程选择一个处理器
如果当一个线程想要运行时,没有空闲的处理器,或者,仅有的空闲处理器已经被第一轮修剪(它排除了已停运的空闲处理器)移除了,那么,Windows首先检查是否发生了第二种情形。如果是这一情形,调度器将调用KiSelectCandidateProcessor来查询核停运引擎,以获得最佳的候选处理器。核停运引警会选择理想节点中没有停运的处理器中编号最高的处理器。如果没有这样的处理器,引擎会强制改变理想处理器的停运状态,将它启运。在返回调度器后,它会检查它接收到的候选者是否空闲:如果是,它将为线程选择该处理器,其做法符合上一种情形中最后的一些步骤。
如果这不成功,Windows比较被调度线程的理想处理器上运行着(或处于备用状态中)的线程的优先级,以确定它是否应该抢占那个线程。
如果该线程的理想处理器已经有一个线程被选出来,并将在其上运行(在备用[standby]状态等着被调度),而且这个线程的优先级低于新的准备要执行的线程的优先级,那么,新线程把前一个线程从备用状态中抢占过来,变成该CPU的下一个线程。如果该CPU上已经有一个线程在运行了,则Windows检查当前正在运行的线程的优先级是否低于新的准备要执行的线程。如果是的话,则当前运行的线程被标记为已被抢占,Windows将一个DPC中断插入到目标处理器的队列中,以便抢占当前正在运行的线程,支持这个新线程。
如果已就绪的线程不能被立即运行的话,那么,它被移到适合它的线程优先级的优先级队列中,在那里等着轮到它运行。就像前面的调度情形里见到的那样,该线程将被插入到队列的头或尾,取决于它是否因为抢占而进入了就绪状态。
事实上,无论下层的情形和各种可能情况,注意,线程总是被放在其理想处理器的就绪队列中(每个处理器都有自己独立的就绪队列),以保证那些要判断逻辑处理器如何选择一个线程来运行的算法的一致性。
5.8 基于处理器份额的调度
5.9 动态的处理器添加与更换
5.10 作业对象
实验
- 实验:显示一个EPROCESS结构和域的格式
- 实验:使用内核调试器的!process命令
- 实验:检查PEB
- 实验:查看CSR_PROCESS
- 实验:查看W32PROCESS
- 实验:显示ETHREAD和KTHREAD结构
- 实验:使用内核调试器的!thread命令
- 实验:查看线程信息
- 实验:检查TEB
- 实验:检查CSRTHREAD
- 实验:检查W32THREAD
- 实验:查看受保护进程的线程信息
- 实验:查看就绪的线程
- 实验:检查并指定进程和线程的优先级
- 实验:线程调度状态的改变
- 实验:确定时钟间隔频率
- 实验:确定每个时限的时钟周期数
- 实验:修改时限配置的效果
- 实验:观察前台优先级提升和减退
- 实验:观察GUI线程上的优先级提升
- 实验:观察因CPU饥饿而引起的优先级提升
- 实验:“监听”优先级提升
- 实验:“监听”MMCSS的优先级提升
- 实验:显示空闲线程和空闲进程的结构
- 实验:查看逻辑处理器信息
- 实验:查看和改变进程的亲和性
总结
以上就是今天要讲的内容,本文仅仅简单介绍了linux命令行的使用。
参考:
shells 概念
centOS7中的几个Ctrl+组合键
关于博主
wx/qq:binary-monster/1113673178
wxgzh: 二进制怪兽
CSDN:https://blog.csdn.net/qq1113673178
码云:https://gitee.com/shiver
Github: https://github.com/ShiverZm
个人博客:www.shiver.fun



















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











